
ComfyUI에서 Wan2.2 S2V를 사용한 포즈 제어 LipSync: 오디오 기반, 포즈 제어 이미지-비디오로 표현적 아바타 생성#
ComfyUI에서 Wan2.2 S2V를 사용한 포즈 제어 LipSync는 단일 이미지, 오디오 클립 및 포즈 참조 비디오를 동기화된 말하기 공연으로 변환합니다. 참조 이미지의 캐릭터는 참조 비디오의 몸 동작을 따르며 입 움직임은 오디오에 맞춥니다. 이 ComfyUI 워크플로우는 아바타, 스토리 씬, 트레일러, 설명서 및 포즈, 표현 및 말하기 타이밍에 대한 엄격한 제어가 필요한 뮤직 비디오에 이상적입니다.
Wan 2.2 S2V 14B 모델 패밀리에 기반한 이 워크플로우는 텍스트 프롬프트, 깨끗한 보컬 기능 및 포즈 지도를 융합하여 안정된 정체성을 가진 영화적 모션을 생성합니다. 운영이 간단하도록 설계되었으며, 크리에이터에게 외형, 페이싱 및 프레이밍에 대한 세밀한 제어를 제공합니다.
ComfyUI 포즈 제어 LipSync의 Wan2.2 S2V 워크플로우의 주요 모델#
- Wan2.2-S2V-14B. 정지 이미지와 오디오를 비디오로 변환하는 핵심 스피치-비디오 생성기로, 모션 가이드를 위한 선택적 포즈 조건 설정이 가능합니다. 능력 및 사용 노트는 공식 저장소 및 모델 카드에서 확인하세요: Wan-Video/Wan2.2 및 Wan-AI/Wan2.2-S2V-14B.
- Wan VAE. Wan 오토인코더는 비디오 잠재성을 높은 충실도로 인코딩 및 디코딩하며, Wan 2.x 파이프라인 전반에서 사용됩니다. 참조 구현: Diffusers의 Wan 파이프라인 문서.
- Google UMT5-XXL 텍스트 인코더. 높은 수준의 장면 의도 및 스타일 제어를 위한 강력한 다국어 텍스트 조건을 제공합니다. 모델 카드: google/umt5-xxl.
- Facebook Wav2Vec2-Large. 립 싱크 및 미세 표현을 구동하는 견고한 음성 기능을 추출합니다. 모델 카드: facebook/wav2vec2-large-960h.
- DWPose와 YOLOX 탐지기. 참조 비디오에서 전체 몸 동작을 안내하기 위해 사람의 포즈 키포인트 및 포즈 지도를 생성합니다. 저장소: IDEA-Research/DWPose 및 Megvii-BaseDetection/YOLOX.
