
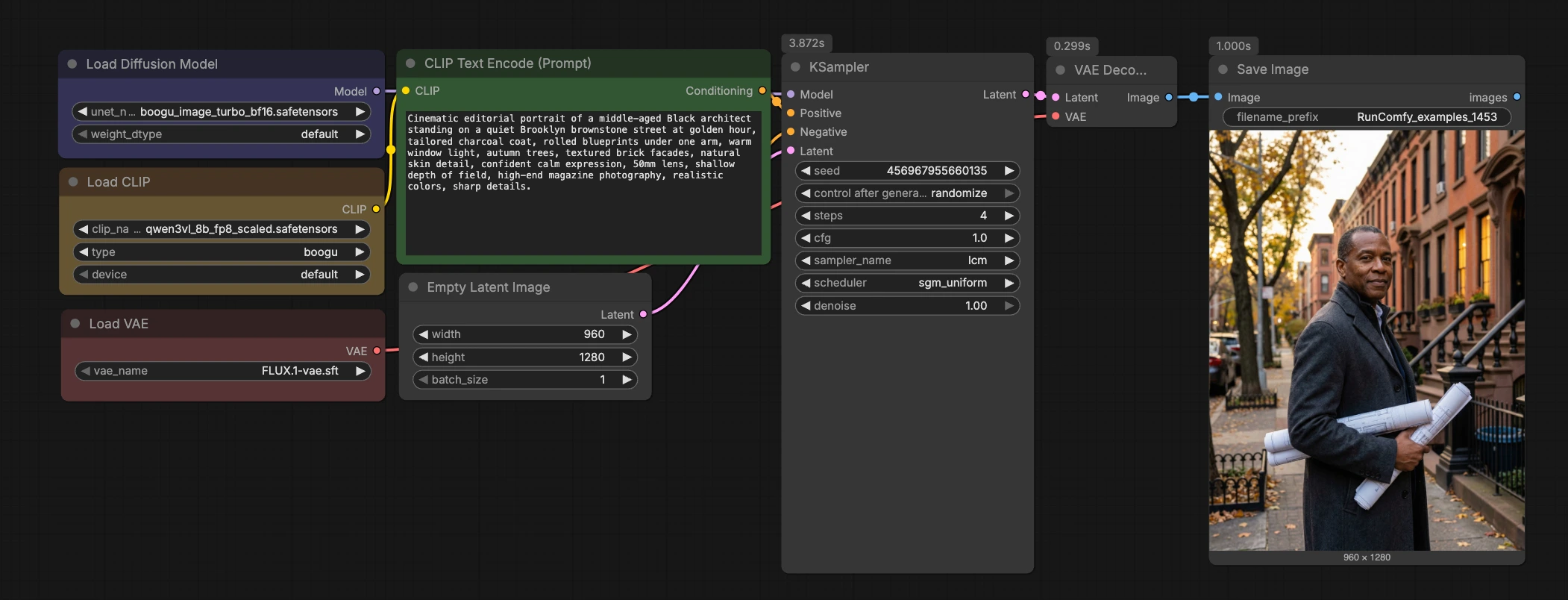






Boogu Turbo text-to-image ComfyUI Workflow#
Dieser Boogu Turbo text-to-image ComfyUI Workflow ist ein sauberer, schneller Weg vom Prompt zum Bild unter Verwendung des Boogu-Image-0.1-Turbo-Checkpoints mit vierstufigem LCM-Sampling. Er kombiniert den Qwen3-VL Text-Encoder mit dem FLUX.1 VAE, sodass Sie schnell iterieren können, während der Graph minimal bleibt und leicht über Projekte hinweg wiederverwendbar ist.
Entwickelt für schnelle visuelle Erkundung, glänzt der Workflow in filmischen Umgebungen, Anime-Stil-Hintergründen, atmosphärischen Landschaften, fantasievollen Produktmaschinen und architektonischen Szenen. Wenn Sie einen leichten Boogu Turbo text-to-image ComfyUI Workflow suchen, der RunComfy-fähig und einfach zu inspizieren ist, ist diese Vorlage ein starker Ausgangspunkt.
Schlüsselfaktoren im Comfyui Boogu Turbo text-to-image ComfyUI Workflow#
- Boogu-Image-0.1-Turbo. Die destillierte Turbo-Variante ist für schnelle, fotorealistische text-to-image mit typischen 3–4 Schritt-Inferenzen und einem Guidance-Scale nahe 1.0 gebaut. Offizielle Modellgewichte und Anleitungen sind auf Hugging Face verfügbar, mit ComfyUI-fähigen verpackten Dateien von Comfy-Org. Siehe Boogu/Boogu-Image-0.1-Turbo-fp8 und das kuratierte ComfyUI-Paket bei Comfy-Org/Boogu-Image.
- Qwen3-VL 8B Text-Encoder. Dieses moderne Vision-Language-Backbone wird hier rein als Text-Encoder genutzt, um starke Prompt-Embeddings für das Diffusionsmodell zu erzeugen. Die ComfyUI-verpackten Encoder sind bei Comfy-Org/Qwen3-VL gehostet und das offizielle Repository ist QwenLM/Qwen3-VL.
