
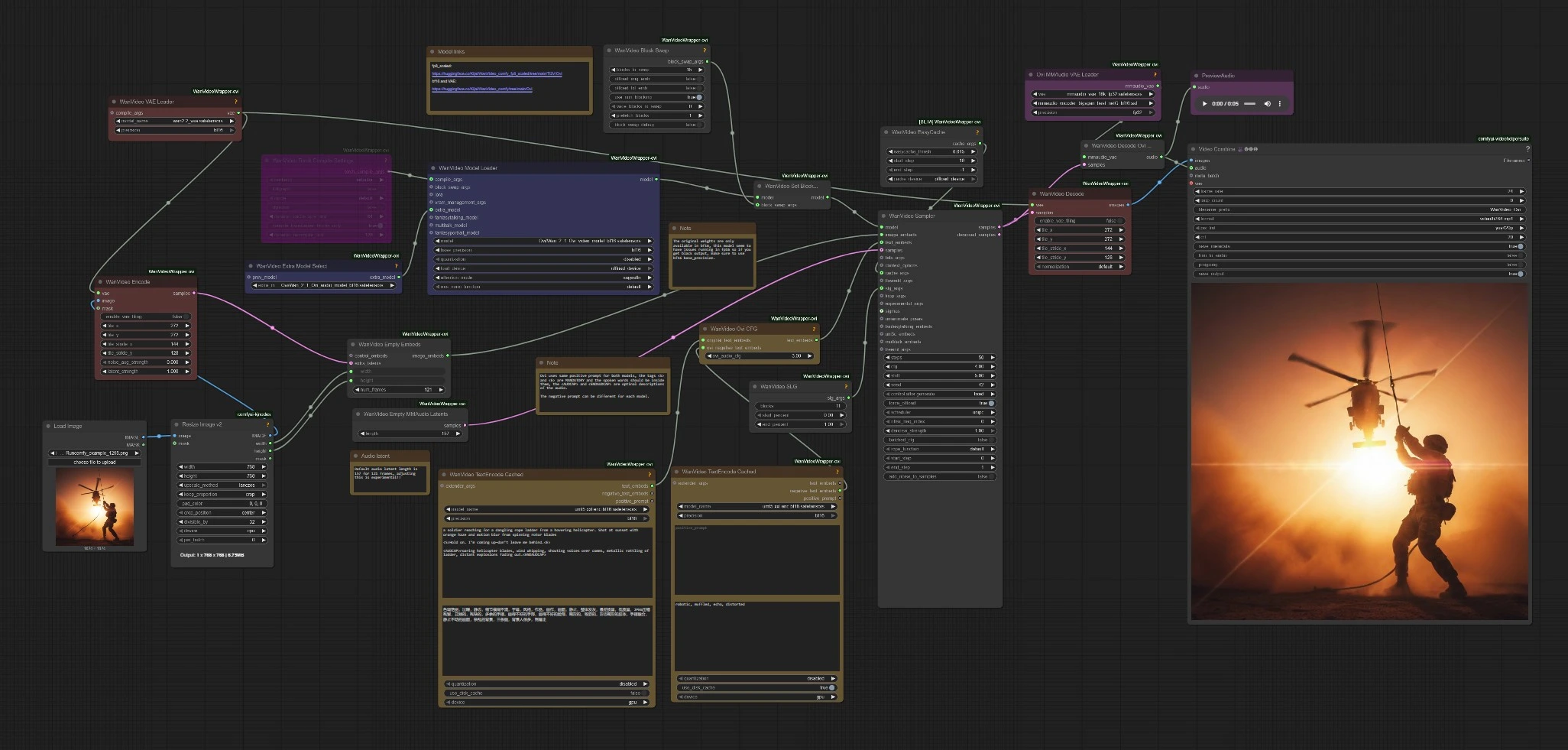
Character AI Ovi: imagem para vídeo com fala sincronizada no ComfyUI#
Character AI Ovi é um workflow de geração audiovisual que transforma uma única imagem em um personagem falante e em movimento com som coordenado. Baseado na família de modelos Wan e integrado através do WanVideoWrapper, ele gera vídeo e áudio em uma única passagem, entregando animação expressiva, sincronia labial inteligível e ambiente sensível ao contexto. Se você cria histórias curtas, anfitriões virtuais ou clipes sociais cinematográficos, o Character AI Ovi permite que você vá de arte estática a uma performance completa em minutos.
