
LTX 2.3 Dual Character Lip Sync LoRA: vídeo de sincronização labial de dois personagens a partir de uma imagem e uma faixa de áudio#
Este fluxo de trabalho do ComfyUI transforma uma única imagem estática e uma conversa gravada de dois falantes em um vídeo coerente, com identidade estável e fala sincronizada para ambos os personagens na tela. Construído em torno da base de vídeo LTX‑2.3 e do LTX 2.3 Dual Character Lip Sync LoRA, ele mapeia fonemas e tempo do seu diálogo para cada rosto enquanto preserva expressões, olhar e consistência de cena entre os quadros.
Projetado para entrevistas, diálogos cinematográficos, podcasts com apresentadores de vídeo e interações de personagens virtuais, o fluxo de trabalho combina prompts de texto para layout de cena com movimento impulsionado por áudio. Inclui uma etapa de inicialização de imagem para desenvolvimento rápido de aparência, amostragem em duas etapas LTX para estabilidade temporal e um upscaler latente para resultados nítidos. O resultado final é um MP4 com áudio incorporado.
Modelos principais no fluxo de trabalho Comfyui LTX 2.3 Dual Character Lip Sync LoRA#
- Modelo de geração de vídeo LTX‑2.3. Fornece a base de difusão multimodal que sintetiza vídeo temporalmente consistente condicionado em texto, imagem e áudio. Lightricks/LTX-2.3
- LTX‑2.3 Video VAE e Audio VAE. Codificam e decodificam latentes de vídeo e áudio usados pelo modelo para manter a geração eficiente e sincronizada. Enviado com o lançamento LTX‑2.3. Lightricks/LTX-2.3
- Upscaler latente espacial LTX. Refina detalhes após a passagem base ao aumentar a escala no espaço latente para texturas e bordas mais limpas. Variantes estão disponíveis junto com os ativos LTX. Lightricks/LTX-2
- LTX 2.3 Dual Character Lip Sync LoRA. Injeta treinamento que incentiva o movimento labial por falante e o tempo para dois rostos no mesmo quadro enquanto mantém a identidade facial.
