
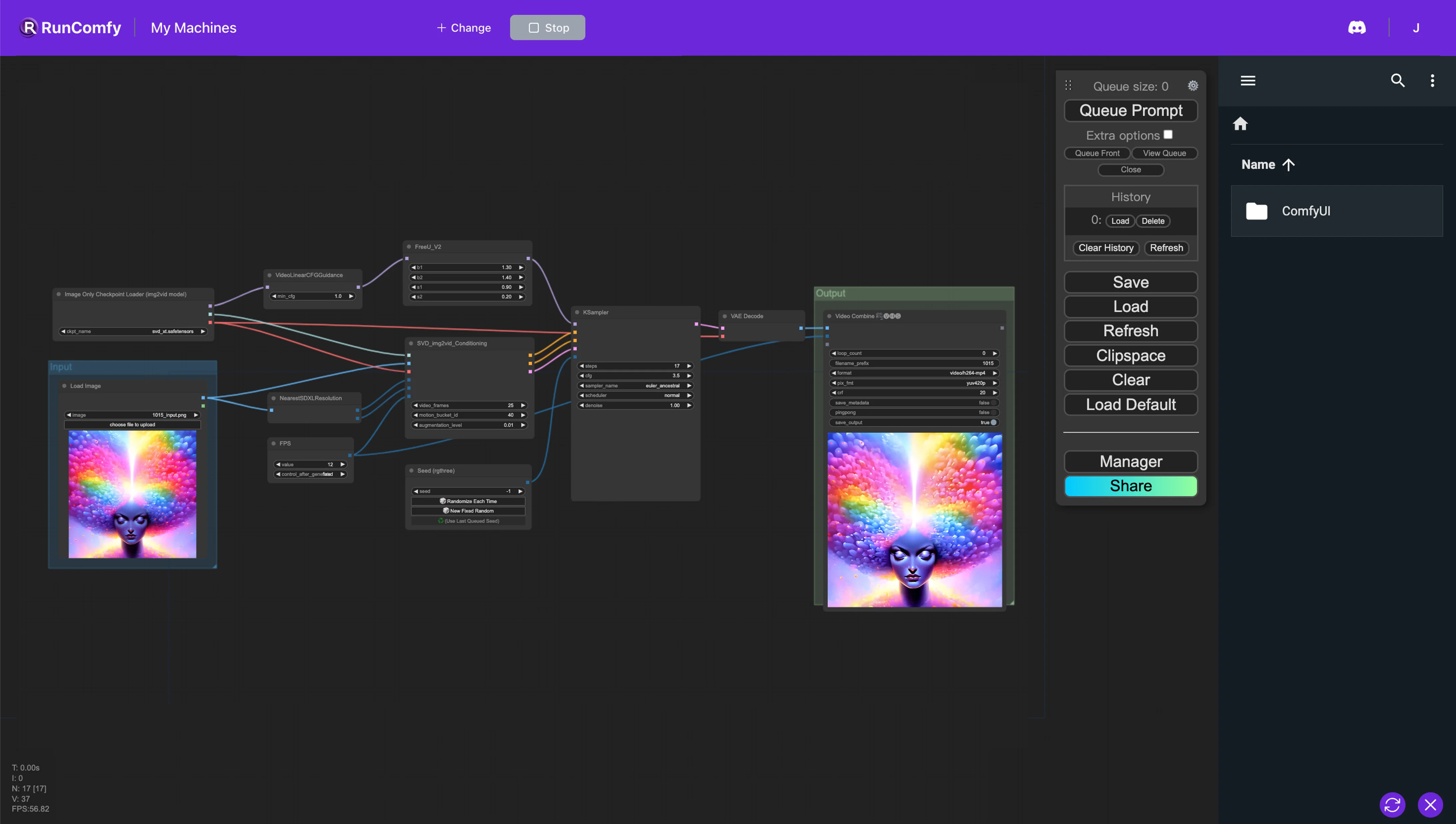
1. ComfyUI 稳定视频扩散 (SVD) 和 FreeU 工作流程#
这个 ComfyUI 工作流程通过利用稳定视频扩散 (SVD) 和 FreeU 来优化图像到视频的转换流程,从而提高输出质量。FreeU 可以在不产生额外开销的情况下提升扩散模型的结果——无需重新训练、参数增强或增加内存或计算时间。这种集成可确保您能够在视频输出中获得更高的保真度。
2. 稳定视频扩散 (SVD) 概述#
请查看 SVD 简介 了解详情
3. FreeU 概述#
请查看 FreeU 简介 了解详情
RunComfy 是首选的 ComfyUI 平台,提供 ComfyUI 在线 环境和服务,以及 ComfyUI 工作流 具有惊艳的视觉效果。 RunComfy还提供 AI Models, 帮助艺术家利用最新的AI工具创作出令人惊叹的艺术作品。