



你好,AI 藝術家朋友!👋 歡迎來到我們為初學者設計的 ComfyUI 教學,這是一個令人難以置信的強大且靈活的工具,用於創作驚艷的 AI 生成藝術作品。🎨 在本指南中,我們將帶你了解 ComfyUI 的基礎知識、探索其核心功能,並幫助你釋放它的潛力,將你的 AI 藝術創作提升到全新層次。🚀
我們將涵蓋以下內容:
- 1. 什麼是 ComfyUI?
- 1.1. ComfyUI vs. AUTOMATIC1111
- 1.2. 從哪裡開始使用 ComfyUI?
- 1.3. 基本控制項
- 2. ComfyUI 工作流:從文字到圖像
- 2.1. 選擇一個模型
- 2.2. 輸入正面提示詞與負面提示詞
- 2.3. 生成圖像
- 2.4. ComfyUI 的技術說明
- 2.4.1. Load Checkpoint 節點
- 2.4.2. CLIP Text Encode
- 2.4.3. Empty Latent Image
- 2.4.4. VAE
- 2.4.5. KSampler
- 7. ComfyUI 放大(Upscale)
- 7.1. 像素放大(Upscale Pixel)
- 7.1.1. 使用演算法進行 Upscale Pixel
- 7.1.2. 使用模型進行 Upscale Pixel
- 7.2. 潛在放大(Upscale Latent)
- 7.3. Upscale Pixel vs. Upscale Latent
- 9. ComfyUI 管理器
- 9.1. 如何安裝缺失的自訂節點
- 9.2. 如何更新自訂節點
- 9.3. 如何在工作流中載入自訂節點
- 10. ComfyUI Embeddings
- 10.1. 支援自動補全的 Embedding
- 10.2. Embedding 權重設定
- 11. ComfyUI LoRA
- 11.1. 簡單的 LoRA 工作流
- 11.2. 多重 LoRA 整合
- 12. ComfyUI 快捷鍵與技巧
- 12.1. 複製與貼上
- 12.2. 移動多個節點
- 12.3. 繞過某個節點
- 12.4. 最小化節點
- 12.5. 生成圖像
- 12.6. 嵌入式工作流
- 12.7. 固定種子以節省時間
1. 什麼是 ComfyUI?🤔#
ComfyUI 就像是一支魔法棒 🪄,可以輕鬆創作出令人驚豔的 AI 生成藝術。從本質上來說,ComfyUI 是建立在 Stable Diffusion 基礎上的節點式圖形使用者介面(GUI),而 Stable Diffusion 是一種先進的深度學習模型,可根據文字描述生成圖像。🌟 但讓 ComfyUI 真正與眾不同的,是它讓像你這樣的創作者能釋放無限創意,將腦海中最狂野的想法轉化為視覺現實。
想像你擁有一塊數位畫布,可以透過連接不同的節點來構建屬於你自己的圖像生成流程,每個節點都代表一個特定的功能或操作。🧩 這就像是為你的 AI 藝術傑作打造一套視覺化的「創作食譜」!
想從零開始使用文字提示生成圖像?這裡有個節點可以做到!想應用特定的取樣器或微調噪聲程度?只要加入對應節點,就能親眼見證魔法發生。✨
但最精彩的部分來了:ComfyUI 將工作流拆解為可重組的元素,讓你能完全自由地打造符合個人創作流程的專屬工作流。🖼️ 就像擁有一套為你的創意量身訂做的工具箱!
1.1. ComfyUI vs. AUTOMATIC1111 🆚#
AUTOMATIC1111 是 Stable Diffusion 的預設 GUI。那你是否應該使用 ComfyUI 呢?讓我們來比較一下:
✅ 使用 ComfyUI 的優勢:
- 輕量化:執行快速、效能高。
- 彈性高:可高度自訂以符合你的需求。
- 資料透明:節點之間的資料流可視化,容易理解。
- 易於分享:每個工作流都是可重現的 JSON 文件。
- 原型開發友好:可透過圖形界面而非程式碼建立原型。
❌ 使用 ComfyUI 的劣勢:
- 介面不一致:不同工作流可能會有不同的節點佈局。
- 細節過多:對初學者來說,太多底層細節可能造成負擔。
1.2. 從哪裡開始使用 ComfyUI?🏁#
我們相信,學習 ComfyUI 最好的方式,就是深入實例並親自動手操作。🙌 這正是我們建立這套獨特教學的初衷,使它與眾不同。
而這裡就是最棒的部分:🌟 我們已將 ComfyUI 直接整合進這個網頁中!你可以在瀏覽教學的同時,實時與 ComfyUI 範例互動。🌟 現在,就讓我們開始吧!
2. ComfyUI 工作流:從文字到圖像 🖼️#
讓我們從最簡單的案例開始:從文字生成圖像。點擊 Queue Prompt 執行工作流。稍等片刻後,你應該會看到你的第一張生成圖像!要查看任務佇列,只需點擊 View Queue。
這裡是一個預設的「從文字到圖像」工作流範例,供你試用:
基本構建元件 🕹️#
ComfyUI 的工作流由兩個基本構建元件組成:節點 和 連線。
- 節點 是矩形方塊,例如 Load Checkpoint、Clip Text Encoder 等。每個節點代表一段執行程式,具有輸入、輸出與參數。
- 連線(邊) 是將節點間的輸出與輸入串接起來的線條。
基本操作 🕹️#
- 使用滑鼠滾輪或觸控板雙指縮放畫布。
- 拖曳並按住節點的輸入或輸出點,以連接其他節點。
- 按住滑鼠左鍵並拖曳,以移動整個工作區視圖。
讓我們深入了解這個工作流的細節。#
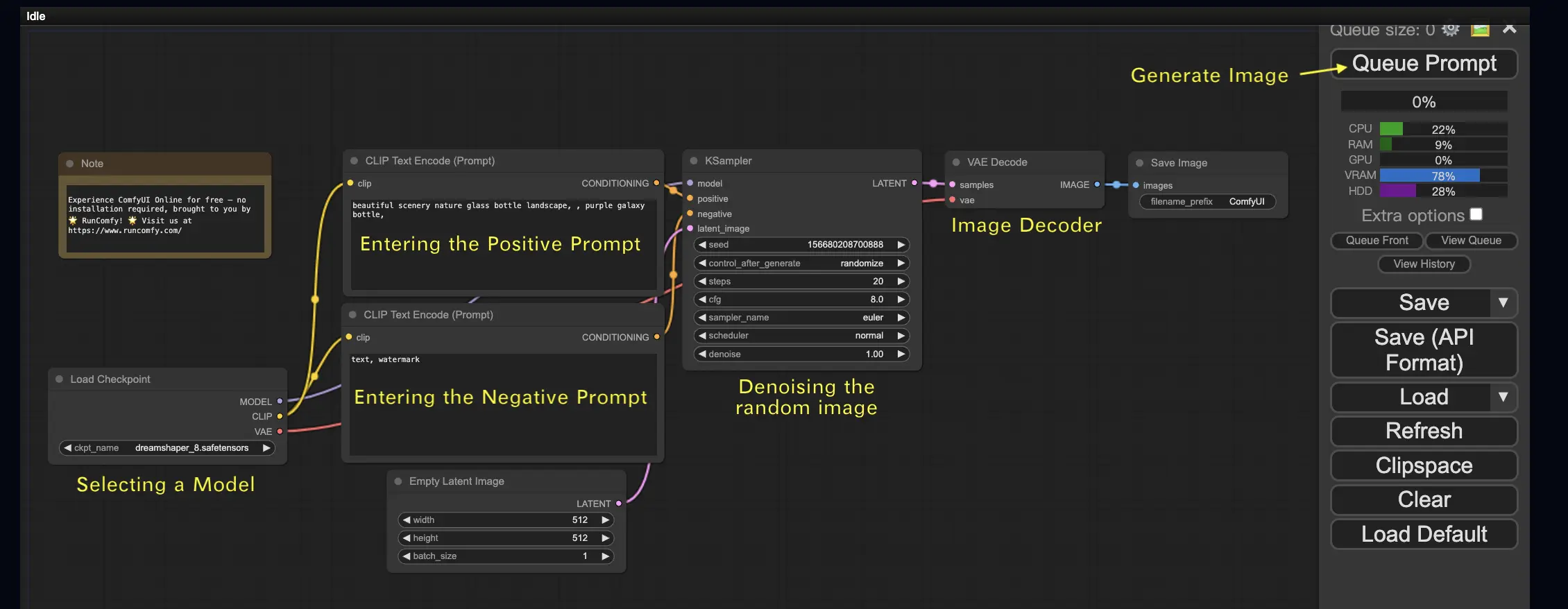
2.1. 選擇一個模型 🗃️#
首先,在 Load Checkpoint 節點中選擇一個 Stable Diffusion Checkpoint 模型。點擊模型名稱以檢視可用模型。如果點擊後沒有反應,你可能需要上傳自訂模型。
2.2. 輸入正面提示詞與負面提示詞 📝#
你會看到兩個標記為 CLIP Text Encode (Prompt) 的節點。上方的提示詞連接至 KSampler 節點的 positive 輸入,下方的提示詞連接至 negative 輸入。因此,請在上方輸入正面提示詞,在下方輸入負面提示詞。
CLIP Text Encode 節點會將提示詞轉換為 token,並透過文本編碼器將其編碼為嵌入向量。
💡 小提示:使用 (關鍵詞:權重) 語法可控制提示詞的影響力,例如 (keyword:1.2) 增強效果,或 (keyword:0.8) 減弱其影響。
2.3. 生成圖像 🎨#
點擊 Queue Prompt 運行工作流。稍等片刻,你將看到第一張生成的圖像!