- Modelo de texto para imagem Z‑Image Turbo. Produz rapidamente uma referência estática de alta qualidade que ancora identidade, enquadramento e iluminação antes da síntese de vídeo. Comfy‑Org/z_image_turbo
Pacotes de nós relacionados usados por este fluxo de trabalho: ComfyUI‑KJNodes, ComfyUI‑VideoHelperSuite, rgthree‑comfy, e ComfyUI‑PromptRelay.
Como usar o fluxo de trabalho Comfyui LTX 2.3 Dual Character Lip Sync LoRA#
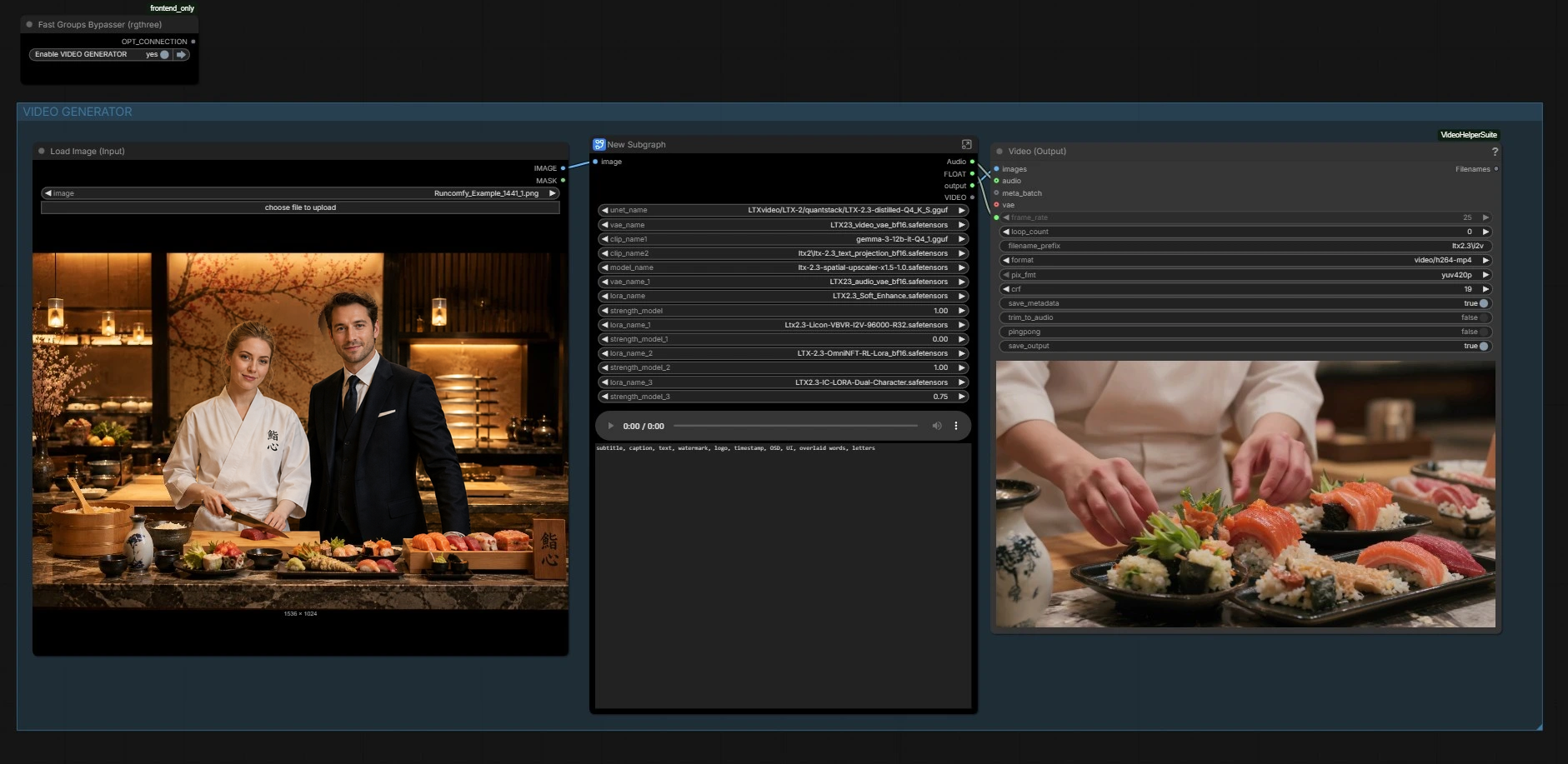
O fluxo de trabalho possui duas partes coordenadas: um gerador de imagens que cria o quadro principal, e um gerador de vídeo que impulsiona o movimento e a sincronização labial a partir de áudio enquanto preserva a aparência. Use os grupos abaixo como seu guia.
GERADOR DE IMAGENS#
Esta seção constrói a imagem âncora. Use os predefinições de cena na lista de prompts para rapidamente rascunhar composições, depois refine o texto com descrições de personagens para ambas as pessoas. Uma pilha de difusão de imagem compacta (subgrafo “Z IMG TURBO”) codifica seu prompt e amostra uma referência estática limpa. A imagem é decodificada e salva para inspeção, depois passada adiante para semear identidade e layout para o vídeo.
Entradas principais que você toca aqui: o prompt descritivo para cena, guarda-roupa e dois personagens distintos; evite jargão de lente ou renderização que combate o realismo, a menos que essa aparência seja intencional.
Modelos#
Aqui o gráfico carrega a base LTX‑2.3, seus VAEs de vídeo e áudio, os codificadores de texto, e o upscaler latente. Ele também aplica o LTX 2.3 Dual Character Lip Sync LoRA, além de LoRAs opcionais de estilo ou aprimoramento se você os habilitar. É aqui que as capacidades do modelo base são combinadas com o comportamento de sincronização labial de dois falantes do LoRA para direcionar o movimento labial sem sacrificar a identidade. Nenhuma ação é necessária, a menos que você queira trocar pesos ou ajustar a influência do LoRA.
