
Hunyuan Video 是一个开源基础模型,通过提供尖端的文本到视频生成能力,挑战了闭源系统的主导地位。基于大规模数据管理、适应性架构设计和优化基础设施的创新,Hunyuan Video 在视觉质量上设定了新的基准。
虽然 Hunyuan Video 主要专注于文本到视频生成,但 Hunyuan IP2V 工作流程通过同一模型将图像和文本提示转换为动态视频,扩展了这一能力。这种方法使用户能够使用视觉参考引导内容创作,提供了一种替代的 AI 驱动内容生产方法。
通过将图像与提示结合,Hunyuan IP2V 在保留输入关键特征的同时生成运动,使其成为 AI 动画、概念可视化和艺术叙事的有用工具。无论是制作动态场景、风格化运动,还是将静态视觉扩展为动画序列,Hunyuan Video 的框架都提供了通往高质量结果的高效途径。
如何使用 Hunyuan Video - IP2V 工作流程?#
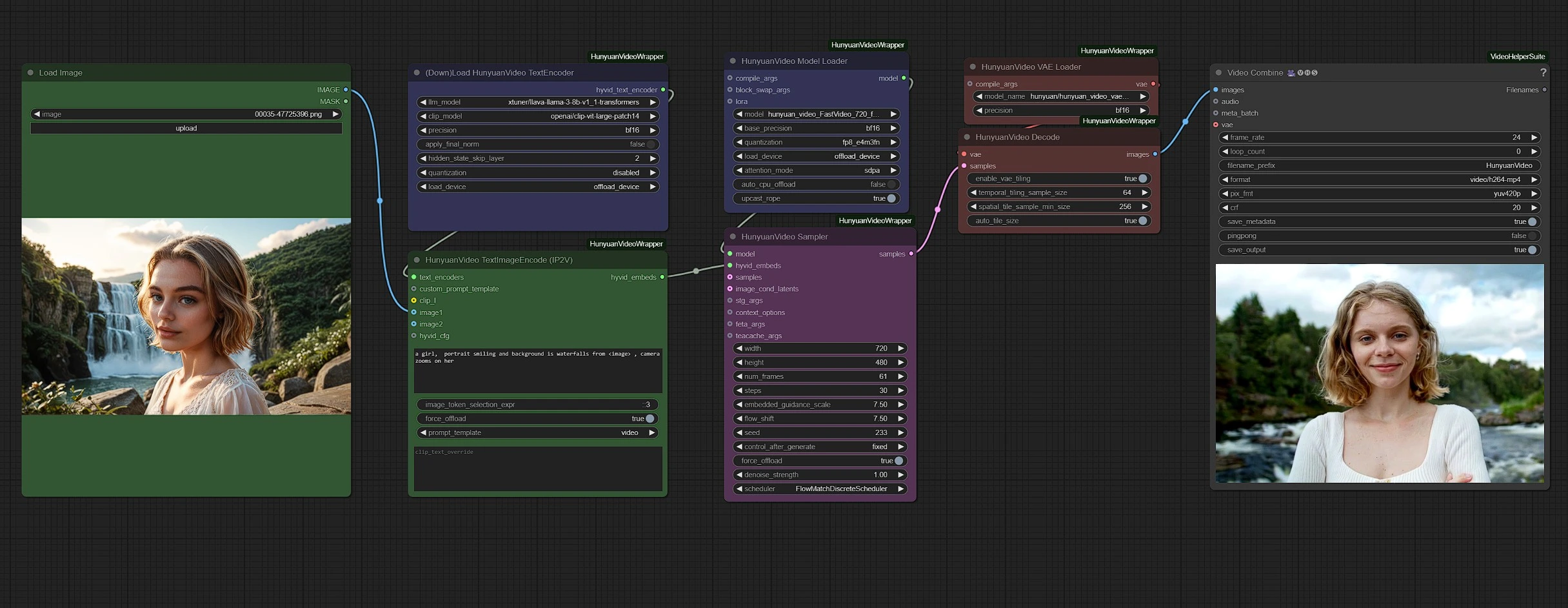
组根据颜色编码以便于清晰:
- 绿色 - 输入
- 紫色 - 模型
- 粉色 - Hunyuan Sampler
- 红色 - VAE + 解码
- 灰色 - 输出
在绿色节点中上传您的输入(图像和文本),并在粉色采样节点中调整视频设置,例如持续时间和分辨率。
输入 1 - 图像#
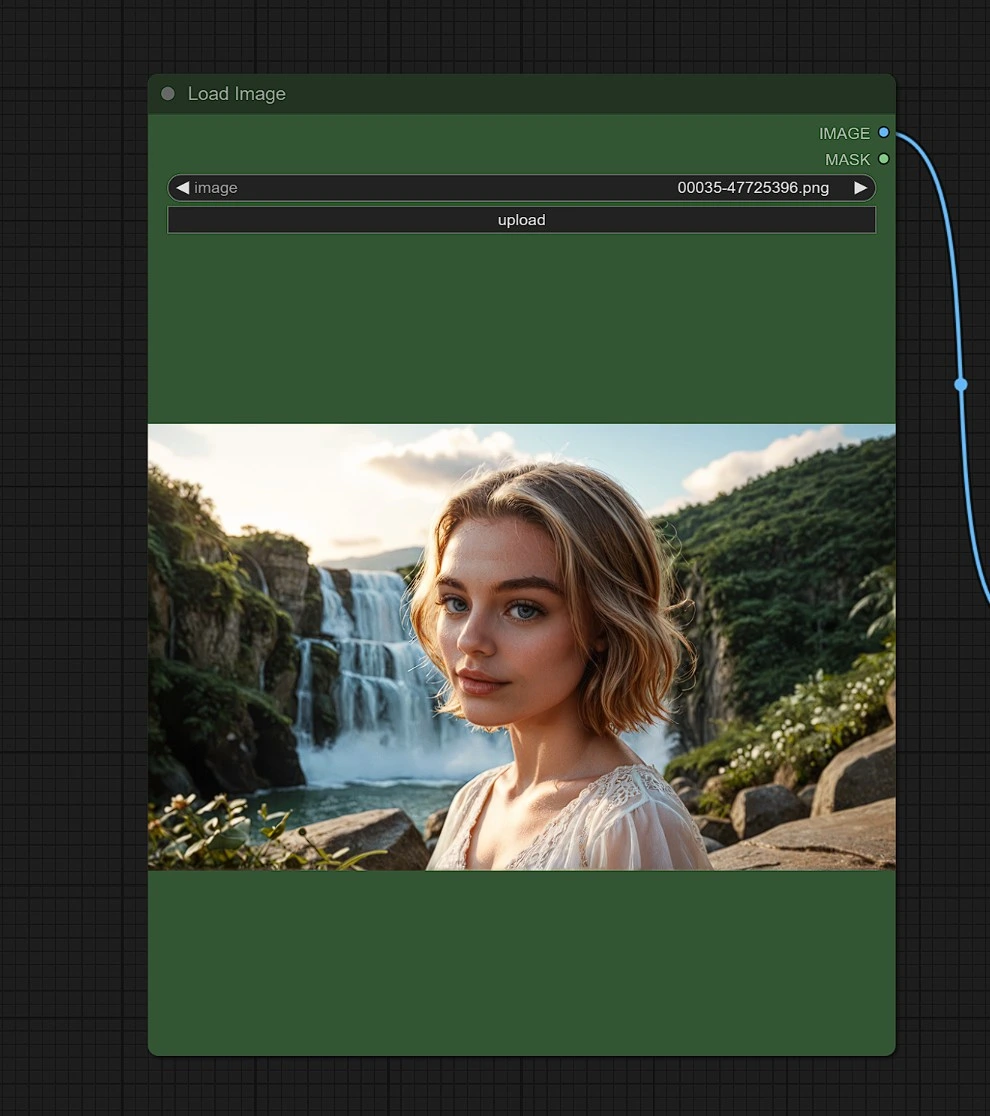
上传一张图像以参考您希望获得相似结果的地点、人物或对象。
输入 2 - 文本#
在第一个文本框中输入您的提示,并使用关键字 "<image>" 包含图像。
例如,如果您的输入是 "empty street" 并且您想添加一位女性,提示将是:"A portrait of a woman, background is <image>."