2.4. ComfyUI 的技術說明 🤓#
ComfyUI 的強大之處在於它的高度可配置性。瞭解每個節點的功能,能幫助你依需求進行自訂。不過,在進入細節前,我們先快速認識 Stable Diffusion 的基本原理,以更好理解 ComfyUI 的工作方式。
Stable Diffusion 的處理流程可分為三個主要步驟:
- 文字編碼:使用者輸入的提示詞會由 Text Encoder 編譯為單字的特徵向量,這是將語言轉換為模型可理解格式的步驟。
- 潛在空間轉換:Text Encoder 的向量與一張隨機噪聲圖像會被映射到潛在空間。在此空間中,噪聲圖像會根據特徵向量進行去噪,產生中間圖像。這正是魔法發生的地方,模型會學習將語言與視覺概念對應起來。
- 圖像解碼:潛在空間中的中間表示會透過 Image Decoder 解碼為我們能實際看到的圖像。
現在我們對 Stable Diffusion 的整體流程有了概念,讓我們回到 ComfyUI,深入了解其中實現這些步驟的關鍵節點與元件。
2.4.1. Load Checkpoint 節點 🗃️#
ComfyUI 中的 Load Checkpoint 節點是選擇 Stable Diffusion 模型的關鍵。Stable Diffusion 模型包含三大元件:MODEL、CLIP 和 VAE。以下是這些元件在 ComfyUI 中的作用與對應關係:
- MODEL:這是潛在空間中執行的噪聲預測模型,是圖像生成的核心。在 ComfyUI 中,Load Checkpoint 的 MODEL 輸出會連接至 KSampler 節點,由該節點執行反向擴散與去噪步驟,逐步生成圖像,直到接近提示詞內容。
- CLIP:CLIP(對比式語言-圖像預訓練模型)負責處理提示詞,將其轉換為模型可理解的嵌入表示,以指導圖像生成。在 ComfyUI 中,Checkpoint 的 CLIP 輸出連接至 CLIP Text Encode 節點,該節點接收提示詞並轉換為語義嵌入,讓 MODEL 能根據語意生成相符圖像。
- VAE:VAE(變分自編碼器)處理圖像在像素與潛在空間之間的轉換。其包含圖像編碼器(encoder)與解碼器(decoder)。在文字轉圖像的流程中,VAE 用於最後一步——將潛在圖像轉換為可視的像素圖像。ComfyUI 中的 VAE Decode 節點會接收來自 KSampler 的輸出,使用解碼器重建圖像。
⚠️ 請注意:VAE 是與 CLIP 分開的元件。CLIP 負責語意處理,而 VAE 專注於圖像空間的轉換。
2.4.2. CLIP Text Encode 📝#
CLIP Text Encode 節點負責接收使用者輸入的提示詞,並傳入 CLIP 模型。CLIP 是一個強大的語言-圖像模型,能理解語義並將文字轉為向量表示(嵌入),再與視覺概念匹配。
每個詞語會轉換為一個高維向量,這些嵌入向量能捕捉語意,讓 MODEL 能生成與語意一致的圖像。
2.4.3. Empty Latent Image 🌌#
從文字生成圖像的第一步是建立一張潛在空間中的隨機圖像,這張圖像是 MODEL 運算的起點。這個潛在圖像的尺寸比例與最終圖像相對應。
你可以在 ComfyUI 中設定潛在圖像的寬度、高度與批量大小(一次生成幾張圖像)。
✅ 推薦尺寸:
- SD v1.5:512x512 或 768x768
- SDXL:1024x1024
ComfyUI 也提供常見的長寬比選項,如:
- 1:1(正方形)
- 3:2 / 4:3(橫向)
- 2:3 / 3:4 / 9:16(縱向)
- 16:9(寬螢幕)
⚠️ 注意:潛在圖像的尺寸需為 8 的倍數,以保證與模型架構相容。
2.4.4. VAE 🔍#
