
LatentSync é uma estrutura de sincronização labial de ponta a ponta que aproveita o poder dos modelos de difusão latente condicionados por áudio para a geração realista de sincronização labial. O que diferencia o LatentSync é sua capacidade de modelar diretamente as correlações intrincadas entre componentes áudio e visuais sem depender de qualquer representação de movimento intermediário, revolucionando a abordagem para a síntese de sincronização labial.
No núcleo do pipeline do LatentSync está a integração do Stable Diffusion, um poderoso modelo generativo renomado por sua capacidade excepcional de capturar e gerar imagens de alta qualidade. Ao aproveitar as capacidades do Stable Diffusion, o LatentSync pode efetivamente aprender e reproduzir as dinâmicas complexas entre o áudio do discurso e os movimentos labiais correspondentes, resultando em animações de sincronização labial altamente precisas e convincentes.
Um dos principais desafios nos métodos de sincronização labial baseados em difusão é manter a consistência temporal entre os quadros gerados, o que é crucial para resultados realistas. LatentSync enfrenta esse problema de frente com seu inovador módulo de Alinhamento de REPresentação Temporal (TREPA), especificamente projetado para melhorar a coerência temporal das animações de sincronização labial. TREPA emprega técnicas avançadas para extrair representações temporais dos quadros gerados usando modelos de vídeo auto-supervisionados em grande escala. Ao alinhar essas representações com os quadros verdadeiros, a estrutura do LatentSync assegura um alto grau de coerência temporal, resultando em animações de sincronização labial notavelmente suaves e convincentes que correspondem de perto ao áudio de entrada.
1.1 Como Usar o Workflow do LatentSync?#
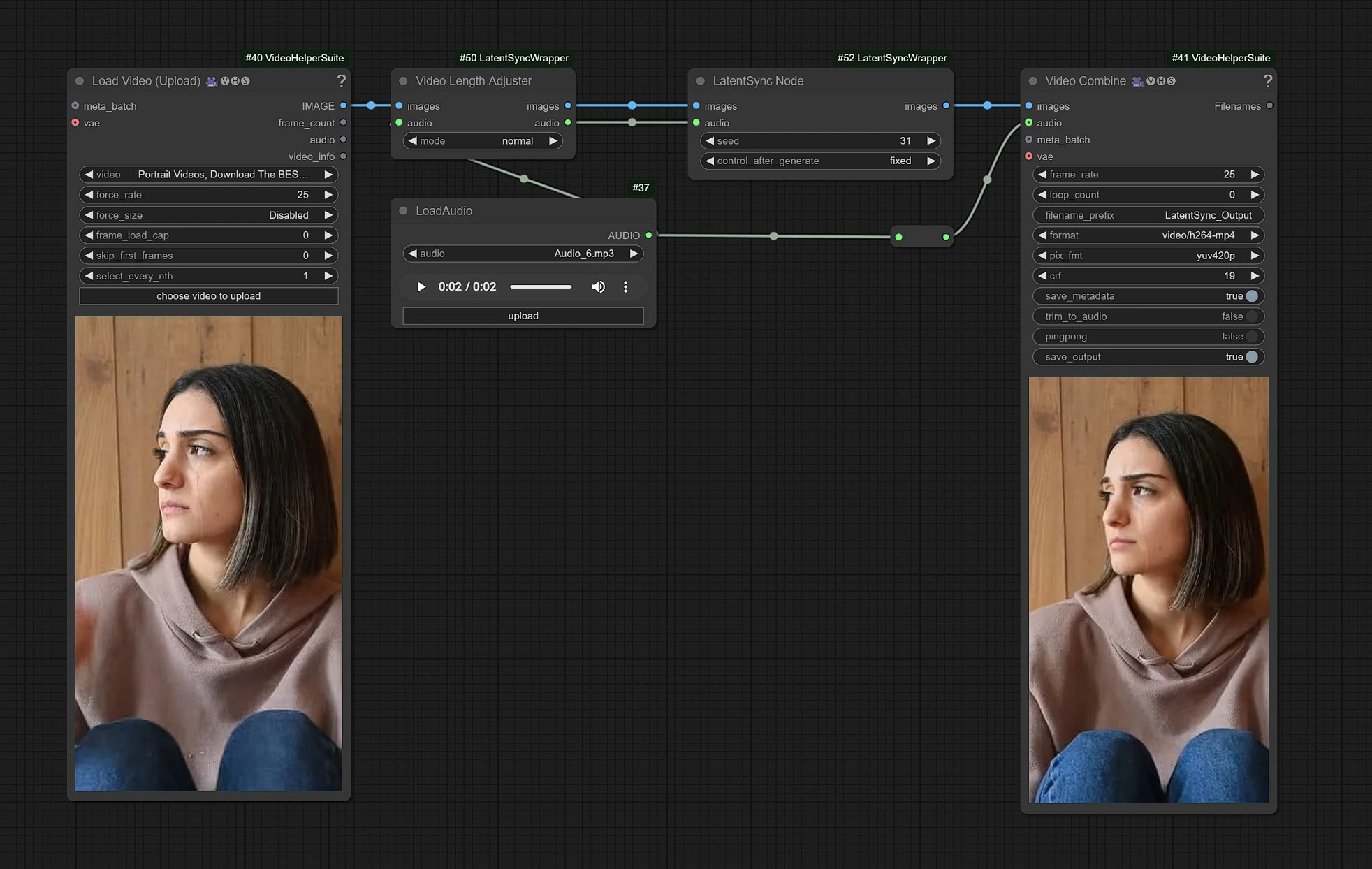
