
1. What is Omost?
Omost, short for "Your image is almost there!", is an innovative project that converts Large Language Models' (LLM) coding capabilities to image generation, or more precisely, image composing capabilities. The name "Omost" has a dual meaning: it implies that every time you use Omost, your image is almost complete, and it also signifies "omni" (multi-modal) and "most" (getting the most out of it).
Omost provides pretrained LLM models that generate code to compose image visual content using Omost's virtual Canvas agent. This Canvas can then be rendered by specific implementations of image generators to create the final images. Omost is designed to simplify and enhance the image generation process, making it accessible and efficient for AI artists.
2. How Omost Works
2.1. Canvas and Descriptions
Omost uses a virtual Canvas where elements of the image are described and positioned. The Canvas is divided into a grid of 9x9=81 positions, allowing precise placement of elements. These positions are further refined into bounding boxes, providing 729 different possible locations for each element. This structured approach ensures that elements are placed accurately and consistently.
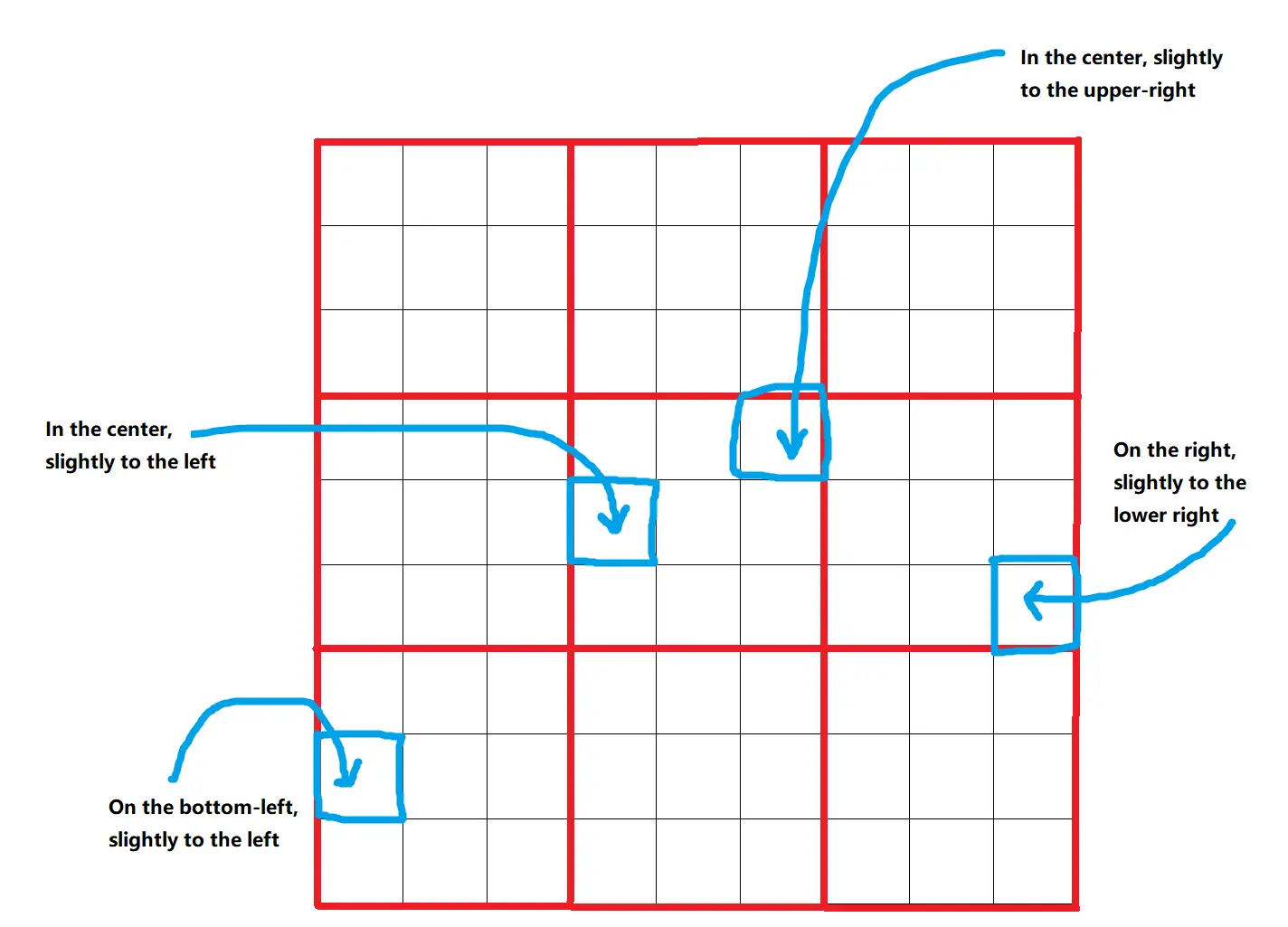
2.2. Depth and Color
Elements on the Canvas are assigned a distance_to_viewer parameter, which helps sort them into background-to-foreground layers. This parameter acts as a relative depth indicator, ensuring that closer elements appear in front of those that are further away. Additionally, the HTML_web_color_name parameter provides a coarse color representation for initial rendering, which can be refined using diffusion models. This initial color helps in visualizing the composition before fine-tuning.