VAE(變分自編碼器)是 Stable Diffusion 中的關鍵元件,負責像素與潛在空間間的圖像轉換。它包含兩個部分:
- 編碼器:將像素圖像壓縮成潛在向量(例如將 512x512 圖像壓縮為 64x64 潛在圖像)。
- 解碼器:將潛在向量還原為像素圖像,用於生成最終輸出。
✅ 使用 VAE 的優勢:
- 效率高:壓縮圖像後可加快生成速度並節省記憶體。
- 潛在空間操作性強:能在低維度空間中更精確地控制圖像樣貌與細節。
⚠️ 潛在限制:
- 資料遺失:編解碼過程中可能遺失部分圖像細節,造成影像略有差異。
- 細節捕捉有限:潛在空間可能無法完整保留圖像的所有資訊,部分特徵可能缺失。
儘管如此,VAE 是實現快速圖像生成與可控圖像修改的核心元件,在 ComfyUI 中扮演著不可或缺的角色。
2.4.5. KSampler ⚙️#
ComfyUI 中的 KSampler 節點是 Stable Diffusion 圖像生成過程的核心。它負責對潛在空間中的隨機圖像進行去噪,以符合使用者輸入的提示詞。KSampler 採用一種稱為反向擴散(Reverse Diffusion)的技術,透過去除噪聲並根據 CLIP 嵌入進行引導,逐步為潛在表示添加有意義的細節。
KSampler 節點提供多個參數,讓使用者可以微調圖像生成流程:
Seed(種子):種子值控制初始噪聲與圖像構圖。設定相同的種子可重現結果,確保多次生成的一致性。
Control_after_generation:決定每次生成後種子如何變化。可設為:
- 隨機(每次使用新隨機種子)
- 遞增(每次加一)
- 遞減(每次減一)
- 固定(保持不變)
Step(步數):設定采樣步驟數,數值越高生成越細緻但所需時間也會增加。
Sampler_name(采樣器名稱):選擇具體的采樣算法。不同采樣器會生成略有不同的結果,效率也不一樣。
Scheduler(調度器):控制每一步去噪時的噪聲水平變化速率。
Denoise(去噪強度):設定要消除的初始噪聲量。值為 1 表示完全去噪,生成乾淨且細節豐富的圖像。
透過這些參數的調整,你可以更細緻地控制圖像輸出的風格與品質。
現在,你準備好展開 ComfyUI 之旅了嗎?#
在 RunComfy,我們為你打造了終極的 ComfyUI 線上體驗,無需複雜安裝! 🎉 立即體驗 ComfyUI 線上版,釋放前所未有的創作潛力!🎉
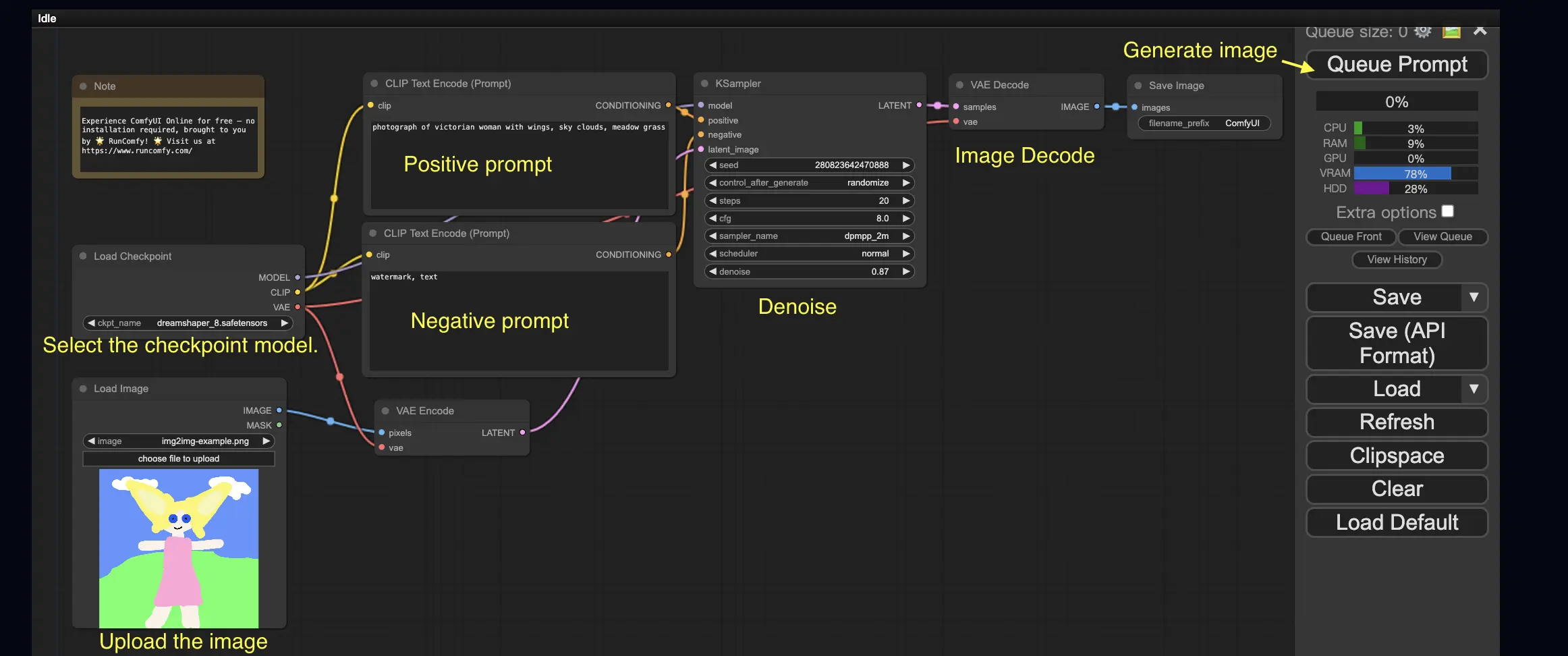
3. ComfyUI 工作流:從圖像到圖像 🖼️#
「從圖像到圖像」的工作流會根據輸入圖像與提示詞生成新圖像。現在馬上試試看吧!
使用「從圖像到圖像」工作流的步驟如下:
- 選擇 Checkpoint 模型。
- 上傳輸入圖像作為圖像提示。
- 編輯正面與負面提示詞。
- 可選:在 KSampler 節點中調整
denoise(去噪強度)。 - 點擊 Queue Prompt 開始生成!
如需探索更多進階 ComfyUI 工作流,歡迎參考我們的 🌟ComfyUI 工作流列表🌟
4. ComfyUI SDXL 🚀#
得益於其高度可配置性,ComfyUI 是最早支援 Stable Diffusion XL(SDXL)模型的 GUI 之一。馬上動手試試看吧!
使用 ComfyUI SDXL 工作流的步驟如下:
- 輸入或修改正面與負面提示詞。
- 點擊 Queue Prompt 開始生成圖像。
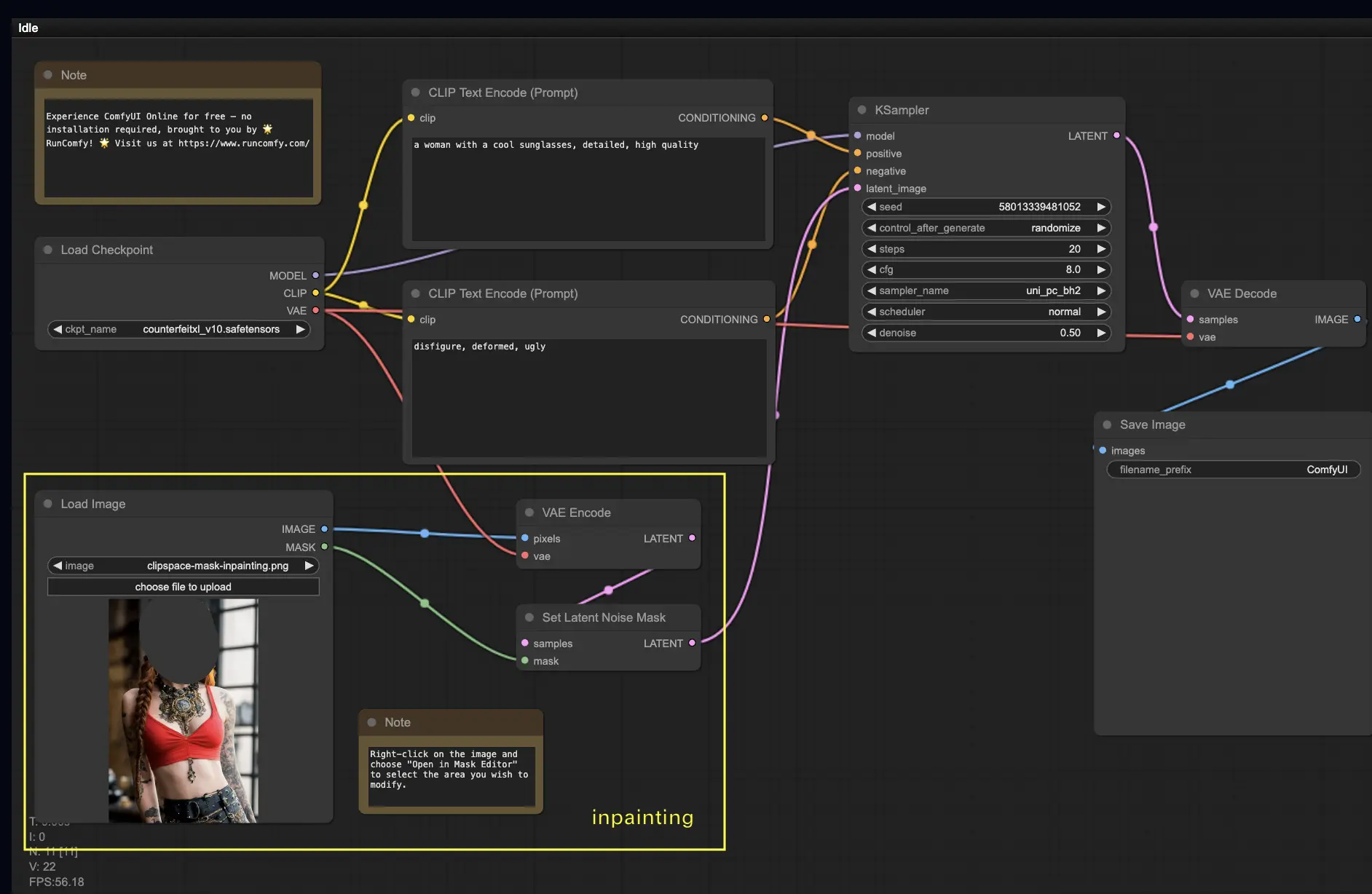
5. ComfyUI Inpainting 🎨#
讓我們來探索一個更進階的功能:Inpainting!當你擁有一張不錯的圖像,但想要修改其中某些區域時,Inpainting 就是你的最佳選擇。現在立刻試試吧!