Este workflow do ComfyUI aceita uma imagem mais um prompt de texto contendo marcação leve para fala e design de som. Ele compõe quadros e forma de onda juntos para que a boca, cadência e áudio da cena se alinhem naturalmente. O Character AI Ovi é projetado para criadores que desejam resultados polidos sem juntar ferramentas separadas de TTS e vídeo.
Modelos chave no workflow do ComfyUI Character AI Ovi#
- Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation. O modelo central que produz conjuntamente vídeo e áudio a partir de prompts de texto ou texto+imagem. character-ai/Ovi
- Wan 2.2 video backbone and VAE. O workflow usa o VAE de vídeo de alta compressão do Wan para geração eficiente em 720p, 24 fps, preservando detalhe e coerência temporal. Wan-AI/Wan2.2-TI2V-5B-Diffusers • Wan-Video/Wan2.2
- Google UMT5-XXL text encoder. Codifica o prompt, incluindo tags de fala, em embeddings multilíngues ricos que dirigem ambos os ramos. google/umt5-xxl
- MMAudio VAE com BigVGAN vocoder. Decodifica os latentes de áudio do modelo para fala e efeitos de alta qualidade com timbre natural. hkchengrex/MMAudio • nvidia/bigvgan_v2_44khz_128band_512x
- Pesos prontos para ComfyUI Ovi por Kijai. Checkpoints curados para o ramo de vídeo, ramo de áudio e VAE em variantes escaladas bf16 e fp8. Kijai/WanVideo_comfy/Ovi • Kijai/WanVideo_comfy_fp8_scaled/TI2V/Ovi
- Nós WanVideoWrapper para ComfyUI. Wrapper que expõe recursos do Wan e Ovi como nós componíveis. kijai/ComfyUI-WanVideoWrapper
Como usar o workflow do ComfyUI Character AI Ovi#
Este workflow segue um caminho simples: codifique seu prompt e imagem, carregue os checkpoints do Ovi, amostre latentes conjuntos de áudio+vídeo, depois decodifique e mux para MP4. As subseções abaixo mapeiam para os clusters de nós visíveis para que você saiba onde interagir e quais mudanças afetam os resultados.
Criação de prompt para fala e som#
Escreva um prompt positivo para a cena e a linha falada. Use as tags Ovi exatamente como mostrado: envolva palavras a serem faladas com <S> e <E>, e opcionalmente descreva áudio não-falado com <AUDCAP> e <ENDAUDCAP>. O mesmo prompt positivo condiciona ambos os ramos de vídeo e áudio para que o movimento labial e o tempo se alinhem. Você pode usar diferentes prompts negativos para vídeo e áudio para suprimir artefatos de forma independente. O Character AI Ovi responde bem a direções de palco concisas mais uma linha de diálogo clara e única.
Ingestão e condicionamento de imagem#
Carregue um único retrato ou imagem de personagem, então o workflow redimensiona e codifica para latentes. Isso estabelece identidade, pose e enquadramento inicial para o sampler. Largura e altura da etapa de redimensionamento definem o aspecto do vídeo; escolha quadrado para avatares ou vertical para shorts. Os latentes codificados e embeddings derivados da imagem guiam o sampler para que o movimento pareça ancorado ao rosto original.
Carregamento de modelo e auxiliares de desempenho#
O Character AI Ovi carrega três essenciais: o modelo de vídeo Ovi, o VAE Wan 2.2 para quadros, e o VAE MMAudio mais BigVGAN para áudio. Compilação Torch e um cache leve são incluídos para acelerar inícios quentes. Um auxiliar de troca de blocos está conectado para reduzir o uso de VRAM transferindo blocos de transformador quando necessário. Se você estiver com restrição de VRAM, aumente a troca de blocos no nó de troca de blocos e mantenha o cache ativado para execuções repetidas.
Amostragem conjunta com orientação#
O sampler executa as bases gêmeas do Ovi juntas para que a trilha sonora e os quadros co-evoluam. Um auxiliar de orientação de camada de salto melhora a estabilidade e o detalhe sem sacrificar o movimento. O workflow também roteia seus embeddings de texto originais através de um mixer CFG específico do Ovi para que você possa inclinar o equilíbrio entre a adesão estrita ao prompt e a animação mais livre. O Character AI Ovi tende a produzir o melhor movimento labial quando a linha falada é curta, literal e apenas cercada pelas tags <S> e <E>.