2.3. Prompt Engineering
Omost uses sub-prompts, which are brief, self-contained descriptions of elements, to generate detailed and coherent image compositions. Each sub-prompt is less than 75 tokens and describes an element independently. These sub-prompts are merged into complete prompts for the LLM to process, ensuring that the generated images are accurate and semantically rich. This method ensures that the text encoding is efficient and avoids semantic truncation errors.
2.4. Regional Prompter
Omost implements advanced attention manipulation techniques to handle regional prompts, ensuring that each part of the image is generated accurately based on the given descriptions. Techniques such as attention score manipulation ensure that the activations within masked areas are encouraged, while those outside are discouraged. This precise control over attention results in high-quality, region-specific image generation.
3. Detailed Explanation of ComfyUI Omost Nodes
3.1. Omost LLM Loader Node
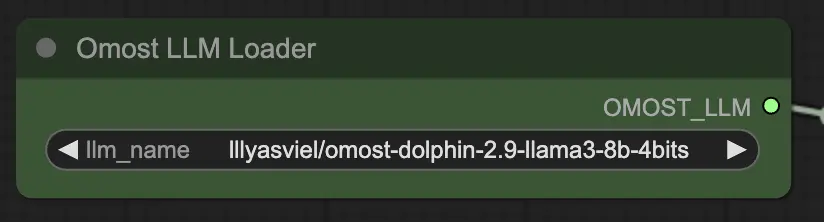
Input parameters of Omost LLM Loader Node
llm_name: The name of the pretrained LLM model to load. Available options include:lllyasviel/omost-phi-3-mini-128k-8bitslllyasviel/omost-llama-3-8b-4bitslllyasviel/omost-dolphin-2.9-llama3-8b-4bits
This parameter specifies which model to load, each offering different capabilities and optimizations.
Output parameters of Omost LLM Loader Node
OMOST_LLM: The loaded LLM model.
This output provides the loaded LLM, ready to generate image descriptions and compositions.
3.2. Omost LLM Chat Node
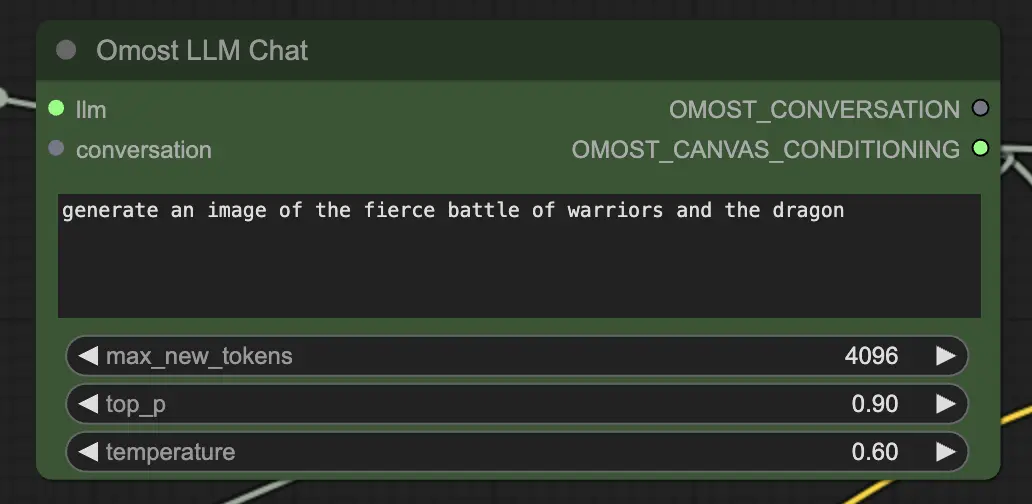
Input parameters of Omost LLM Chat Node
llm: The LLM model loaded by theOmostLLMLoader.text: The text prompt to generate an image. This is the main input where you describe the scene or elements you want to generate.max_new_tokens: Maximum number of new tokens to generate. This controls the length of the generated text, with a higher number allowing more detailed descriptions.top_p: Controls the diversity of the generated output. A value closer to 1.0 includes more diverse possibilities, while a lower value focuses on the most likely outcomes.temperature: Controls the randomness of the generated output. Higher values result in more random outputs, while lower values make the output more deterministic.conversation(Optional): Previous conversation context. This allows the model to continue from previous interactions, maintaining context and coherence.
