
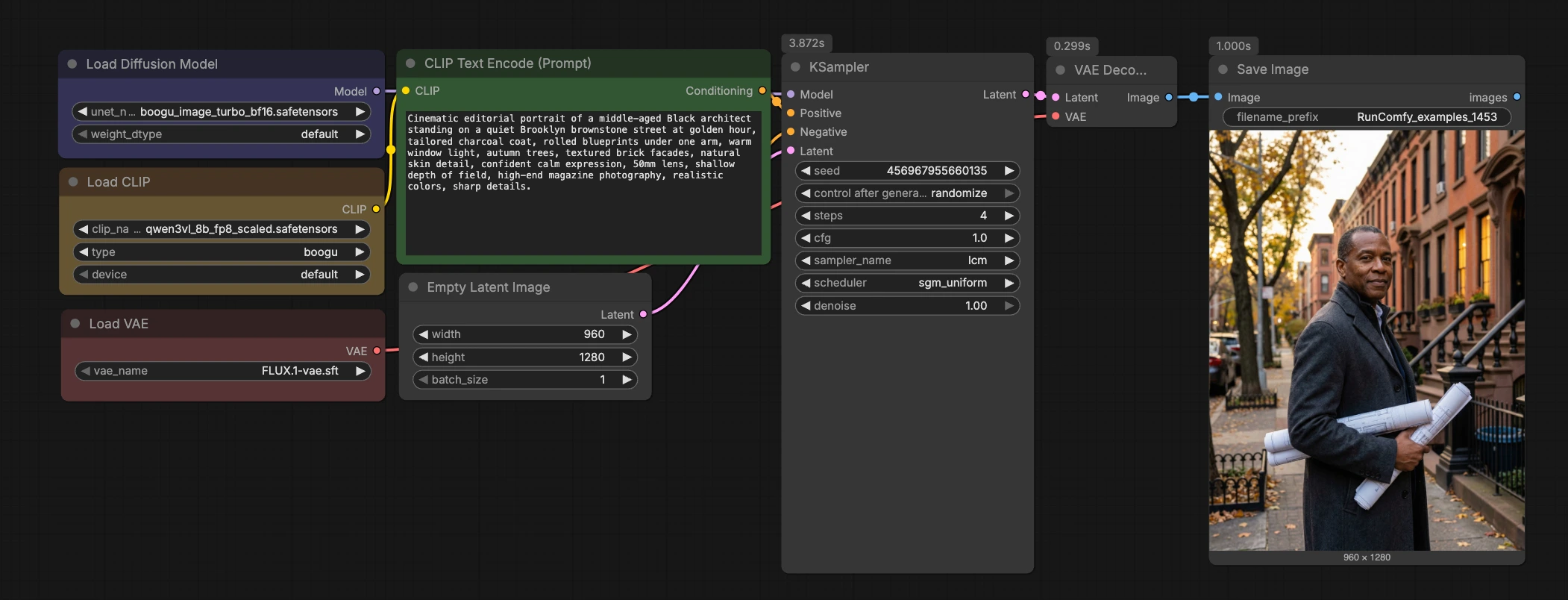






Boogu Turbo 文本到图像 ComfyUI 工作流#
这个 Boogu Turbo 文本到图像 ComfyUI 工作流是一个从提示到图像的清晰快速路径,使用 Boogu-Image-0.1-Turbo 检查点和四步 LCM 采样。它将 Qwen3-VL 文本编码器与 FLUX.1 VAE 配对,以便您可以快速迭代,同时保持图形最小化且易于在项目间重用。
设计用于快速视觉探索,工作流在电影环境、动漫风格背景、氛围风景、富有想象力的产品机器和建筑场景中表现出色。如果您想要一个轻量级的 Boogu Turbo 文本到图像 ComfyUI 工作流,且已为 RunComfy 准备好并易于检查,此模板是一个坚实的起点。
Comfyui Boogu Turbo 文本到图像 ComfyUI 工作流中的关键模型#
- Boogu-Image-0.1-Turbo。经过提炼的 Turbo 变体构建用于快速、真实感的文本到图像,典型的 3–4 步推理和接近 1.0 的引导尺度。官方模型权重和说明在 Hugging Face 上可用,Comfy-Org 提供 ComfyUI 准备好的重新打包文件。请参见 Boogu/Boogu-Image-0.1-Turbo-fp8 和 ComfyUI 精选包 Comfy-Org/Boogu-Image。
- Qwen3-VL 8B 文本编码器。这个现代视觉语言骨干在此仅用作文本编码器,为扩散模型生成强大的提示嵌入。ComfyUI 打包的编码器托管在 Comfy-Org/Qwen3-VL,官方库在 QwenLM/Qwen3-VL。
- FLUX.1 VAE。来自 Black Forest Labs 的自动编码器在像素和潜在空间之间编码和解码图像,帮助保留色彩和对比度的保真度。参考权重和文档在 black-forest-labs/FLUX.1-dev。
如何使用 Comfyui Boogu Turbo 文本到图像 ComfyUI 工作流#
总览,工作流对您的提示进行编码,初始化潜在画布,通过 Boogu-Image-0.1-Turbo 运行快速 LCM 采样器,使用 FLUX.1 VAE 解码并保存结果。图形故意紧凑,因此您可以将其放入其他项目中或通过 LoRAs、ControlNets 或后处理链进行扩展。
使用 Qwen3-VL 进行提示编码 (CLIPLoader (#7) → CLIPTextEncode (#11))#
此阶段加载 Qwen3-VL 编码器并将您的文本提示转换为条件向量。在 CLIPTextEncode (#11) 中输入您的提示,使用自然语言;详细的摄影提示如镜头、照明、一天中的时间和纹理效果良好。负输入通过 ConditioningZeroOut (#9) 故意清零,以保持 Turbo 的低引导机制下结果的稳定性。如果您更喜欢显式的负面,替换 ConditioningZeroOut 为第二个 CLIPTextEncode 以提供负面提示。良好的提示卫生在此可以减少后续需要高 CFG 或额外步骤的需求。
潜在设置和模型加载 (EmptyLatentImage (#8) + UNETLoader (#2))#