Decodificação, visualização e exportação#
Após a amostragem, os latentes de vídeo decodificam através do VAE Wan enquanto os latentes de áudio decodificam através do MMAudio com BigVGAN. Um combinador de vídeo muxa quadros e áudio em um MP4 a 24 fps, pronto para compartilhamento. Você também pode visualizar o áudio diretamente para verificar a inteligibilidade da fala antes de salvar. O caminho padrão do Character AI Ovi visa 5 segundos; estenda com cautela para manter os lábios e a cadência sincronizados.
Nós chave no workflow do ComfyUI Character AI Ovi#
WanVideoTextEncodeCached(#85)
Codifica o prompt positivo principal e o prompt negativo de vídeo em embeddings usados por ambos os ramos. Mantenha o diálogo dentro de <S>…<E> e coloque o design de som dentro de <AUDCAP>…<ENDAUDCAP>. Para melhor alinhamento, evite múltiplas sentenças em uma tag de fala e mantenha a linha concisa.
WanVideoTextEncodeCached(#96)
Fornece um embedding de texto negativo dedicado para áudio. Use-o para suprimir artefatos como tom robótico ou reverberação pesada sem afetar os visuais. Comece com descrições curtas e expanda apenas se ainda ouvir o problema.
WanVideoOviCFG(#94)
Mistura os embeddings de texto originais com os negativos específicos de áudio através de uma orientação livre de classificadores consciente do Ovi. Aumente quando o conteúdo da fala se desviar da linha escrita ou os movimentos labiais parecerem errados. Abaixe ligeiramente se o movimento se tornar rígido ou excessivamente restrito.
WanVideoSampler(#80)
O coração do Character AI Ovi. Consome embeds de imagem, embeds de texto conjuntos e orientação opcional para amostrar um único latente que contém tanto vídeo quanto áudio. Mais etapas aumentam a fidelidade, mas também o tempo de execução. Se você ver pressão de memória ou paradas, combine troca de blocos mais alta com cache ativado e considere desativar a compilação torch para solução rápida de problemas.
WanVideoEmptyMMAudioLatents(#125)
Inicializa a linha do tempo de latentes de áudio. O comprimento padrão é ajustado para um clipe de 121 quadros, 24 fps. Ajustar isso para mudar a duração é experimental; mude-o apenas se entender como ele deve acompanhar a contagem de quadros.
VHS_VideoCombine(#88)
Muxa quadros decodificados e áudio para MP4. Defina a taxa de quadros para corresponder ao seu alvo de amostragem e ative a opção de corte-para-áudio se quiser que o corte final siga a forma de onda gerada. Use o controle CRF para equilibrar o tamanho do arquivo e a qualidade.
Extras opcionais#
- Use bf16 para vídeo Ovi e Wan 2.2 VAE. Se encontrar quadros pretos, mude a precisão base para
bf16para os carregadores de modelo e codificador de texto. - Mantenha os discursos curtos. O Character AI Ovi sincroniza os lábios de forma mais confiável com diálogo curto de uma única frase dentro de
<S>e<E>. - Separe negativos. Coloque artefatos visuais no prompt negativo de vídeo e artefatos tonais no prompt negativo de áudio para evitar trocas não intencionais.
- Visualize primeiro. Use a visualização de áudio para confirmar clareza e ritmo antes de exportar o MP4 final.
- Obtenha os pesos exatos usados. O workflow espera checkpoints de vídeo e áudio Ovi mais o VAE Wan 2.2 dos espelhos de modelo do Kijai. WanVideo_comfy/Ovi • WanVideo_comfy_fp8_scaled/TI2V/Ovi
Com essas peças no lugar, o Character AI Ovi se torna um pipeline compacto e amigável ao criador para avatares falantes expressivos e cenas narrativas que soam tão bem quanto parecem.
Agradecimentos#
Este workflow implementa e constrói com base nos seguintes trabalhos e recursos. Agradecemos kijai e Character AI por Ovi por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Fonte Character AI Ovi
- Workflow: wanvideo_2_2_5B_ovi_testing @kijai
- Github: character-ai/Ovi
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.