使用 Inpainting 工作流的步驟:
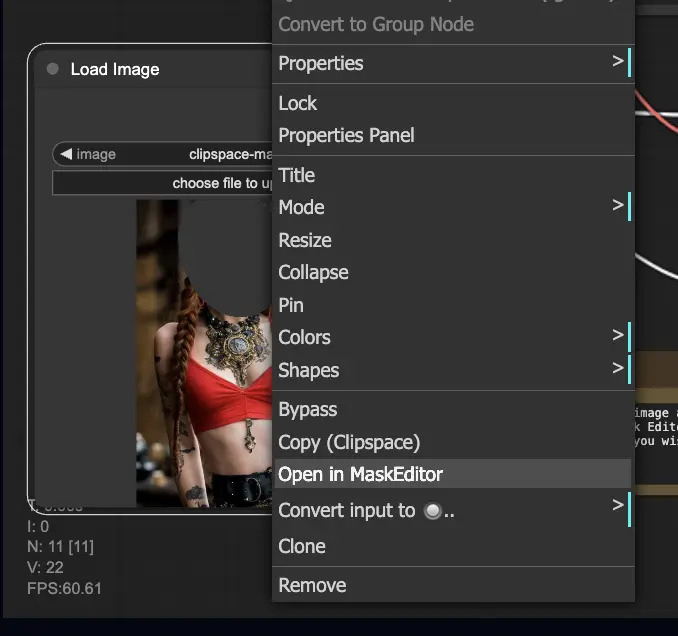
- 上傳你想進行 Inpainting 的圖像。
- 右鍵點擊圖像,選擇「Open in MaskEditor」。在要重新生成的區域繪製遮罩,然後點擊「Save to node」。
- 選擇一個 Checkpoint 模型:
- 此工作流僅適用於標準 Stable Diffusion 模型,不適用於 Inpainting 專用模型。
- 若你想使用 Inpainting 模型,請將「VAE Encode」和「Set Noise Latent Mask」節點替換為「VAE Encode (Inpaint)」節點。
- 自訂 Inpainting 過程:
- 在 CLIP Text Encode (Prompt) 節點中輸入額外提示詞,來指引 Inpainting 的風格、主題或內容。
- 設定適當的 Denoise 值,例如 0.6。
- 點擊 Queue Prompt 執行 Inpainting!
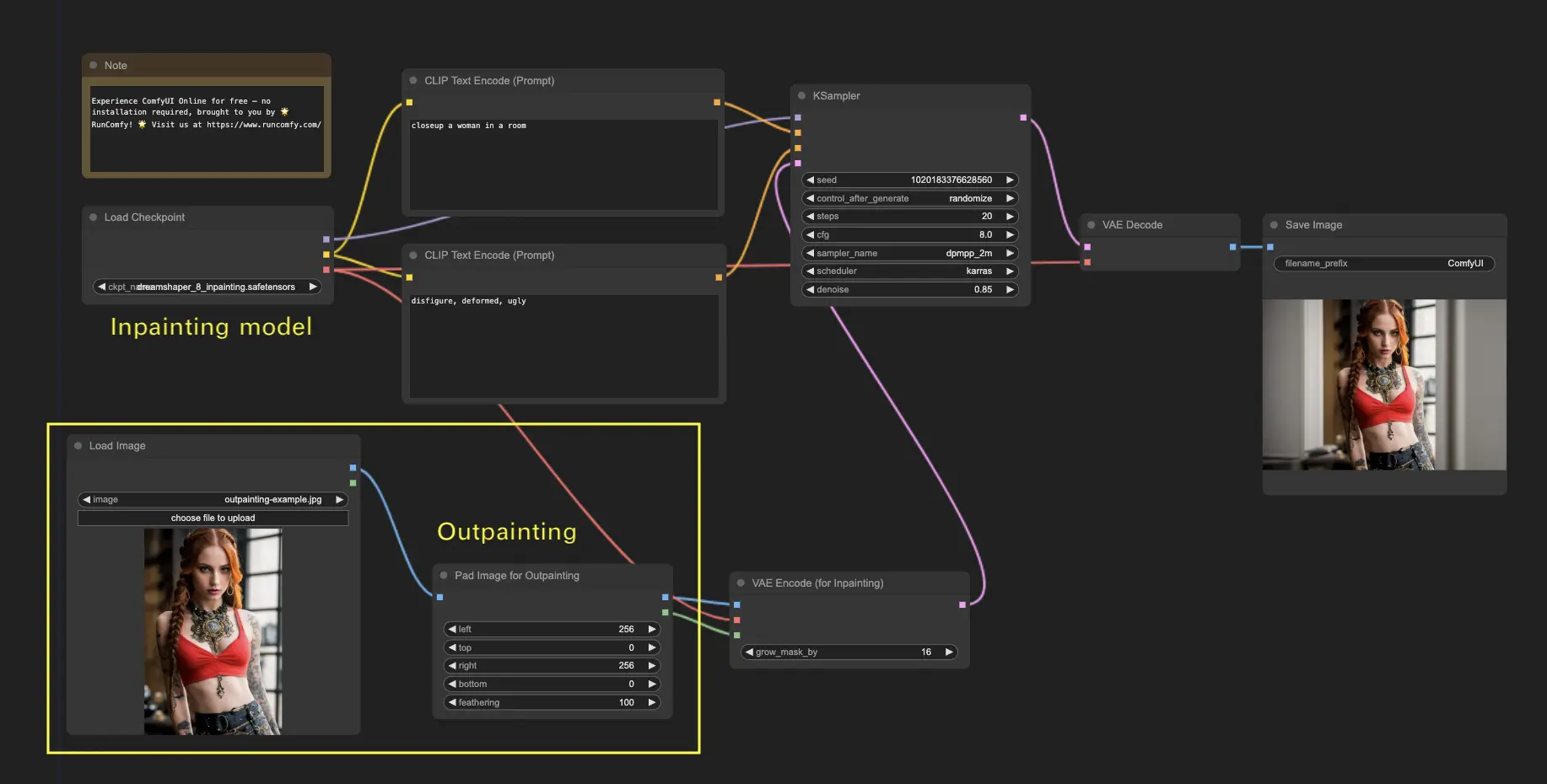
6. ComfyUI Outpainting 🖌️#
Outpainting 是另一種令人興奮的技術,能讓你將圖像延伸超出其原始邊界。🌆 就像你擁有一塊無限延展的畫布!