EmptyLatentImage (#8) 创建潜在画布。默认的 960×1280 纵向比例是人物、室内和高产品拍摄的平衡起点;您可以为正方形或宽屏设置其他尺寸。UNETLoader (#2) 从 Comfy-Org 包加载 Boogu Turbo 扩散权重,将模型与您选择的编码器和 VAE 对齐。如果您需要平衡 VRAM 和吞吐量,交换 BF16 和 FP8 变体是简单的。保持模型选择在项目中一致以维护风格的连续性。
快速 LCM 采样 (KSampler (#32) 使用采样器 lcm)#
KSampler 配置为潜在一致性模型以在大约四步内达到高质量。LCM 蒸馏目标是非常低的引导值,这就是为什么这个 Boogu Turbo 文本到图像 ComfyUI 工作流在 CFG 约为 1.0 时稳定运行,同时保持提示的遵循性。如果您想要更多微观细节,适度增加步骤并固定种子以进行 A/B 比较。对于风格或构图更改,重新滚动种子并完善提示而不是将步骤推得太高。关于 LCM 少步推理的背景理论在原始论文 Latent Consistency Models 中描述。
解码和保存 (VAELoader (#5) → VAEDecode (#3) → SaveImage (#58))#
在 VAELoader (#5) 中加载的 FLUX.1 VAE 在 VAEDecode (#3) 中将潜在解码为 RGB。将 VAE 家族与您的扩散骨干匹配通常会产生更忠实的颜色和纹理,这就是为什么此图形附带 FLUX.1 VAE。SaveImage (#58) 将结果写入磁盘;更改输出前缀以按提示、种子或纵横比组织实验。如果您以后连接缩放器或后期效果,从 VAEDecode 的 Image 输出分支以保留干净的历史。
Comfyui Boogu Turbo 文本到图像 ComfyUI 工作流中的关键节点#
CLIPTextEncode (#11)#
此节点容纳您的主要文本提示并生成采样器使用的正条件。保持提示简洁,并添加场景提示,如相机焦距、一天中的时间和材料形容词。如果您想使用负面提示,创建第二个 CLIPTextEncode 并将其连接到采样器的负输入,移除 ConditioningZeroOut (#9)。
ConditioningZeroOut (#9)#
通过向采样器的负端口馈入零向量来禁用负条件。在 Turbo 的低引导配置中保留它是一个很好的默认设置。仅在您明确需要负面提示且能够清晰表达时才移除它。
EmptyLatentImage (#8)#
控制输出尺寸和批量大小。对于肖像从 960×1280 开始,或对于更宽的环境从 1280×960 开始;根据主题和内存预算进行调整。较大的潜在提供更多画布用于细节,但会增加 VRAM 使用量和解码时间。
UNETLoader (#2)#
选择用于生成的 Boogu-Image-0.1-Turbo 检查点。在高内存 GPU 上使用 BF16 变体以获得最高保真度,或使用 FP8 变体以降低 VRAM 并加快加载速度,均在 Comfy-Org 包中可用。模型文件及其预期文件夹在 Comfy-Org/Boogu-Image 中记录。