ÁUDIO PERSONALIZADO#
Forneça sua faixa de conversa aqui. O arquivo de áudio é carregado e codificado em um latente de áudio que carrega tempo e dicas fonéticas através do pipeline. Se você não fornecer áudio, o fluxo de trabalho pode gerar movimento usando um latente de áudio vazio, mas o LTX 2.3 Dual Character Lip Sync LoRA é projetado para brilhar com diálogo real. Use uma mistura limpa de dois falantes com clara alternância de falas para melhor separação dos movimentos labiais.
PARÂMETROS DE VÍDEO#
Defina a duração alvo e a taxa de quadros. Esses valores são armazenados e reutilizados em toda a amostragem, agendamento, guias de corte e renderização final para que lábios, piscadas e tempo de cena permaneçam alinhados. Mantenha seu comprimento de vídeo consistente com o áudio fornecido para evitar introdução ou finalização extras.
GERAÇÃO LATENTE#
Sua imagem estática selecionada é pré-processada e suas dimensões são detectadas. O fluxo de trabalho cria um latente de vídeo com o comprimento certo, depois insere a imagem estática no lugar para que o primeiro quadro corresponda ao seu design. Uma máscara de ruído de quadro completo é aplicada para controlar quanto o fundo pode evoluir em relação aos rostos. O latente de áudio preparado é então emparelhado com o latente de vídeo para que ambas as modalidades estejam prontas para condicionamento.
Nós notáveis: LTXVPreprocess escala sua imagem estática para LTX, EmptyLTXVLatentVideo constrói a linha do tempo, e LTXVImgToVideoInplaceKJ (#5881) bloqueia a identidade ao semear o primeiro quadro da imagem estática.
Condicionamento#
Os prompts de texto são codificados e anexados como condições positivas e negativas. Use a caixa de prompt global para descrever a encenação e a intenção em linguagem natural; você pode incluir uma lista de cenas curta se for útil. Um codificador de texto negativo dedicado suprime legendas, marcas d'água e UI na tela para que os rostos permaneçam limpos. Guias de corte ajudam a analisar o latente para colocar atenção em ambos os rostos, melhorando o rastreamento de expressões por falante com o LTX 2.3 Dual Character Lip Sync LoRA ativo.
Componentes representativos: PromptRelayEncode (#5903) mescla sua descrição de cena com o contexto latente, e LTXVConditioning anexa orientação consciente da taxa de quadros para ambas as modalidades.
1ª Amostragem#
A primeira passagem de redução de ruído gera um vídeo base temporalmente coerente com movimento labial bloqueado. Um agendador e amostrador leves são selecionados automaticamente, com parâmetros roteados dos valores de tempo armazenados. A variante do modelo saindo de LTX2_NAG adiciona orientação consciente de ruído para condições de vídeo e áudio para que o tempo da fala permaneça ancorado à medida que o conteúdo se forma.
Caminho principal do amostrador: SamplerCustom (#5891) com KSamplerSelect e um agendador básico; ajuste apenas se tiver preferências específicas de amostrador.
Estágio #2 Aumento e refinamento#
O segundo estágio melhora a nitidez e as microexpressões. O upscaler latente aumenta o detalhe espacial, os latentes de áudio e vídeo são reunidos, e um amostrador de refinamento faz correções sutis enquanto preserva o movimento estabelecido. Depois, os latentes são separados e decodificados de volta para uma sequência de imagens e uma forma de onda de áudio.
Blocos importantes: LTXVLatentUpsampler (#5927) para clareza, SamplerCustomAdvanced (#5929) para a passagem de refinamento, seguido por VAEDecode e LTXVAudioVAEDecode para retornar ao espaço de pixels e áudio.
