
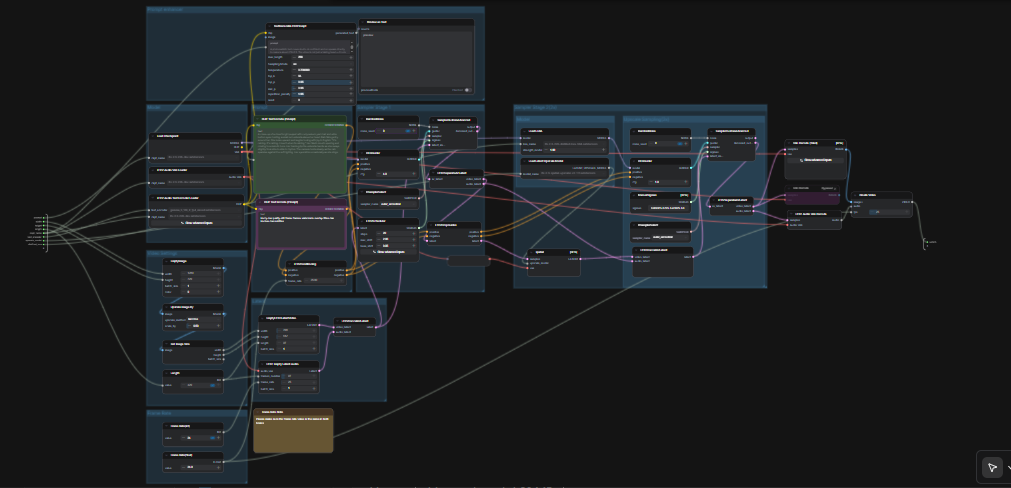
LTX 2.3 ComfyUI:文字轉視頻,帶有清晰音頻、雙階段採樣和 2× 空間升級#
這個 LTX 2.3 ComfyUI 工作流程將簡短提示轉化為精緻的電影級視頻,並配有同步音頻。它基於 Lightricks 的 LTX-2.3 模型構建,配置為高視覺一致性、穩定運動和廣播友好的輸出。創作者、編輯和技術藝術家可以從單一提示到帶音頻的 MP4,一次性完成,使用簡化的圖形,其中包括提示增強器、兩個採樣階段和一個 2× 潛在升級器。
與典型的文字轉視頻設置相比,此圖形強調場景一致性和提示保真度。默認路徑生成 AV 潛在,然後在潛在空間升級以獲得更清晰的細節,再解碼為幀和音頻,最後將所有內容打包成一個準備分享的視頻文件。如果您正在探索現代開源視頻模型,這個 LTX 2.3 ComfyUI 工作流程是一種快速獲得生產質量運動的方式。
Comfyui LTX 2.3 ComfyUI 工作流程中的關鍵模型#
- LTX-2.3 22B (dev) 檢查點由 Lightricks 提供。核心的文字轉視頻模型,產生高一致性的運動和強場景一致性。 Hugging Face • GitHub
- Gemma 3 12B 指令文本編碼器 (FP4 混合)。提供強大的語言理解,以更好地錨定提示並豐富場景細節。 Hugging Face
- LTX-2.3 空間升級器 x2 1.0。在不破壞運動一致性的情況下,銳化空間細節的潛在空間升級器。 Hugging Face
- LTX-2.3 22B 蒸餾 LoRA (384)。一個蒸餾適配器,在升級/精製階段中改善紋理保真度並穩定風格。 Hugging Face
- LTX 音頻 VAE。與 LTX-2.3 配對的音頻模塊,從相同提示生成清晰、同步的聲音。 Hugging Face
如何使用 Comfyui LTX 2.3 ComfyUI 工作流程#
此圖形在兩個協調的通過中運行。首先,它在工作分辨率下生成一個 AV 潛在,然後進行 2× 潛在升級和第二次採樣通過,使用蒸餾 LoRA,然後解碼為幀和音頻,最後合併為 MP4。
提示增強器#
TextGenerateLTX2Prompt (#149) 節點將普通語言重寫為模型友好的提示,涵蓋動作、視覺和音頻提示。將您的場景描述輸入其中;當您需要框架或風格指導時,可以連接可選的參考圖像。生成的文本被引導到正面編碼器,而質量導向的負面提示則保持工件減少。這種平衡有助於 LTX-2.3 模型保持簡短而不過度限制創意。
模型#
CheckpointLoaderSimple (#146) 加載 LTX-2.3 22B 檢查點,並暴露模型及其 VAE。LTXAVTextEncoderLoader (#147) 引入工作流程使用的 Gemma 3 12B 指令文本編碼器,用於正面和負面調節。除非您正在測試其他 LTX 變體,否則保持這些選擇,因為其餘圖形已經針對這種配對進行了調整。
視頻設置#
分辨率和持續時間由輕量級圖像支架和 Length 控制設置。圖形讀取圖像大小,按工作分辨率縮放,並將這些值轉發到視頻潛在創建器。LTX 模型有步幅限制;堅持遵循 32 步幅模式的大小和與模型幀節奏一致的長度。圖形會輕微調整非法值到最近的有效值,但提前選擇有效大小會產生最佳組合。
幀速率#
兩個小控件設置條件和最終編碼的 FPS:Frame Rate(int) (#141) 和 Frame Rate(float) (#140)。保持它們相同,以便在整個管道中保持運動時間和音頻對齊一致。選擇電影速率以獲得更平滑的運動,或在針對社交格式時匹配平台默認值。
潛在#
EmptyLTXVLatentVideo (#121) 初始化視頻潛在,LTXVEmptyLatentAudio (#119) 則為音頻做同樣的事情。LTXVConcatAVLatent (#122) 將它們合併為一個單一的 AV 潛在,以便文本指導可以共同引導兩種模式。LTXVConditioning (#120) 附加正面和負面調節,LTXVCropGuides (#115) 則適應潛在的空間佈局,以獲得更可靠的框架。
採樣階段 1#