使用 ComfyUI Outpainting 工作流的步驟如下:
- 從你想要延伸的圖像開始。
- 在工作流中使用「Pad Image for Outpainting」節點。
- 設定 Outpainting 的參數:
- left, top, right, bottom:指定每個方向要擴展的像素數量。
- feathering:調整原始圖像與延伸區域的過渡平滑度。數值越高,過渡越柔和,但也可能引入模糊。
- 自訂 Outpainting:
- 在 CLIP Text Encode (Prompt) 節點中輸入提示詞,指定你希望在延伸區域中展現的風格或主題。
- 嘗試不同提示詞來獲得最佳效果。
- 微調 VAE Encode (for Inpainting) 節點:
- 調整 grow_mask_by 參數以控制遮罩的大小,建議設為大於 10。
- 點擊 Queue Prompt 開始 Outpainting!
若想探索更多進階的 Inpainting / Outpainting 工作流,歡迎造訪我們的 🌟ComfyUI 工作流列表🌟
7. ComfyUI Upscale ⬆️#
接下來,讓我們深入了解 ComfyUI 的放大(Upscale)功能。我們將介紹三種基本工作流,幫助你高效完成高品質的放大任務。
目前有兩種主要的放大方式:
- Upscale Pixel:直接對可見圖像進行放大處理。
- 輸入:圖像;輸出:放大後的圖像
- Upscale Latent:對潛在空間中的圖像進行放大,最後再解碼成可見圖像。
- 輸入:潛在表示;輸出:放大後的潛在表示(需要經 VAE 解碼)
7.1. Upscale Pixel 🖼️#
這裡有兩種 Upscale Pixel 的實現方式:
- 使用演算法:生成速度最快,但畫質略遜於模型放大。
- 使用模型:結果更佳,但所需時間較長。
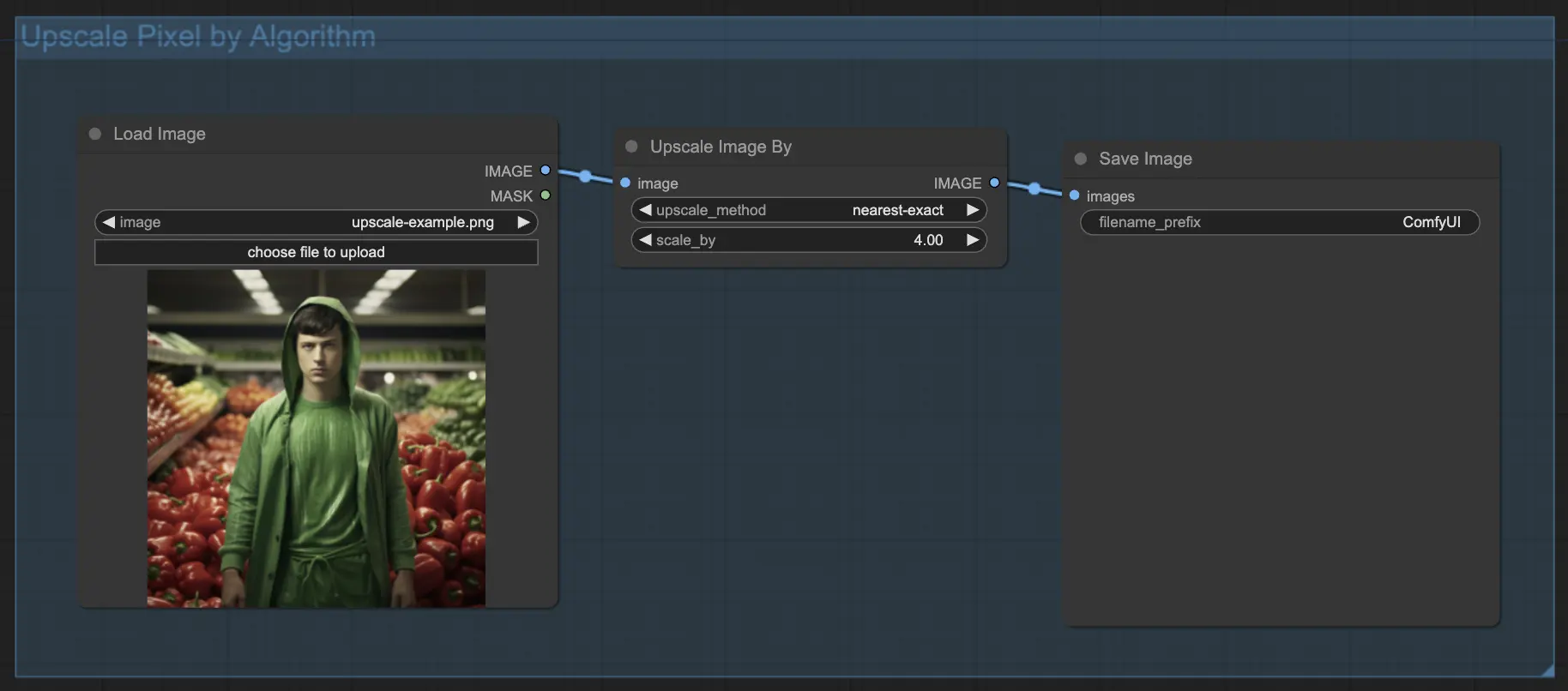
7.1.1 使用演算法進行 Upscale Pixel 🧮#
- 新增 Upscale Image by 節點。
- method 參數:選擇放大演算法(bicubic、bilinear、nearest-exact)。