Este é o fluxo de trabalho do LatentSync, os nós do lado esquerdo são entradas para carregar vídeo, o meio é o processamento dos nós do LatentSync, e à direita está o nó de saídas.
- Carregue seu Vídeo nos nós de entrada.
- Carregue sua entrada de Áudio de diálogos.
- Clique em Renderizar !!!
1.2 Entrada de Vídeo#
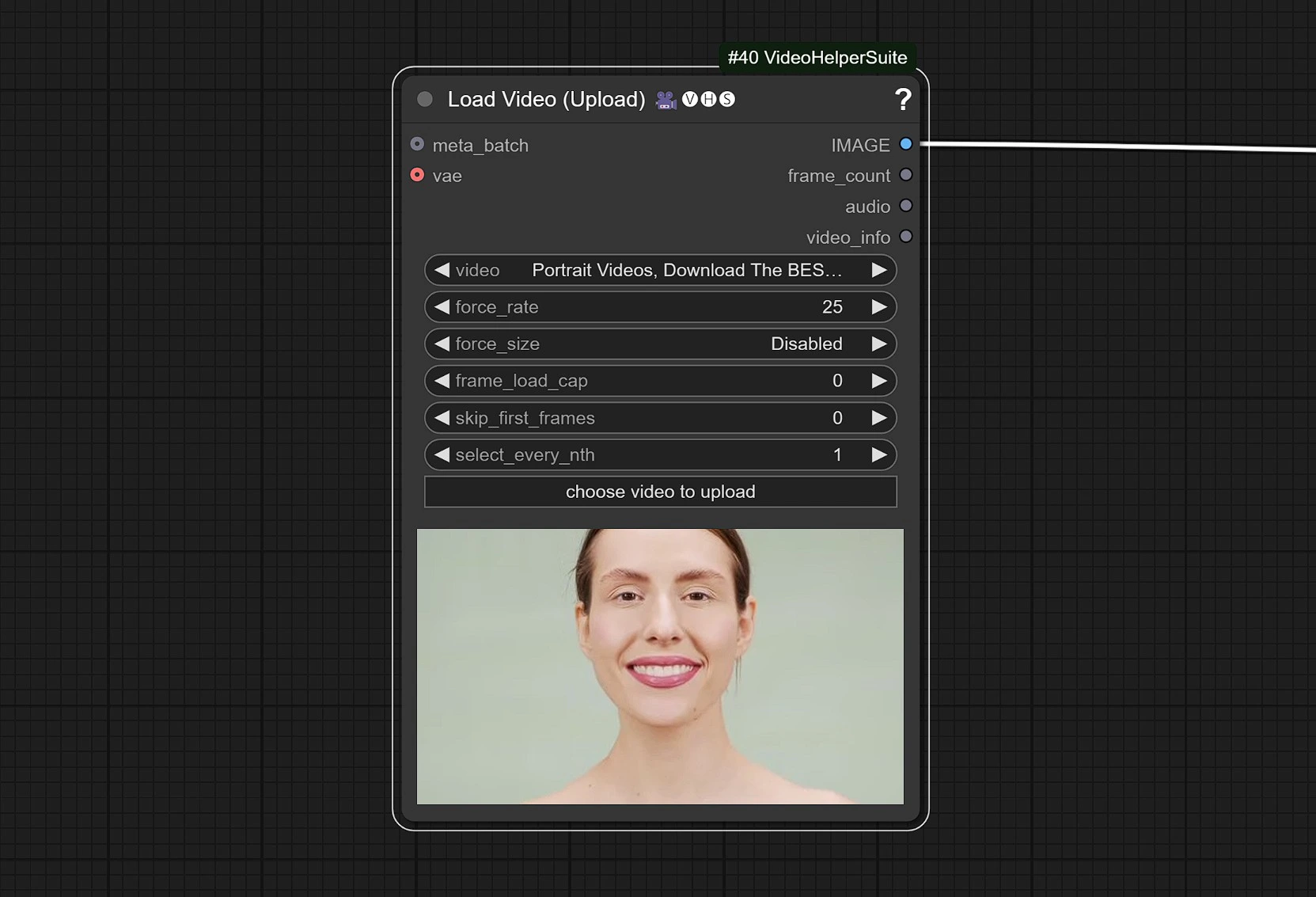
- Clique e Carregue seu Vídeo de Referência que tenha rosto nele.
O vídeo é ajustado para 25 FPS para sincronizar adequadamente com o modelo de Áudio
1.3 Entrada de Áudio#
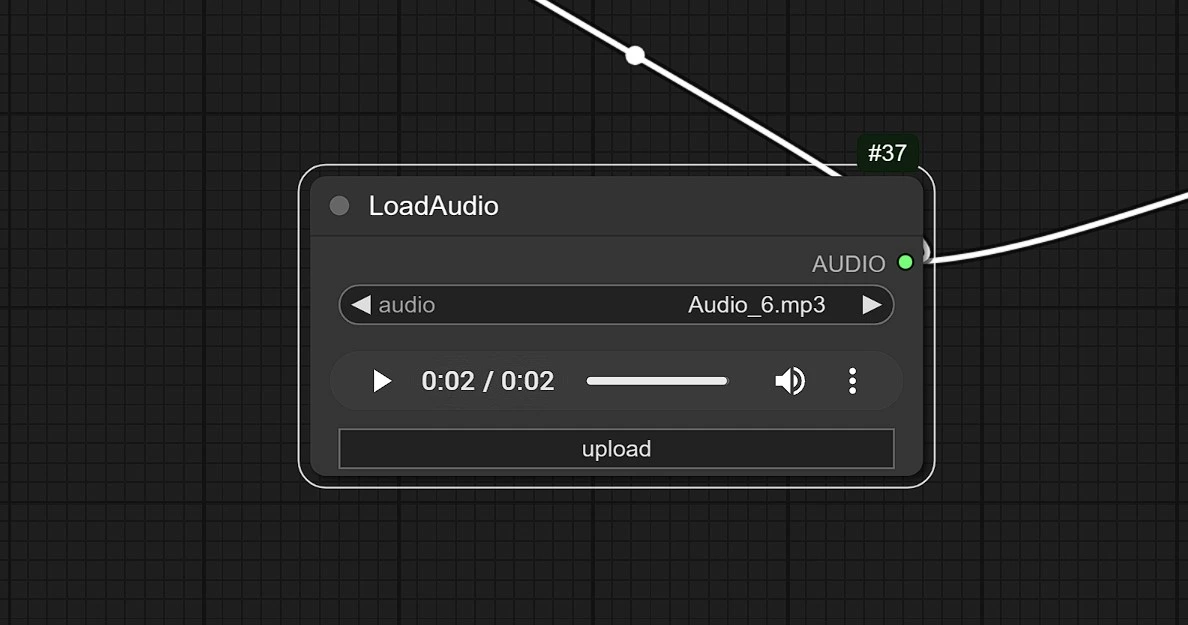
- Clique e Carregue seu áudio aqui.
LatentSync estabelece um novo padrão para sincronização labial com sua abordagem inovadora para geração áudio-visual. Ao combinar precisão, consistência temporal e o poder do Stable Diffusion, o LatentSync transforma a forma como criamos conteúdo sincronizado. Redefina o que é possível em sincronização labial com o LatentSync.