Saída#
Finalmente, quadros e áudio são empacotados em um MP4 para reprodução e revisão. A taxa de quadros usada para o condicionamento é reutilizada aqui para que a cadência visual e o tempo dos fonemas correspondam ao que o modelo viu durante a geração. Você também pode pré-visualizar o áudio no meio do gráfico se precisar de uma verificação rápida.
Caminho de saída: CreateVideo (#5931) constrói o clipe; um caminho auxiliar VHS_VideoCombine (#5905) é fornecido para exportações alternativas com controles de metadados.
Nós principais no fluxo de trabalho Comfyui LTX 2.3 Dual Character Lip Sync LoRA#
LTXICLoRALoaderModelOnly(#5958) Carrega o LTX 2.3 Dual Character Lip Sync LoRA na base LTX‑2.3. Aumentestrength_modelquando precisar de articulação labial mais firme e separação de falantes; diminua quando quiser que o movimento e estilo do modelo base dominem, especialmente se você empilhar LoRAs adicionais de estilo.PromptRelayEncode(#5903) Local central para escrever a descrição da cena e, opcionalmente, um breve plano de tomada. Ele funde o prompt global com o contexto do modelo e o latente atual para que a orientação permaneça consistente ao longo da linha do tempo. Mantenha a linguagem clara e descreva ambos os personagens distintamente para ajudar na identidade e separação de papéis.LTXVImgToVideoInplaceKJ(#5881) Semear o primeiro quadro do latente de vídeo diretamente da sua imagem gerada ou carregada. Isso bloqueia identidade, guarda-roupa e iluminação, reduzindo a deriva ao longo do tempo. Use um plano médio ou médio-amplo com ambos os rostos desobstruídos para melhores resultados.LTXVAudioVAEEncode(#5851) Converte a faixa de diálogo fornecida em um latente de áudio que o modelo pode usar para o tempo dos fonemas. Forneça uma mistura limpa sem compressão pesada; certifique-se de que o tempo de início corresponda ao primeiro discurso na tela para evitar movimento labial deslocado.SamplerCustom(#5891) eSamplerCustomAdvanced(#5929) Duas etapas complementares de redução de ruído. Mantenha as famílias de amostradores consistentes entre as etapas para manter a continuidade do movimento e evite mudanças drásticas na programação de ruído uma vez que você tenha uma aparência que goste.LTXVLatentUpsampler(#5927) Aplica o upscaler latente LTX antes do refinamento para adicionar nitidez sem desestabilizar o movimento estabelecido. Escolha uma variante de upscaler apropriada para sua resolução alvo e realismo de textura.
Extras opcionais#
- Use um WAV de dois falantes a 24 kHz com ruído de fundo mínimo; adicione pausas naturais curtas entre as falas para ajudar o LTX 2.3 Dual Character Lip Sync LoRA a separar as alternâncias.
- Gere ou forneça uma imagem estática onde ambos os sujeitos estejam visíveis, voltados geralmente para a câmera, com iluminação consistente nos rostos.
- Mantenha o prompt de texto negativo que exclui “legenda, legenda, logo, timestamp” para evitar elementos de UI queimados durante a amostragem.
- Comece com um clipe curto para validar o tempo, depois estenda a duração ou aumente a resolução assim que gostar do comportamento.
- Se adicionar LoRAs de estilo, equilibre-os contra o LTX 2.3 Dual Character Lip Sync LoRA para que a articulação permaneça precisa enquanto a cena retém sua estética escolhida.
Agradecimentos#
Este fluxo de trabalho implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos aos criadores de "Fonte do Fluxo de Trabalho LTX 2.3 Dual Character Lip Sync LoRA" pelo fluxo de trabalho. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Fonte do Fluxo de Trabalho LTX 2.3 Dual Character Lip Sync LoRA/Fonte do Fluxo de Trabalho LTX 2.3 Dual Character Lip Sync LoRA
- Documentos / Notas de Lançamento: Vídeo do YouTube
Nota: O uso dos modelos, conjuntos de dados e códigos referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.