KSampler (#32)#
使用 lcm 采样器运行扩散过程以进行少步推理。关键杠杆是种子、步骤数和 CFG;Turbo 设计用于在非常低的引导和少量步骤下运行,同时保持质量,这在官方 Turbo 设置中反映在模型卡上 Boogu/Boogu-Image-0.1-Turbo-fp8 中。对于受控探索,固定种子并一次改变步骤或提示措辞。
VAELoader (#5) 和 VAEDecode (#3)#
加载并应用 FLUX.1 VAE 进行解码。坚持使用 FLUX.1 家族保持颜色、对比度和纹理行为与 UNet 的训练设置一致。混合 VAE 是可能的,但可能会微妙地改变色调或饱和度;在承诺新的外观之前进行测试。参考权重:black-forest-labs/FLUX.1-dev。
SaveImage (#58)#
控制输出命名和目标。使用有意义的前缀,如项目名称、纵横比标签或种子以保持运行的组织。在扩展管道时,在此分支以添加缩放器、色彩分级或字幕而不破坏基本保存。
可选附加项#
- 保持 CFG 接近 1.0 且步骤约为四以获得最快的迭代;仅在需要更多纹理或稳定性时移动到 6–8 步。
- 重新滚动种子以探索构图;固定种子以微调风格和微观细节。
- 在高内存 GPU 上使用 BF16 权重以获得最佳质量;切换到 FP8 以加快加载速度并减少 VRAM。
- 对于图像中的文本可读性,尝试稍高的分辨率并在提示中包含明确的排版提示。
- 经常保存中间收藏;这个 Boogu Turbo 文本到图像 ComfyUI 工作流中的小提示微调可以在几秒钟内产生有意义的不同场景。
致谢#
此工作流实现并构建在以下作品和资源之上。我们诚挚地感谢 RunningHub 提供的工作流参考,Boogu 提供的 Boogu-Image 仓库和 Boogu-Image-0.1-Turbo 模型,Comfy-Org 提供的 Boogu ComfyUI 权重,以及 ComfyUI 提供的 Boogu 教程对他们的贡献和维护。有关权威的详细信息,请参考以下链接的原始文档和库。
资源#
- RunningHub/工作流参考
- 文档 / 发布说明:RunningHub post
- Boogu/项目网站
- 文档 / 发布说明:boogu.org
- Boogu/Boogu Image 仓库
- GitHub: boogu-project/Boogu-Image
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- Boogu/Boogu-Image-0.1-Turbo 模型
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- GitHub: boogu-project/Boogu-Image
- Comfy-Org/Boogu ComfyUI 权重
- Hugging Face: Comfy-Org/Boogu-Image
- ComfyUI/Boogu 教程
- 文档 / 发布说明:ComfyUI tutorial
注意:所引用的模型、数据集和代码的使用受其作者和维护者提供的各自许可证和条款的约束。



