
LatentSync ist ein hochmodernes End-to-End Lip Sync-Framework, das die Kraft von audio-konditionierten latenten Diffusionsmodellen für die realistische Lip Sync-Generierung nutzt. Was LatentSync auszeichnet, ist seine Fähigkeit, die komplexen Korrelationen zwischen Audio- und visuellen Komponenten direkt zu modellieren, ohne auf eine Zwischenbewegungsdarstellung angewiesen zu sein, und revolutioniert damit den Ansatz der Lip Sync-Synthese.
Im Kern der LatentSync-Pipeline steht die Integration von Stable Diffusion, einem leistungsstarken generativen Modell, das für seine außergewöhnliche Fähigkeit bekannt ist, qualitativ hochwertige Bilder zu erfassen und zu erzeugen. Durch die Nutzung der Fähigkeiten von Stable Diffusion kann LatentSync effektiv die komplexen Dynamiken zwischen Sprach-Audio und den entsprechenden Lippenbewegungen lernen und reproduzieren, was zu hochpräzisen und überzeugenden Lip Sync-Animationen führt.
Eine der größten Herausforderungen bei diffusionsbasierten Lip Sync-Methoden ist die Aufrechterhaltung der zeitlichen Konsistenz über die generierten Frames hinweg, was für realistische Ergebnisse entscheidend ist. LatentSync geht dieses Problem mit seinem bahnbrechenden Temporal REPresentation Alignment (TREPA)-Modul an, das speziell zur Verbesserung der zeitlichen Kohärenz von Lip Sync-Animationen entwickelt wurde. TREPA setzt fortschrittliche Techniken ein, um zeitliche Repräsentationen aus den generierten Frames mit großen selbstüberwachten Videomodellen zu extrahieren. Indem diese Repräsentationen mit den Ground-Truth-Frames ausgerichtet werden, stellt das LatentSync-Framework ein hohes Maß an zeitlicher Kohärenz sicher, was zu bemerkenswert flüssigen und überzeugenden Lip Sync-Animationen führt, die eng mit dem Audioeingang übereinstimmen.
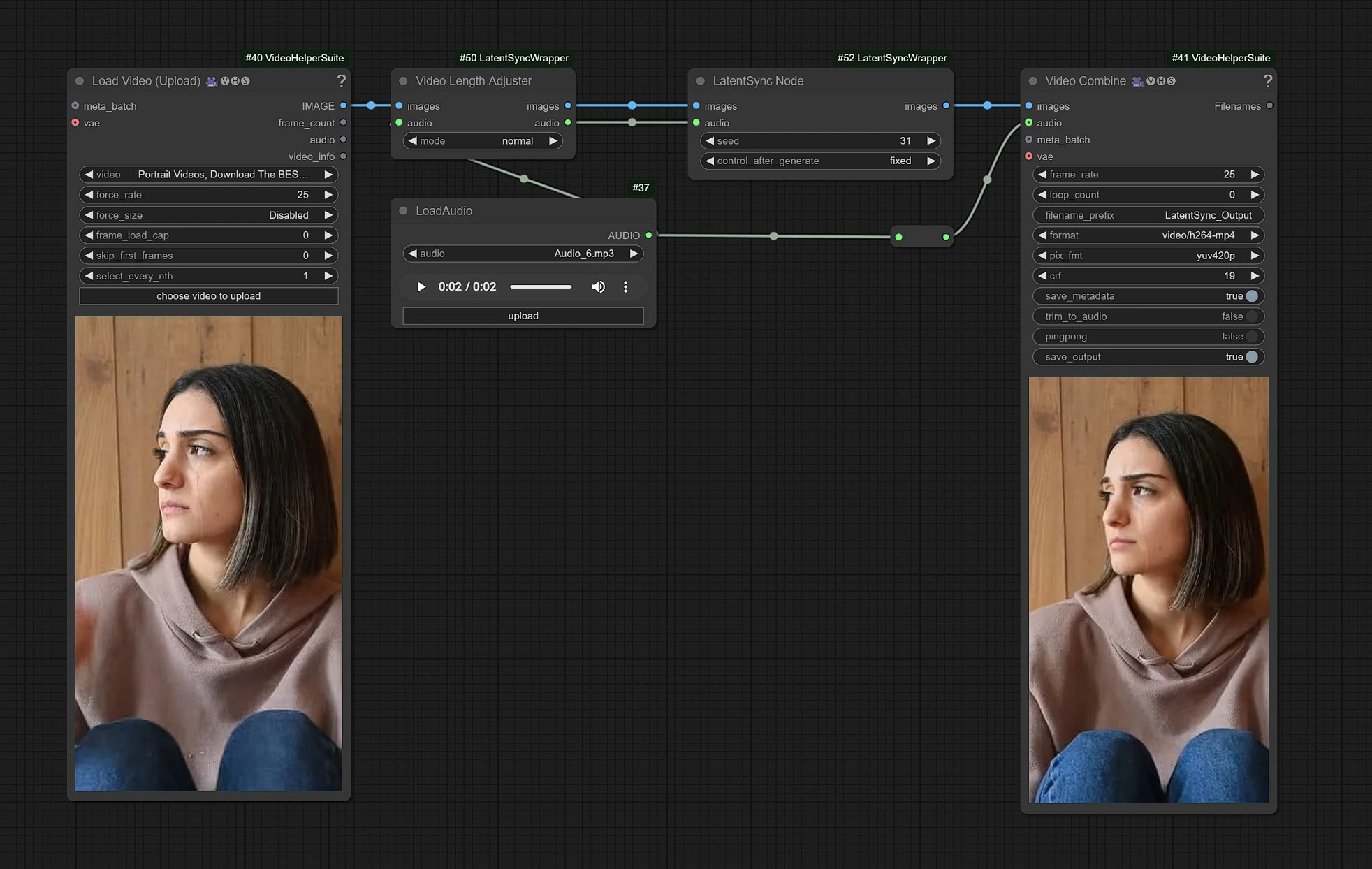
1.1 Wie verwendet man den LatentSync-Workflow?#