- Scale 參數:指定放大倍率(例如 2 表示放大兩倍)。
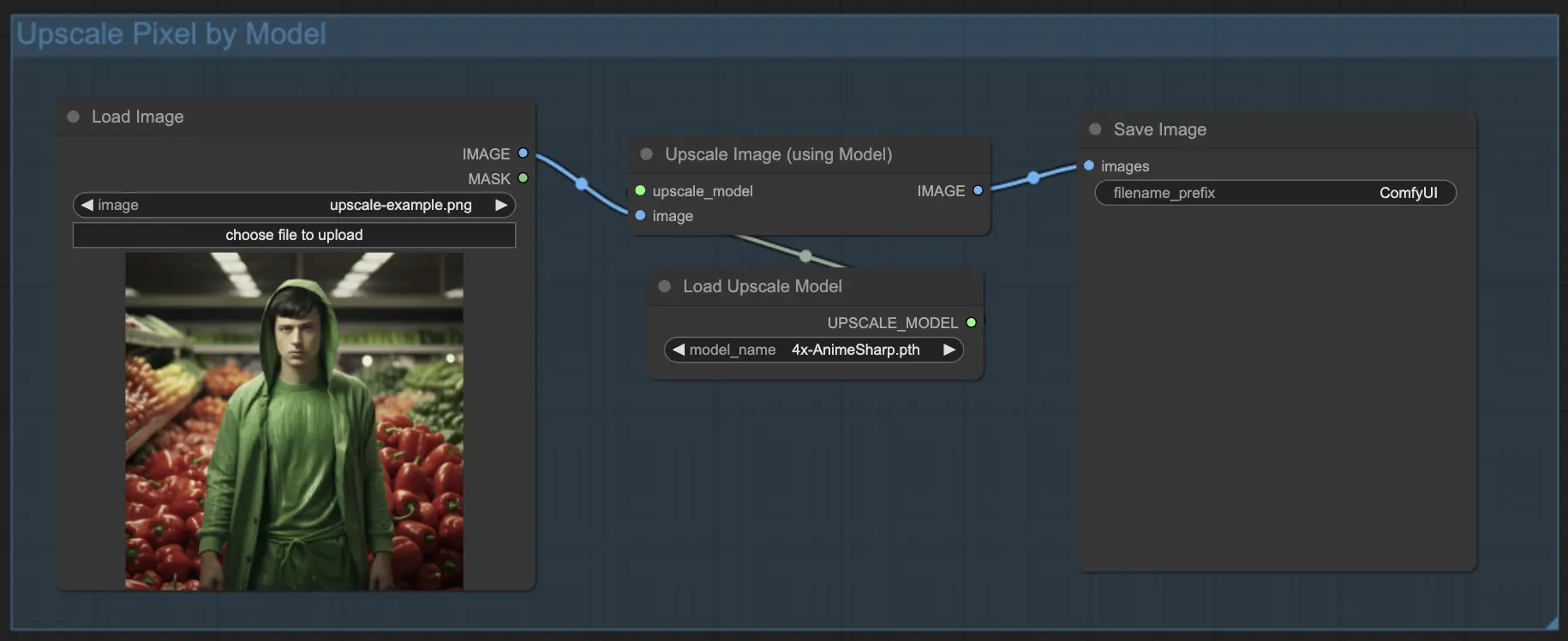
7.1.2 使用模型進行 Upscale Pixel 🤖#
- 新增 Upscale Image (using Model) 節點。
- 新增 Load Upscale Model 節點。
- 選擇適合你圖像類型的放大模型(如動漫或寫實風格)。
- 選擇放大倍率(X2 或 X4)。
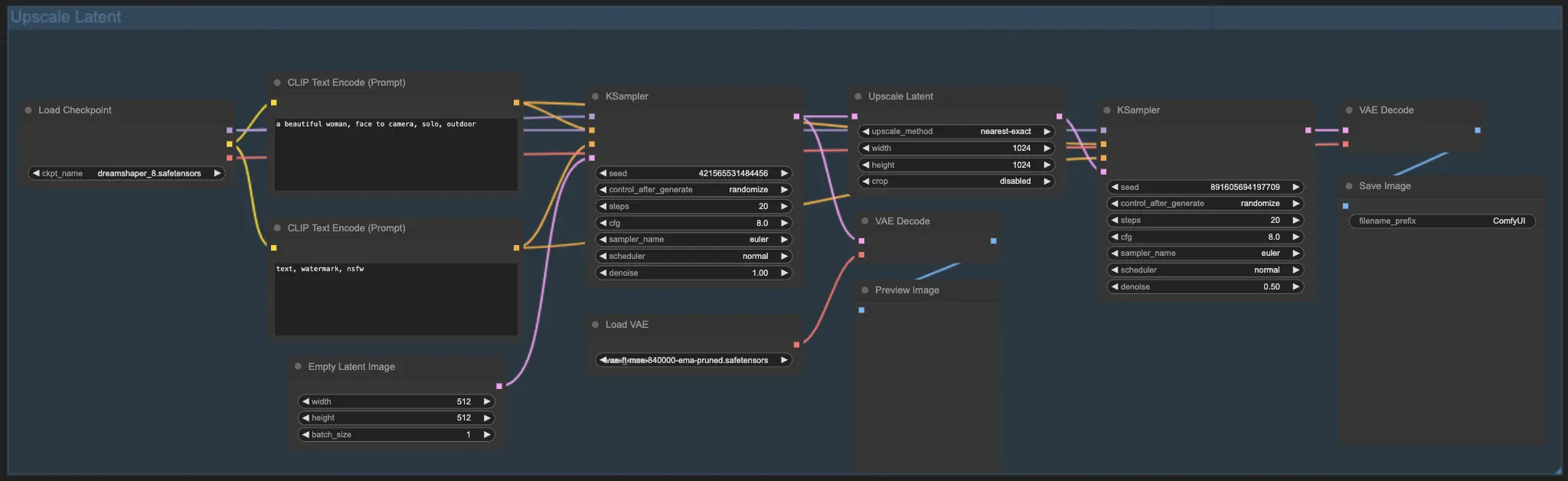
7.2. Upscale Latent ⚙️#
另一種放大方式是 Upscale Latent,又稱 Hi-res Latent Fix Upscale,它直接在潛在空間中執行放大處理。
7.3. Upscale Pixel vs. Upscale Latent 🆚#
| 方法 | 特點 |
|---|---|
| **Upscale Pixel** | 僅放大可見圖像,不新增細節。生成速度快,但可能有模糊、細節損失。 |
| **Upscale Latent** | 不僅放大潛在圖像,還會根據提示重新合成細節,更豐富但與原圖略有偏差。生成速度較慢。 |
想深入探索還原與放大的進階工作流?歡迎參考我們的 🌟ComfyUI 工作流列表🌟!
8. ComfyUI ControlNet 🎮#
準備好透過 ControlNet 將你的 AI 藝術提升至全新境界吧!這是一項革命性技術,徹底改變圖像生成方式。
ControlNet 就像魔法權杖 🪄,賦予你前所未有的主控力,讓你能夠精確引導 AI 生成圖像內容。它與 Stable Diffusion 等模型合作,提升表現與準確性,為創作者提供更大的自由度。
你可以控制圖像的邊緣線、人物姿態、深度資訊,甚至語義分割圖。🌠 一切盡在你的掌握!
若你想更深入了解 ControlNet 的應用,請查看我們完整的📚ComfyUI 中掌握 ControlNet 的教程📚,內含逐步教學與範例,幫助你成為 ControlNet 達人!🏆
9. ComfyUI 管理器 🛠️#
