
Character AI Ovi:在ComfyUI中将图像转为视频并同步语音#
Character AI Ovi是一个视听生成工作流程,可以将单张图像转变为具有协调声音的会说话和移动的角色。基于Wan模型家族并通过WanVideoWrapper集成,它在一次通过中生成视频和音频,提供富有表现力的动画、清晰的唇形同步和上下文感知的氛围。如果您创作短篇故事、虚拟主持人或电影社交片段,Character AI Ovi可以让您在几分钟内从静态艺术到完整的表演。
这个ComfyUI工作流程接受一张图像加上一个包含轻量级标记的文本提示用于语音和声音设计。它将帧和波形一起组合,使嘴巴、节奏和场景音频感觉自然对齐。Character AI Ovi专为希望获得精致结果的创作者设计,无需拼接单独的TTS和视频工具。
Comfyui Character AI Ovi工作流程中的关键模型#
- Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation. 核心模型从文本或文本+图像提示中联合生成视频和音频。 character-ai/Ovi
- Wan 2.2视频骨干和VAE。工作流程使用Wan的高压缩视频VAE有效生成720p、24 fps的视频,同时保留细节和时间一致性。 Wan-AI/Wan2.2-TI2V-5B-Diffusers • Wan-Video/Wan2.2
- Google UMT5-XXL文本编码器。对包含语音标记的提示进行编码,生成丰富的多语言嵌入,用于驱动两个分支。google/umt5-xxl
- MMAudio VAE与BigVGAN声码器。将模型的音频潜变量解码为高质量的语音和效果,具有自然音色。 hkchengrex/MMAudio • nvidia/bigvgan_v2_44khz_128band_512x
- Kijai提供的ComfyUI-ready Ovi权重。为视频分支、音频分支和VAE提供的精选检查点,具有bf16和fp8缩放变体。Kijai/WanVideo_comfy/Ovi • Kijai/WanVideo_comfy_fp8_scaled/TI2V/Ovi
- ComfyUI的WanVideoWrapper节点。将Wan和Ovi功能暴露为可组合的节点。kijai/ComfyUI-WanVideoWrapper
如何使用Comfyui Character AI Ovi工作流程#
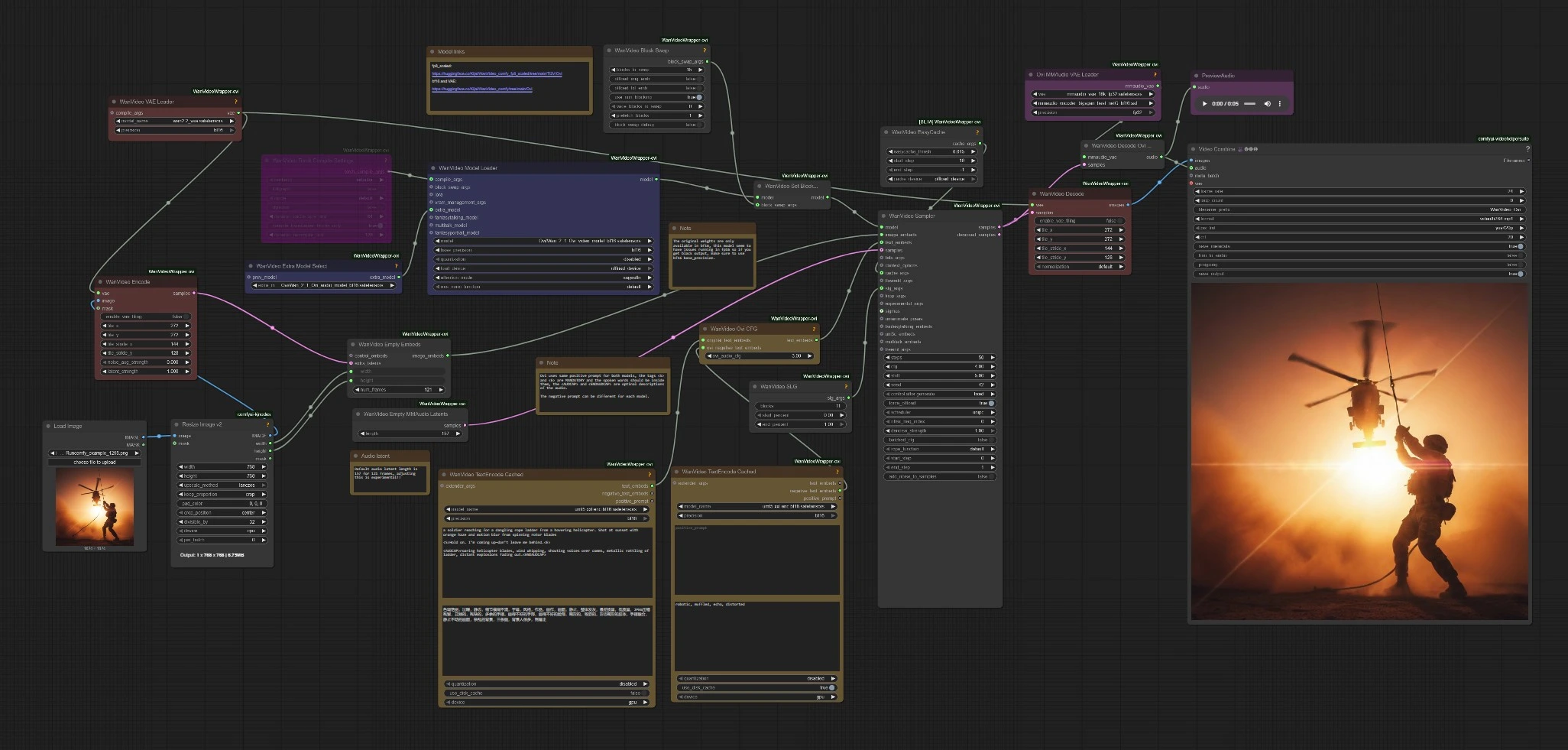
该工作流程遵循简单路径:编码您的提示和图像,加载Ovi检查点,采样联合音频+视频潜变量,然后解码并复用为MP4。以下小节映射到可见的节点集群,以便您知道在哪里进行交互以及哪些更改会影响结果。
语音和声音的提示创作#
为场景和说话的台词撰写一个正面提示。使用Ovi标签正如所示:将要说的话用<S>和<E>包裹,并可选地用<AUDCAP>和<ENDAUDCAP>描述非语音音频。同一个正面提示同时控制视频和音频分支,因此唇形动作和时间匹配。您可以对视频和音频使用不同的负面提示,以独立抑制伪影。Character AI Ovi对简洁的舞台指令加上一行清晰的对话反应良好。
图像摄取和条件设置#
加载一张肖像或角色图像,然后工作流程将其调整大小并编码为潜变量。这建立了采样器的身份、姿势和初始框架。调整大小阶段的宽度和高度设定了视频纵横比;选择方形用于化身或竖直用于短片。编码的潜变量和图像派生的嵌入指导采样器,使动作感觉锚定在原始面孔上。
模型加载和性能助手#
Character AI Ovi加载三个基本要素:Ovi视频模型、用于帧的Wan 2.2 VAE和用于音频的MMAudio VAE加上BigVGAN。包括Torch编译和轻量级缓存以加速暖启动。一个块交换助手接入以通过在需要时卸载transformer块来降低VRAM使用。如果您受VRAM限制,请在块交换节点中增加块卸载,并在重复运行时保持缓存启用。