Dies ist der LatentSync-Workflow, die linken Knoten sind Eingaben zum Hochladen von Videos, die Mitte ist die Verarbeitung der LatentSync-Knoten, und rechts sind die Ausgabeknoten.
- Laden Sie Ihr Video in den Eingabeknoten hoch.
- Laden Sie Ihr Audioeingang der Dialoge hoch.
- Klicken Sie auf Rendern!!!
1.2 Videoeingang#
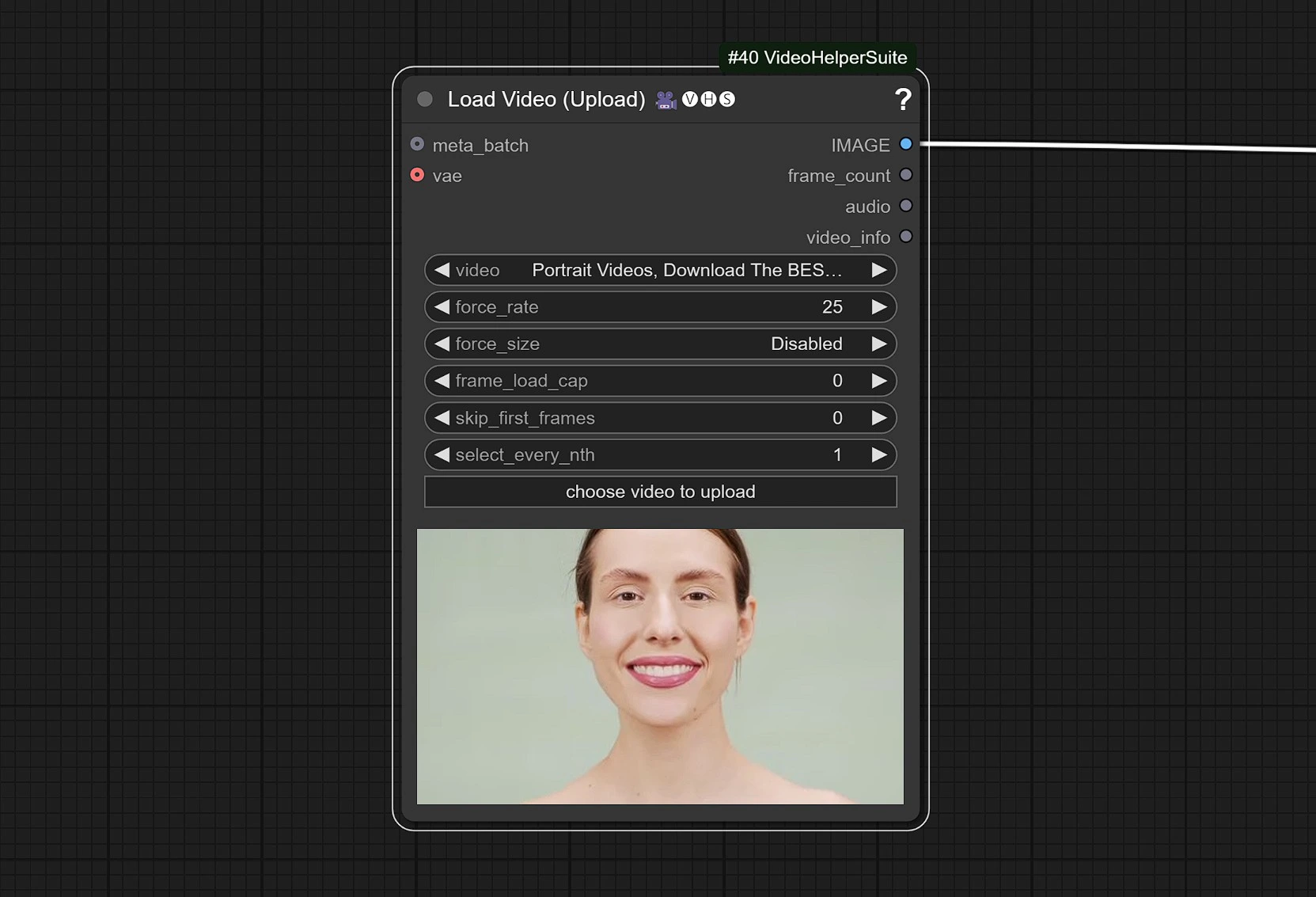
- Klicken und laden Sie Ihr Referenzvideo hoch, das ein Gesicht enthält.
Das Video wird auf 25 FPS angepasst, um ordnungsgemäß mit dem Audiomodell zu synchronisieren.
1.3 Audioeingang#
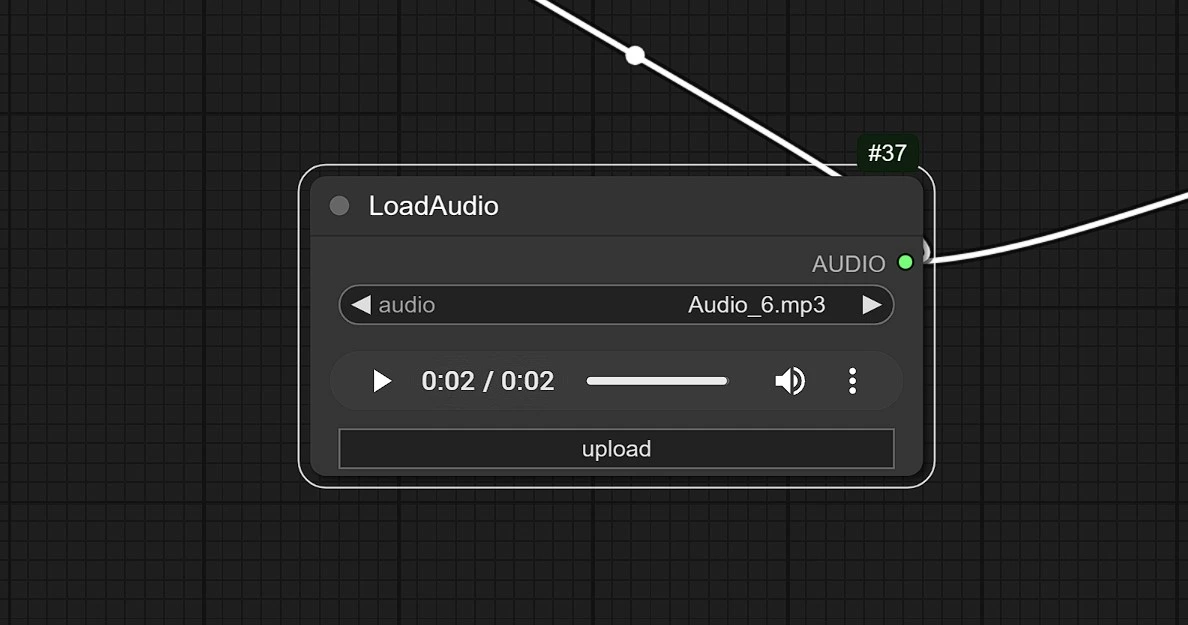
- Klicken und laden Sie Ihr Audio hier hoch.
LatentSync setzt einen neuen Maßstab für Lip Sync mit seinem innovativen Ansatz zur audio-visuellen Generierung. Durch die Kombination von Präzision, zeitlicher Konsistenz und der Kraft von Stable Diffusion transformiert LatentSync die Art und Weise, wie wir synchronisierten Inhalt erstellen. Definieren Sie mit LatentSync neu, was im Lip Sync möglich ist.