- FLUX.1 VAE. Der Autoencoder von Black Forest Labs kodiert und dekodiert Bilder zwischen Pixel- und Latentraum, um Farb- und Kontrasttreue zu bewahren. Referenzgewichte und Dokumentation sind bei black-forest-labs/FLUX.1-dev.
So verwenden Sie den Comfyui Boogu Turbo text-to-image ComfyUI Workflow#
Auf einen Blick codiert der Workflow Ihren Prompt, initialisiert eine latente Leinwand, führt einen schnellen LCM-Sampler durch Boogu-Image-0.1-Turbo aus, dekodiert mit dem FLUX.1 VAE, und speichert das Ergebnis. Der Graph ist absichtlich kompakt, sodass Sie ihn in andere Projekte einfügen oder ihn mit LoRAs, ControlNets oder Nachbearbeitungsketten erweitern können.
Prompt-Codierung mit Qwen3-VL (CLIPLoader (#7) → CLIPTextEncode (#11))#
In dieser Phase wird ein Qwen3-VL-Encoder geladen und Ihr Text-Prompt in Konditionierungsvektoren umgewandelt. Geben Sie Ihren Prompt in CLIPTextEncode (#11) in natürlicher Sprache ein; detaillierte fotografische Hinweise wie Objektiv, Beleuchtung, Tageszeit und Textur funktionieren gut. Der negative Input wird absichtlich über ConditioningZeroOut (#9) nullgesetzt, um stabile Ergebnisse im Turbo-Regime mit geringer Führung zu erhalten. Wenn Sie explizite Negative bevorzugen, ersetzen Sie ConditioningZeroOut durch einen zweiten CLIPTextEncode, um einen negativen Prompt bereitzustellen. Gute Prompt-Hygiene hier reduziert die Notwendigkeit für hohe CFG oder zusätzliche Schritte später.
Latente Einrichtung und Modell-Laden (EmptyLatentImage (#8) + UNETLoader (#2))#
EmptyLatentImage (#8) erstellt die latente Leinwand. Das Standard-Portrait-Format 960×1280 ist ein ausgewogener Ausgangspunkt für Personen, Innenräume und hohe Produktaufnahmen; Sie können andere Größen für Quadrate oder Breitbilder einstellen. UNETLoader (#2) lädt die Boogu Turbo Diffusionsgewichte aus dem Comfy-Org-Paket und richtet das Modell auf Ihren gewählten Encoder und VAE aus. Das Tauschen von BF16 und FP8-Varianten ist einfach, wenn Sie VRAM und Durchsatz ausbalancieren müssen. Halten Sie die Modellwahl konsistent über Ihr Projekt hinweg, um Stilkontinuität zu gewährleisten.
Schnelles LCM-Sampling (KSampler (#32) mit Sampler lcm)#
Der KSampler ist für Latent Consistency Models konfiguriert, um hohe Qualität in etwa vier Schritten zu erreichen. LCM-Destillation zielt auf sehr niedrige Guidance-Werte ab, weshalb dieser Boogu Turbo text-to-image ComfyUI Workflow stabil mit CFG nahe 1.0 läuft, während die Prompt-Adhärenz beibehalten wird. Wenn Sie etwas mehr Mikrodetaillierung wünschen, erhöhen Sie die Schritte maßvoll und fixieren Sie den Seed für A/B-Vergleiche. Bei Stil- oder Kompositionsänderungen rollen Sie den Seed neu und verfeinern den Prompt, anstatt die Schritte zu hoch zu treiben. Hintergrundtheorie zur LCM-Few-Step-Inferenz wird im Originalpapier Latent Consistency Models beschrieben.
Dekodieren und Speichern (VAELoader (#5) → VAEDecode (#3) → SaveImage (#58))#
Der FLUX.1 VAE, der in VAELoader (#5) geladen wurde, dekodiert Latente zu RGB in VAEDecode (#3). Das Anpassen der VAE-Familie an Ihr Diffusions-Backbone führt in der Regel zu treueren Farben und Texturen, weshalb dieser Graph mit dem FLUX.1 VAE ausgeliefert wird. SaveImage (#58) schreibt Ergebnisse auf die Festplatte; ändern Sie das Ausgabeprefix, um Experimente nach Prompt, Seed oder Seitenverhältnis zu organisieren. Wenn Sie später Upscaler oder Post-FX verketten, verzweigen Sie vom Image-Output von VAEDecode, um eine saubere Historie zu bewahren.
Schlüssel-Knoten im Comfyui Boogu Turbo text-to-image ComfyUI Workflow#
CLIPTextEncode (#11)#
Dieser Knoten beherbergt Ihren Haupt-Text-Prompt und erzeugt die positive Konditionierung, die vom Sampler verwendet wird. Halten Sie Prompts prägnant und fügen Sie Szenenhinweise wie Kamera-Brennweite, Tageszeit und Material-Adjektive hinzu. Wenn Sie negative Prompts verwenden möchten, erstellen Sie einen zweiten CLIPTextEncode und verbinden Sie ihn mit dem negativen Input des Samplers, wobei Sie ConditioningZeroOut (#9) entfernen.