带指导的联合采样#
采样器同时运行Ovi的双主干,因此配乐和帧共同进化。一个跳过层指导助手在不牺牲运动的情况下提高了稳定性和细节。工作流程还通过Ovi特定的CFG混合器引导您的原始文本嵌入,因此您可以在严格的提示遵循和更自由的动画之间倾斜平衡。当说话的台词简短、字面且仅用<S>和<E>标签包围时,Character AI Ovi倾向于产生最佳的唇形动作。
解码、预览和导出#
采样后,视频潜变量通过Wan VAE解码,而音频潜变量通过MMAudio和BigVGAN解码。一个视频合成器将帧和音频复用为每秒24帧的MP4,准备分享。您还可以直接预览音频以验证语音的清晰度,然后再保存。Character AI Ovi的默认路径目标是5秒;谨慎延长以保持唇形和节奏同步。
Comfyui Character AI Ovi工作流程中的关键节点#
WanVideoTextEncodeCached(#85)
将主要的正面提示和视频负面提示编码为两个分支使用的嵌入。将对话放在<S>…<E>中,将声音设计放在<AUDCAP>…<ENDAUDCAP>中。为了最佳对齐,避免在一个语音标签中出现多个句子,并保持台词简洁。
WanVideoTextEncodeCached(#96)
为音频提供专用的负面文本嵌入。用它来抑制如机器人音调或重混响等伪影,而不影响视觉。先从简短描述开始,只有在仍然听到问题时才扩展。
WanVideoOviCFG(#94)
通过Ovi感知的无分类指导将原始文本嵌入与音频特定的负面混合。当语音内容偏离书面台词或唇形动作感觉不协调时提高它。如果动作变得僵硬或过于受限,稍微降低它。
WanVideoSampler(#80)
Character AI Ovi的核心。它消耗图像嵌入、联合文本嵌入和可选指导以采样包含视频和音频的单个潜变量。更多步骤增加保真度,但也增加运行时间。如果您看到内存压力或停滞,请将块交换与缓存配对,并考虑禁用Torch编译以快速排除故障。
WanVideoEmptyMMAudioLatents(#125)
初始化音频潜变量时间线。默认长度调整为121帧、24 fps的剪辑。调整此以更改持续时间是实验性的;只有在了解它如何必须跟踪帧数时才更改。
VHS_VideoCombine(#88)
将解码的帧和音频复用为MP4。设置帧率以匹配您的采样目标,并切换到音频以使最终剪辑跟随生成的波形。使用CRF控制来平衡文件大小和质量。
可选附加项#
- 对Ovi视频和Wan 2.2 VAE使用bf16。如果遇到黑帧,请将模型加载器和文本编码器的基准精度切换为
bf16。 - 保持台词简短。Character AI Ovi在短小、单句对话置于
<S>和<E>中时最能可靠地同步口型。 - 分开负面。将视觉伪影放在视频负面提示中,将音调伪影放在音频负面提示中,以避免意外的权衡。
- 先预览。使用音频预览来确认清晰度和节奏,然后再导出最终的MP4。
- 获取使用的确切权重。工作流程期望来自Kijai的模型镜像的Ovi视频和音频检查点以及Wan 2.2 VAE。WanVideo_comfy/Ovi • WanVideo_comfy_fp8_scaled/TI2V/Ovi
有了这些组件,Character AI Ovi成为一个紧凑、创作者友好的管道,适用于表现力丰富的会说话的化身和听起来和看起来一样好的叙述场景。
致谢#
此工作流程实现并建立在以下作品和资源之上。我们感谢kijai和Character AI对Ovi的贡献和维护。有关权威细节,请参阅下面链接的原始文档和资源库。
资源#
- Character AI Ovi Source
- Workflow: wanvideo_2_2_5B_ovi_testing @kijai
- Github: character-ai/Ovi
注意:所引用的模型、数据集和代码的使用受其作者和维护者提供的相应许可和条款的约束。