Output parameters of Omost LLM Chat Node
OMOST_CONVERSATION: The conversation history, including the new response. This helps in tracking the dialogue and maintaining context across multiple interactions.OMOST_CANVAS_CONDITIONING: The generated Canvas conditioning parameters for rendering. These parameters define how the elements are placed and described on the Canvas.
3.3. Omost Render Canvas Conditioning Node
Input parameters of Omost Render Canvas Conditioning Node
canvas_conds: The Canvas conditioning parameters. These parameters include detailed descriptions and positions of elements on the Canvas.
Output parameters of Omost Render Canvas Conditioning Node
IMAGE: The rendered image based on the Canvas conditioning. This output is the visual representation of the described scene, generated from the conditioning parameters.
3.4. Omost Layout Cond Node
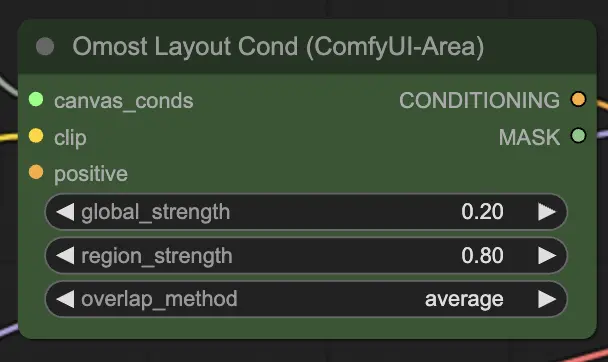
Input parameters of Omost Layout Cond Node
canvas_conds: The Canvas conditioning parameters.clip: The CLIP model for text encoding. This model encodes the text descriptions into vectors that can be used by the image generator.global_strength: The strength of the global conditioning. This controls how strongly the overall description affects the image.region_strength: The strength of the regional conditioning. This controls how strongly the specific regional descriptions affect their respective areas.overlap_method: The method to handle overlapping areas (e.g.,overlay,average). This defines how to blend overlapping regions in the image.positive(Optional): Additional positive conditioning. This can include extra prompts or conditions to enhance specific aspects of the image.
Output parameters of Omost Layout Cond Node
CONDITIONING: The conditioning parameters for image generation. These parameters guide the image generation process, ensuring that the output matches the described scene.MASK: The mask used for the conditioning. This helps in debugging and applying additional conditions to specific regions.
3.5. Omost Load Canvas Conditioning Node
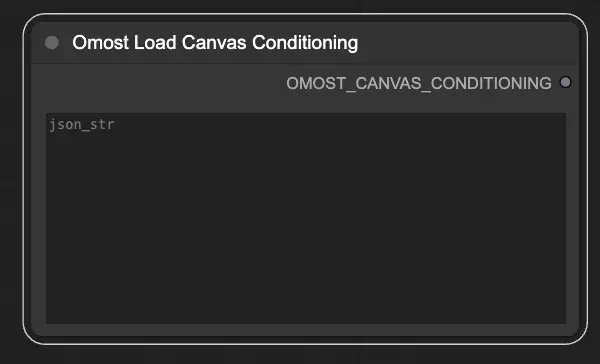
Input parameters of Omost Load Canvas Conditioning Node
json_str: The JSON string representing the Canvas conditioning parameters. This allows loading predefined conditions from a JSON file.
Output parameters of Omost Load Canvas Conditioning Node
OMOST_CANVAS_CONDITIONING: The loaded Canvas conditioning parameters. These parameters initialize the Canvas with specific conditions, ready for image generation.