ConditioningZeroOut (#9)#
Dies deaktiviert negative Konditionierung, indem ein Nullvektor in den negativen Port des Samplers eingespeist wird. Es an Ort und Stelle zu lassen, ist eine gute Standardeinstellung für Turbos Niedrig-Guidance-Konfiguration. Entfernen Sie es nur, wenn Sie speziell negative Prompts benötigen und sie klar artikulieren können.
EmptyLatentImage (#8)#
Steuert Ausgabedimensionen und Stapelgröße. Beginnen Sie bei 960×1280 für Porträts oder 1280×960 für breitere Umgebungen; passen Sie es basierend auf dem Subjekt und dem Speicherbudget an. Größere Latente bieten mehr Leinwand für feine Details, erhöhen aber den VRAM-Verbrauch und die Dekodierungszeit.
UNETLoader (#2)#
Wählt den Boogu-Image-0.1-Turbo-Checkpoint für die Generierung aus. Verwenden Sie die BF16-Variante für höchste Qualität auf leistungsfähigen GPUs oder die FP8-Variante für geringeren VRAM und schnellere Ladezeiten, beide verfügbar im Comfy-Org-Paket. Modellausführungen und ihre beabsichtigten Ordner sind bei Comfy-Org/Boogu-Image dokumentiert.
KSampler (#32)#
Führt den Diffusionsprozess mit dem lcm-Sampler für die Few-Step-Inferenz aus. Schlüsselhebel sind der Seed, die Anzahl der Schritte und CFG; Turbo ist so konzipiert, dass es mit sehr niedriger Guidance und wenigen Schritten läuft, während die Qualität beibehalten wird, wie in den offiziellen Turbo-Einstellungen auf der Modellkarte bei Boogu/Boogu-Image-0.1-Turbo-fp8 reflektiert. Für kontrollierte Erkundungen fixieren Sie den Seed und variieren Schritte oder Prompt-Formulierungen jeweils um eine Änderung.
VAELoader (#5) und VAEDecode (#3)#
Laden und anwenden des FLUX.1 VAE für das Dekodieren. Bei der FLUX.1-Familie zu bleiben, hält Farben, Kontrast und Texturverhalten konsistent mit dem Training-Setup des UNet. Das Mischen von VAEs ist möglich, kann aber subtile Verschiebungen in Tonalität oder Sättigung verursachen; testen Sie, bevor Sie sich auf einen neuen Look festlegen. Referenzgewichte: black-forest-labs/FLUX.1-dev.
SaveImage (#58)#
Steuert die Ausgabebenennung und den Zielort. Verwenden Sie sinnvolle Präfixe wie Projektname, Aspekt-Tag oder Seed, um Läufe organisiert zu halten. Beim Erweitern der Pipeline hier verzweigen, um Upscaler, Farbkorrekturen oder Captioner hinzuzufügen, ohne das Basisspeichern zu stören.
Optionale Extras#
- Halten Sie CFG nahe 1.0 und Schritte um vier für schnellste Iterationen; gehen Sie zu 6–8 Schritten nur, wenn Sie ein wenig mehr Textur oder Stabilität benötigen.
- Rollen Sie den Seed neu, um Komposition zu erforschen; fixieren Sie den Seed, um Stil und Mikrodetaillierung fein abzustimmen.
- Bevorzugen Sie BF16-Gewichte für beste Qualität auf hochspeicherfähigen GPUs; wechseln Sie zu FP8, um das Laden zu beschleunigen und VRAM zu reduzieren.
- Für Text-in-Bild-Lesbarkeit versuchen Sie eine etwas höhere Auflösung und fügen Sie explizite Typografie-Hinweise im Prompt hinzu.
- Speichern Sie oft Zwischenfavoriten; kleine Prompt-Anstöße in diesem Boogu Turbo text-to-image ComfyUI Workflow können in Sekunden bedeutend unterschiedliche Szenen erzeugen.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken RunningHub für die Workflow-Referenz, Boogu für das Boogu-Image-Repository und das Boogu-Image-0.1-Turbo-Modell, Comfy-Org für die Boogu ComfyUI-Gewichte und ComfyUI für das Boogu-Tutorial für ihre Beiträge und Wartung. Für autoritative Details verweisen Sie bitte auf die originalen Dokumentationen und Repositories unten verlinkt.
Ressourcen#
- RunningHub/Workflow-Referenz
- Docs / Release Notes: RunningHub post
- Boogu/Projektseite
- Docs / Release Notes: boogu.org
- Boogu/Boogu Image Repository
- GitHub: boogu-project/Boogu-Image
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- Boogu/Boogu-Image-0.1-Turbo-Modell
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- GitHub: boogu-project/Boogu-Image
- Comfy-Org/Boogu ComfyUI Gewichte
- Hugging Face: Comfy-Org/Boogu-Image
- ComfyUI/Boogu-Tutorial
- Docs / Release Notes: ComfyUI tutorial
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.