ComfyUI 管理器 是一個自定義節點工具,允許你透過圖形界面安裝與更新其他自定義節點。你可以在 Queue Prompt 選單上找到 Manager 按鈕。
9.1 如何安裝缺少的自定義節點 📥#
當工作流需要你尚未安裝的節點時,請依以下步驟操作:
- 在選單中點擊 Manager。
- 點擊 Install Missing Custom Nodes。
- 完整重啟 ComfyUI。
- 刷新你的瀏覽器。
9.2 如何更新自定義節點 🔄#
- 點擊選單中的 Manager。
- 點擊 Fetch Updates(這步驟可能需要一些時間)。
- 點擊 Install Custom Nodes。
- 若有可用更新,你將在已安裝節點旁看到 Update 按鈕。
- 點擊 Update。
- 重啟 ComfyUI。
- 刷新你的瀏覽器以應用更新。
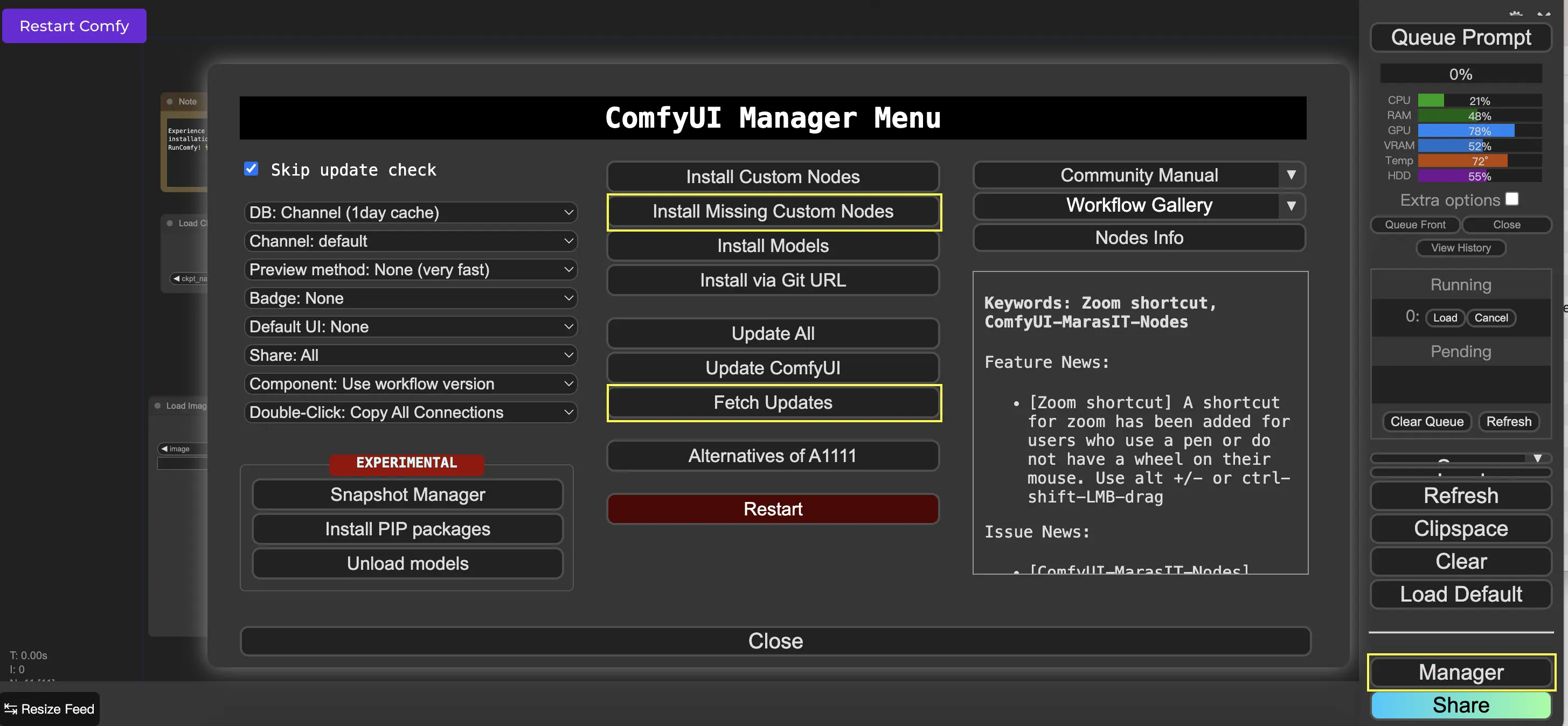
9.3. 如何在工作流中載入自訂節點 🔍#
雙擊任意空白區域,即可彈出節點搜尋選單,搜尋並加入你需要的節點。
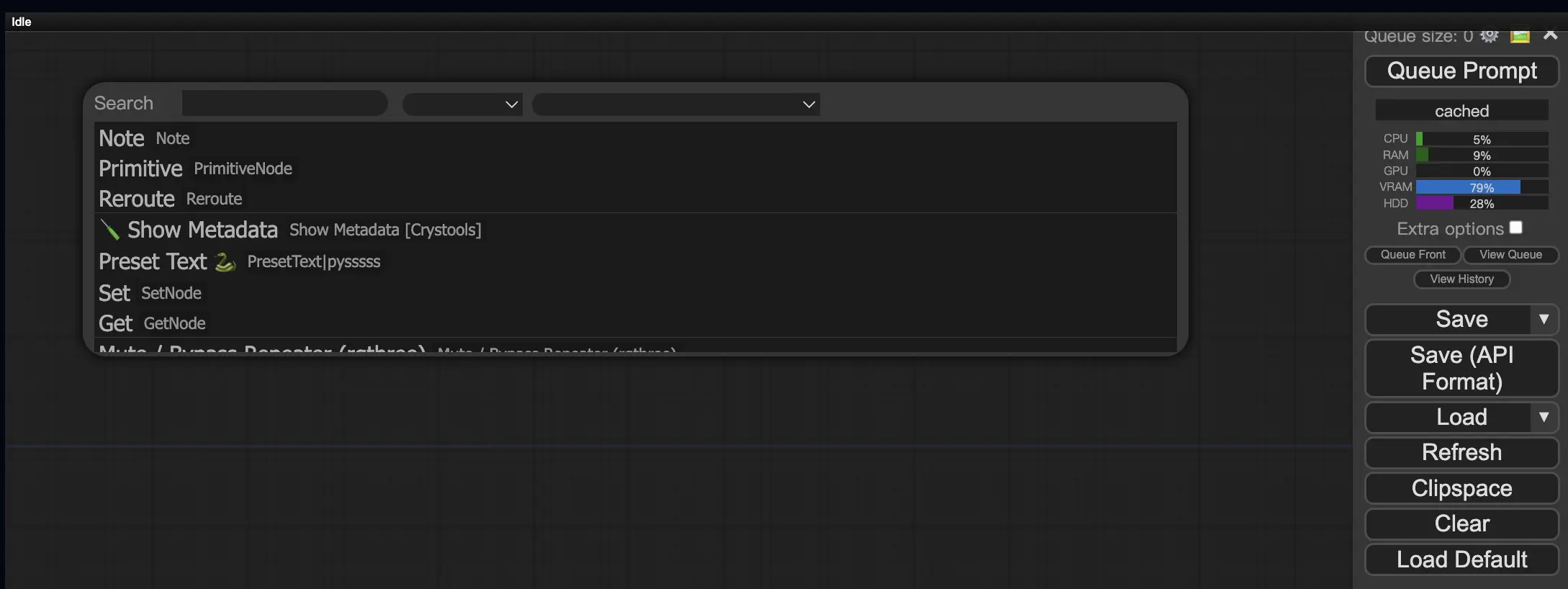
10. ComfyUI Embeddings 📝#
Embeddings(也稱為 textual inversion)是 ComfyUI 中的一項強大功能,讓你能將自訂概念或風格注入 AI 生成的圖像中。💡 這就像教會 AI 一個新詞彙,並將它與特定的視覺特徵建立關聯。
要在 ComfyUI 中使用 embedding,只需在提示詞欄位中輸入:
embedding:BadDream
ComfyUI 會在 ComfyUI > models > embeddings 資料夾中搜尋名為 BadDream 的 embedding 檔案。📂 一旦找到,它就會應用該 embedding 所對應的視覺風格到生成圖像中。
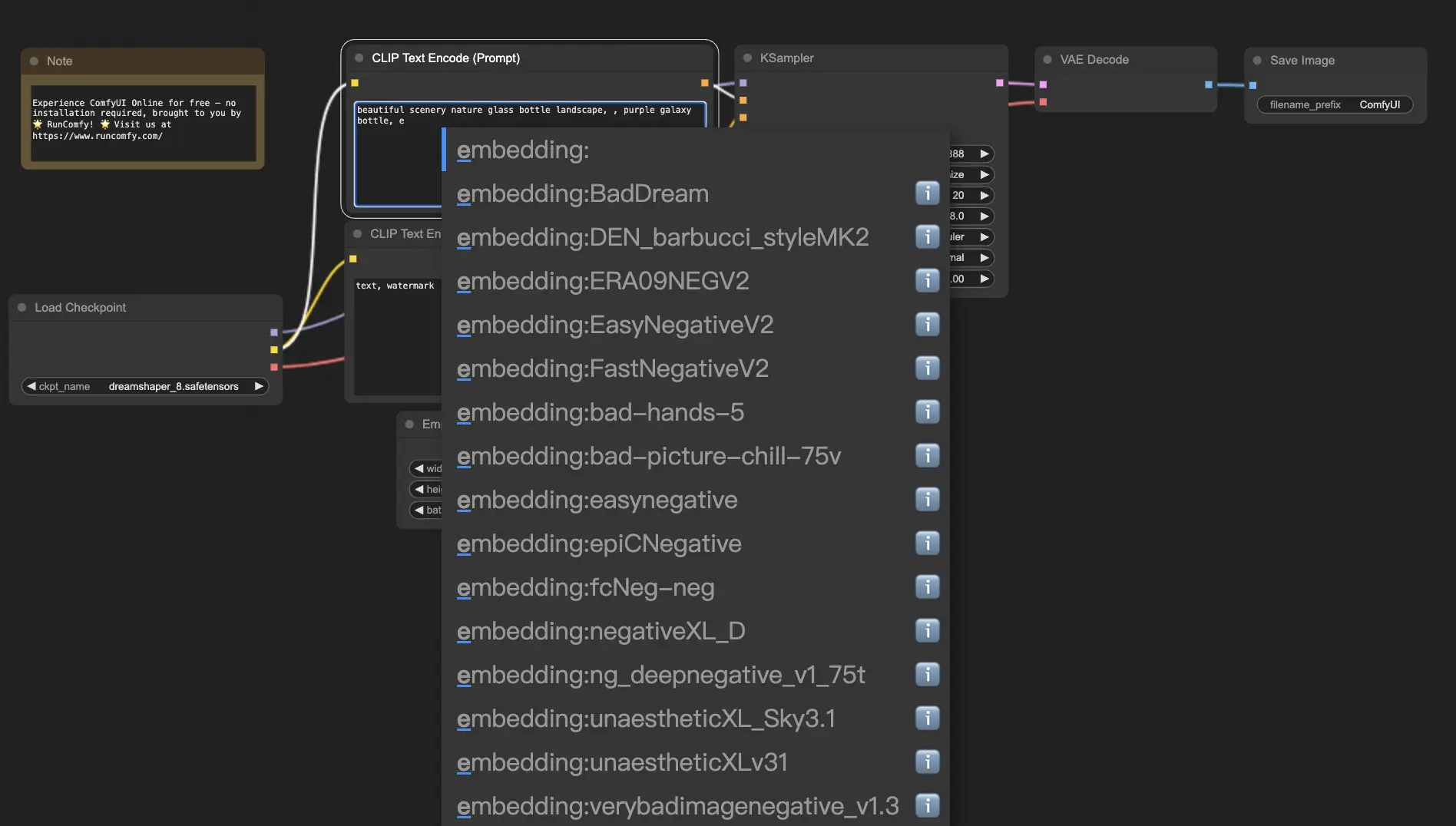
10.1. 帶自動補全的 Embedding 🔠#
記住所有 embedding 名稱有點困難,尤其當你安裝很多時。😅 這時候 ComfyUI-Custom-Scripts 自訂節點派上用場!