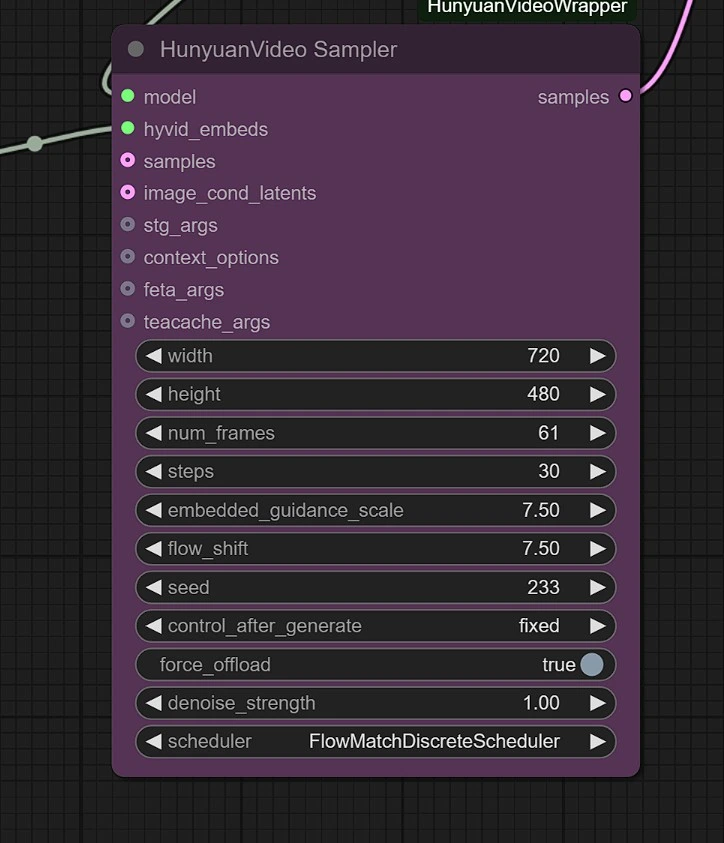
采样器#
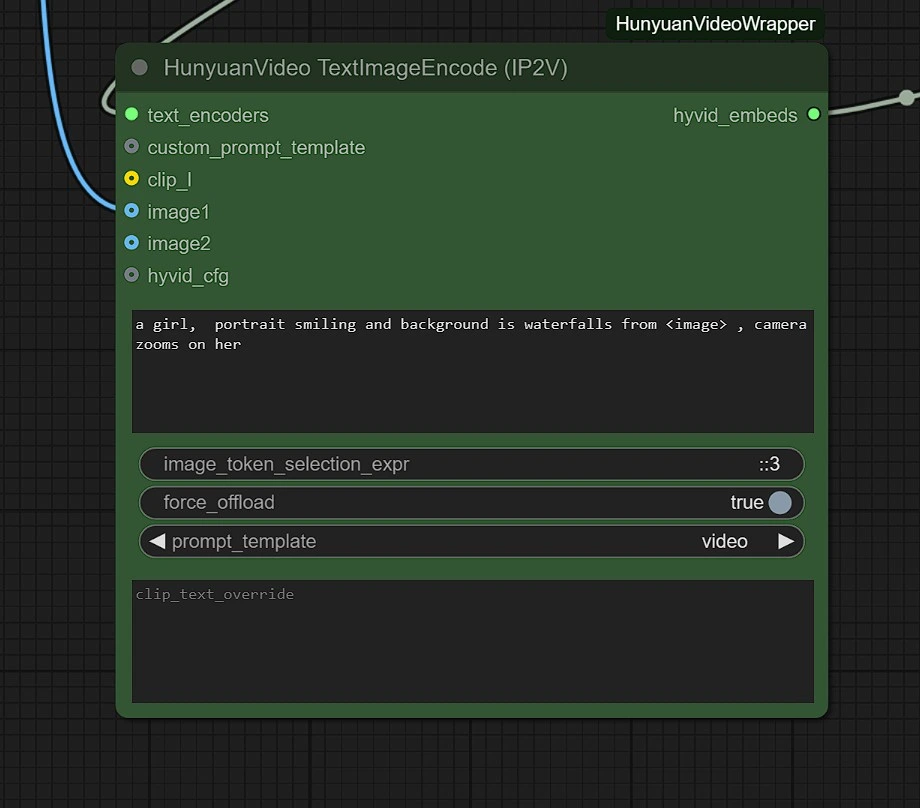
您可以调整以下内容:
- 图像分辨率 - 最大为 1280px 720px ,需要更多的 VRAM。
- 帧数 - 这设置帧数(24 帧 = 1 秒)。
模型#
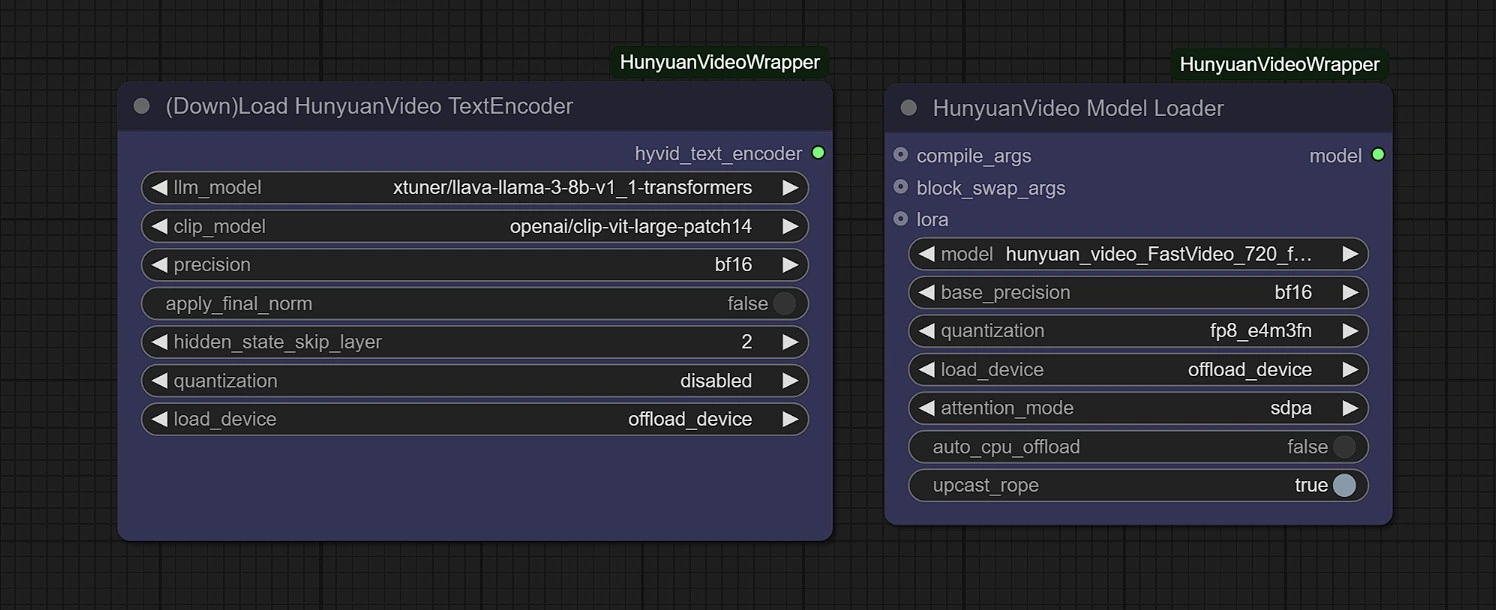
在此组中,模型将在第一次运行时自动下载。请允许 3-5 分钟以完成下载到您的临时存储中。
链接:
- Diffusion: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors
- ComfyUI > models > diffusion_models
- Vae: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_vae_bf16.safetensors
- ComfyUI > models > vae
输出#
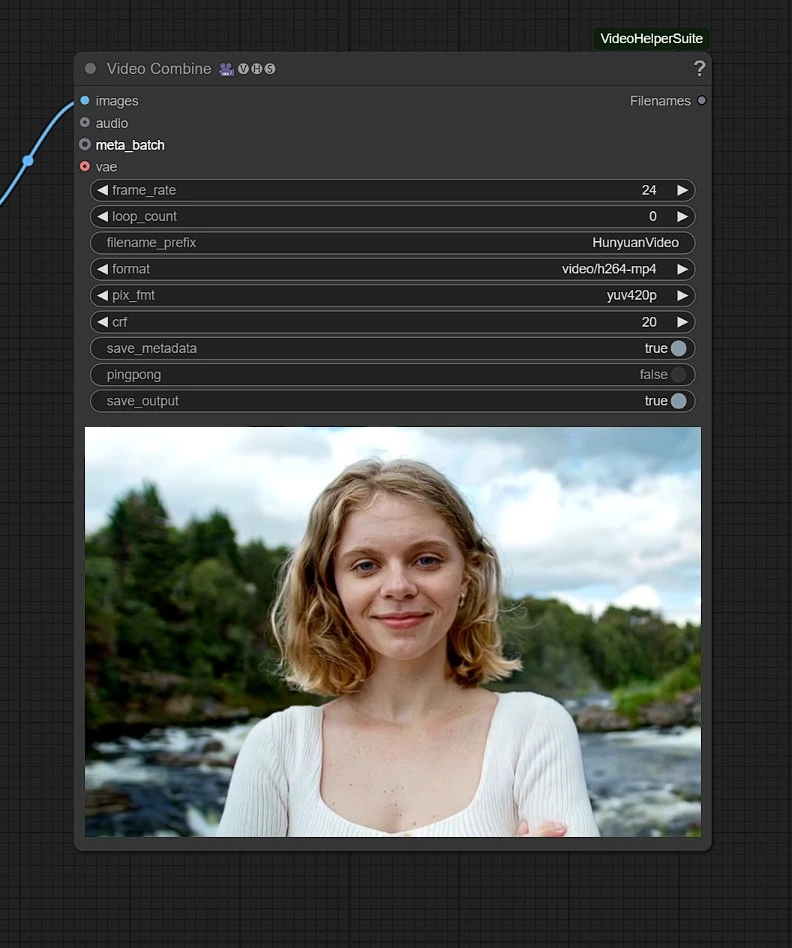
渲染的视频将保存在 Comfyui 的输出文件夹中。
通过 Hunyuan IP2V 工作流程,您现在不仅限于基于文本的视频生成,您可以赋予图像生命,赋予运动和风格。无论是用于 AI 电影制作、数字艺术或创造性叙事,此工作流程都赋予您比以往更多的控制权来塑造您的愿景。