此階段使用 RandomNoise (#151)、KSamplerSelect (#144) 和 LTX 感知的 LTXVScheduler (#112) 與 CFGGuider (#139) 創建初始 AV 潛在。調度器專為 LTX 調整,以平衡時間穩定性和提示遵從性。如果您想要更多變化,請更改噪聲種子;若想更穩定地遵循腳本,請偏好保持時間一致性的採樣器。
模型 (LoRA)#
LoraLoaderModelOnly (#143) 在精製前應用 LTX-2.3 蒸餾 LoRA。這個適配器微妙地改善了紋理拋光和風格保真度,而不會失去運動一致性。這在皮膚、織物和鏡面高光上最為明顯。
升級採樣 (2×)#
LTXVLatentUpsampler (#130) 使用加載的 LatentUpscaleModelLoader (#114) 和基礎 VAE 在潛在空間中執行 2× 空間升級。由於升級在解碼之前發生,您保留了時間平滑性,同時獲得了精細的空間細節。升級後的視頻和音頻潛在被重新與 LTXVConcatAVLatent (#129) 合併,用於精製過程。
採樣階段 2 (2×)#
第二次通過使用 RandomNoise (#127)、KSamplerSelect (#145) 和 ManualSigmas 調度 (#113) 在 CFGGuider (#116) 下精製升級的潛在。這個階段是微細節和邊緣銳度最終確定的地方。當 LoRA 活躍並且提示對紋理和照明具體時,它效果最好。
解碼和輸出#
LTXVSeparateAVLatent (#135) 分離精製的潛在,以便 VAEDecodeTiled (#137) 可以重建幀,而 LTXVAudioVAEDecode (#138) 恢復音頻。CreateVideo (#133) 以選定的 FPS 合併幀和音頻,頂級 SaveVideo 節點將 MP4 寫入工作流程的視頻文件夾。結果是一個乾淨的、準備分享的文件,完全在 LTX 2.3 ComfyUI 管道內生產。
Comfyui LTX 2.3 ComfyUI 工作流程中的關鍵節點#
TextGenerateLTX2Prompt(#149):將簡單描述轉換為結構化提示,涵蓋運動、視覺屬性和音頻。當引導故事節拍或節奏時,首先調整您的措辭;這通常比調整採樣器獲得更大的收益。LTXVScheduler(#112):一個 LTX 特定的調度器,塑造噪聲隨時間的去除方式。與您選擇的採樣器巧妙配合,以平衡時間穩定性和提示保真度。LTXVLatentUpsampler(#130):直接在潛在空間中執行 2× 空間升級,保留運動連續性,同時增加清晰的細節。當您想要更清晰的結果而不訴諸於後解碼升級器時使用它。LoraLoaderModelOnly(#143):應用 LTX-2.3 蒸餾 LoRA 以進行精製。增加影響力以獲得更緊密的風格控制;如果您希望基礎模型的更廣泛外觀,則減少它。CreateVideo(#133):將解碼的幀與生成的音頻在選定的 FPS 下合併,以便時間和口型同步保持完整。如果更改 FPS,保持兩個幀率控制一致。
可選附加項#
- 提示技巧:描述隨時間變化的動作,列出關鍵視覺元素,並指定您期望的聲音或對話。清晰、簡練的措辭為 LTX-2.3 編碼器提供最佳信號。
- 尺寸和長度:偏好遵循 32 步幅的大小和尊重模型幀節奏的長度。雖然圖形自動調整接近錯過的值,但有效的輸入改善組合並減少細微的抖動。
- 快速迭代:在運行之間更改
RandomNoise種子以探索變體,同時保持相同的提示和設置。 - 模型切換:默認值針對 LTX-2.3 22B 與 Gemma 3 12B IT 和 2× 空間升級器進行了調整。只有在您了解每個模型如何影響調節和解碼時,才交換模型。
致謝#
此工作流程實現並構建於以下作品和資源之上。我們感謝 Lightricks 提供的 LTX-2.3 模型和 EyeForAILabs 提供的 YouTube 教程的貢獻和維護。欲了解權威細節,請參考下列鏈接的原始文檔和存儲庫。
資源#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: 2601.03233
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: YouTube Channel from @eyeforailabs
注意:使用參考的模型、數據集和代碼需遵守其作者和維護者提供的相關許可和條款。