啟用 embedding 名稱自動補全:
- 點擊頂部選單的 Manager。
- 在 Install Custom Nodes 中搜尋
ComfyUI-Custom-Scripts。 - 點擊 Install。
- 重啟 ComfyUI。
安裝完成後,只要輸入 embedding:,就會自動顯示可用的選項列表,幫助你快速選取,節省寶貴時間與心力!
10.2. Embedding 權重 ⚖️#
你可以控制 embedding 的影響強度,就像控制提示詞權重一樣:
(embedding:BadDream:1.2)
這代表 BadDream 的權重為 1.2,影響力更強。若使用 0.8,則會降低其效果。🎚️ 此功能可微調生成結果,更符合你的藝術需求。
11. ComfyUI LoRA 🧩#
LoRA(Low-Rank Adaptation) 是 ComfyUI 的另一亮點,允許你在不修改整個 checkpoint 模型的前提下,針對特定風格或元素進行微調。🎨
當你將 LoRA 模型套用至 checkpoint 時,它會調整模型的 MODEL 與 CLIP 組件,而不影響 VAE,專注於圖像內容與風格的改變。
11.1. 如何使用 LoRA 🔧#
在 ComfyUI 中使用 LoRA 的基本步驟:
- 選擇一個 checkpoint 模型。
- 載入一個 LoRA 模型(如風格、角色等)。
- 編輯提示詞。
- 點擊 Queue Prompt 開始生成圖像。
11.2. 多個 LoRA 🧩🧩#
你可以在一個工作流中使用多個 LoRA 模型,ComfyUI 會依序應用它們的效果。
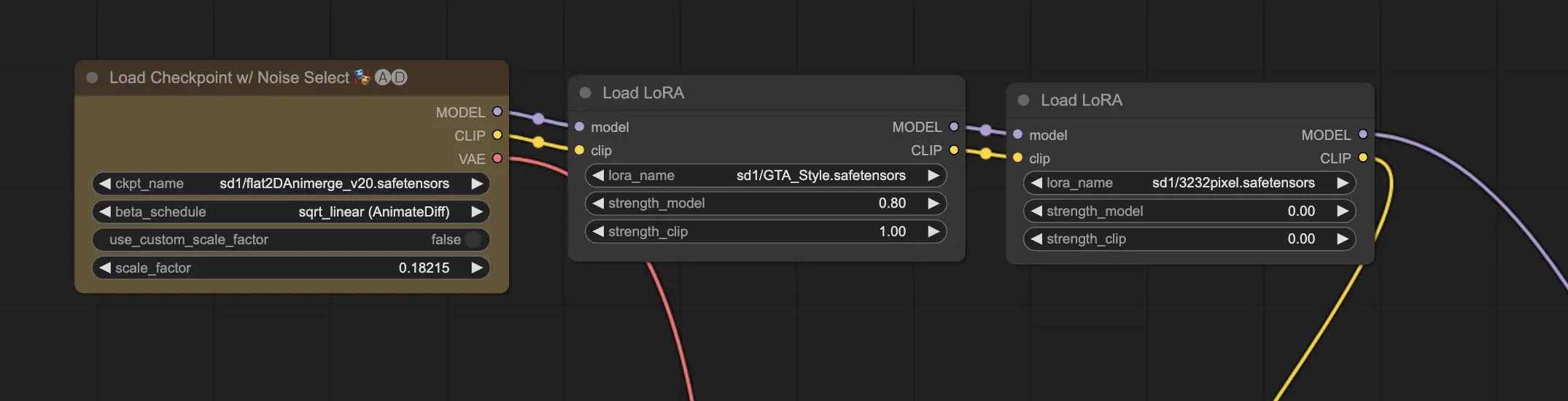
這樣可將多種風格與元素融合,激發創造力與實驗性,創造獨一無二的作品!🌍💡
12. ComfyUI 的快捷方式與技巧 ⌨️🖱️#
12.1. 複製與貼上 📋#
- 選取節點後按
Ctrl+C複製。 Ctrl+V貼上。Ctrl+Shift+V貼上但保留原有輸入連線。
12.2. 移動多個節點 🖱️#
- 使用群組移動節點。
- 按住
Ctrl拖曳來框選多個節點,或單獨多選。 - 按住
Shift並移動滑鼠來移動選取的所有節點。
12.3. 靜音節點 🔇#
- 選取節點按
Ctrl+M靜音,暫時停用該節點。 - 若要靜音整個群組,請右鍵選單中選擇 Bypass Group Node。
12.4. 最小化節點 🔍#
- 點擊節點左上角的圓點,即可最小化顯示。
12.5. 快速生成圖像 ▶️#
- 按
Ctrl+Enter加入佇列並立即開始生成。
12.6. 嵌入式工作流 🖼️#
- ComfyUI 可將整個工作流儲存於輸出圖像的 PNG metadata 中。
- 只需拖放圖片,即可還原完整工作流!
12.7. 固定種子以節省時間 ⏰#
- ComfyUI 只在輸入變化時重新執行節點。固定種子可避免重複運算,加快流程。
13. 在線使用 ComfyUI 🚀#
恭喜你完成本教學!🎉 你已具備使用 ComfyUI 創作 AI 藝術的完整基礎。
那麼,為何還要自行安裝呢?立即體驗我們預先配置的線上版本!
我們在 RunComfy 提供:
- 超過 200 個熱門節點與模型
- 超過 50 個範例工作流
- 不需安裝,直接創作!
🌟 無論你是剛入門或是資深創作者,RunComfy 都為你準備好了一切。快來體驗 AI 藝術的創作自由吧!🚀