- LightX2V LoRA for Wan. 모션 품질을 유지하면서 저단계 이미지-비디오 스타일 노이즈 제거를 가속화하는 경량 LoRA; Wan 2.2는 그 노이즈 제거기에서 LoRA를 지원합니다. Wan 파이프라인에서의 LoRA 사용에 대한 가이드를 Wan Diffusers 문서에서 확인하세요.
ComfyUI에서 Wan2.2 S2V 워크플로우를 사용하는 방법#
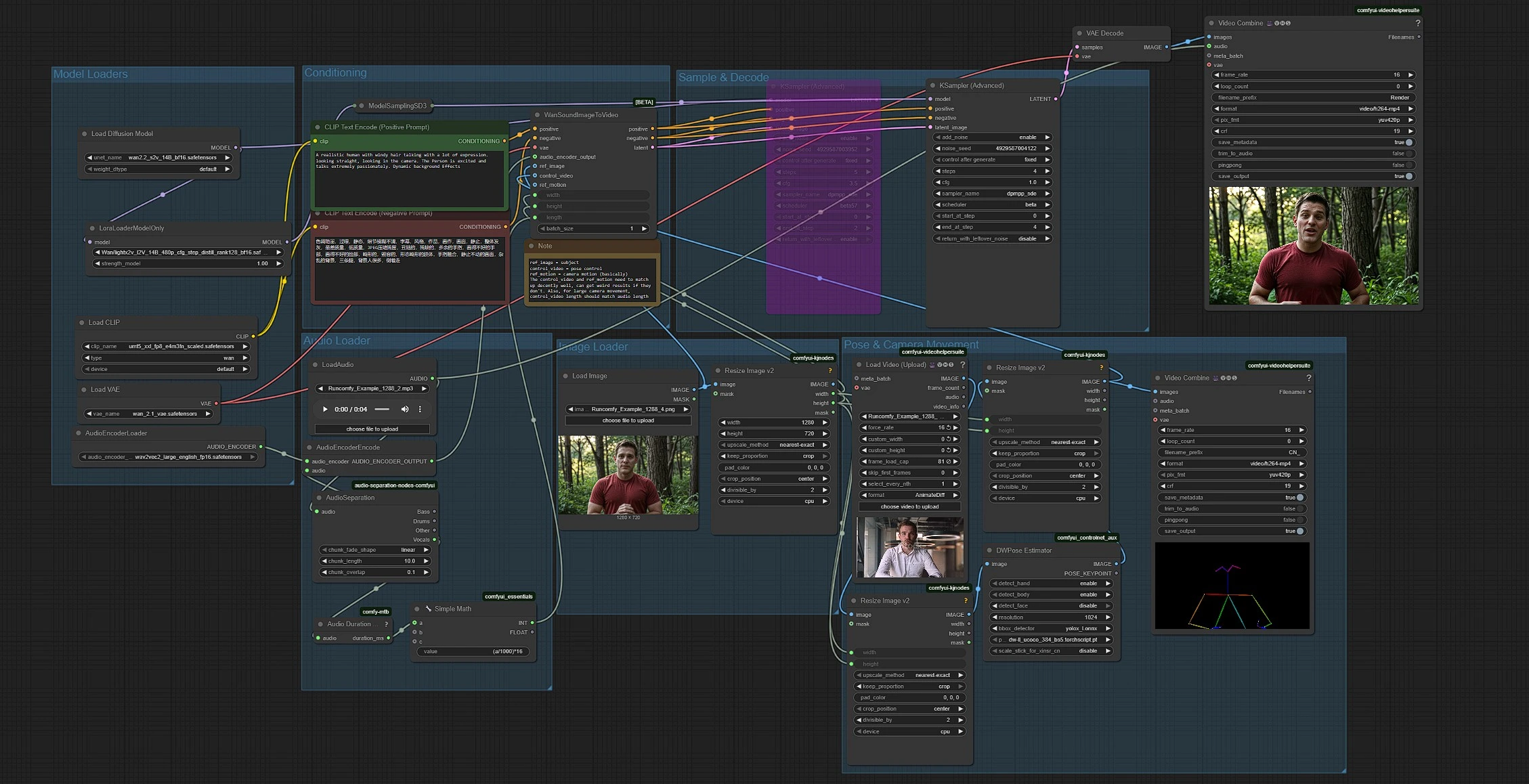
워크플로우는 모델 로딩, 오디오 준비, 이미지 및 포즈 입력, 조건 설정 및 생성의 다섯 부분으로 구성됩니다. 그룹은 왼쪽에서 오른쪽으로 흐르며, 오디오 길이는 자동으로 클립 지속 시간을 16 fps로 설정합니다.
모델 로더#
이 그룹은 Wan 2.2 S2V 모델, 그 VAE, UMT5-XXL 텍스트 인코더 및 LightX2V LoRA를 로드합니다. 기본 변환기는 UNETLoader (#37)에서 초기화되고, 빠른 저단계 샘플링을 위해 LoraLoaderModelOnly (#61)로 조정됩니다. Wan VAE는 VAELoader (#39)에서 제공됩니다. 텍스트 인코더는 CLIPLoader (#38)에 의해 제공되며, 이는 Wan이 참조하는 UMT5-XXL 가중치를 로드합니다. 모델 파일을 교체하지 않는 한 이 그룹을 건드릴 필요는 거의 없습니다.
오디오 로더#
LoadAudio (#58)로 오디오 파일을 드롭합니다. AudioSeparation (#85)은 보컬 스템을 분리하여 입이 배경 악기 대신 명확한 음성이나 노래를 따르도록 합니다. Audio Duration (mtb) (#70)은 클립을 측정하고 SimpleMath+ (#71)는 지속 시간을 16 fps에서 프레임 수로 변환하여 비디오 길이가 오디오와 일치하도록 합니다. AudioEncoderEncode (#56)는 Wav2Vec2-Large 인코더를 공급하여 Wan이 음소를 입 모양에 매핑하여 정확한 립 싱크를 제공합니다.
이미지 로더#
LoadImage (#52)는 정체성, 의상 및 카메라 설정을 전달하는 주제 스틸을 제공합니다. ImageResizeKJv2 (#69)는 이미지에서 차원을 읽어 후속 단계에서 일관되게 목표 너비와 높이를 유도합니다. 입이 방해받지 않는 선명한 정면 이미지를 사용하여 가장 정확한 입 움직임을 제공합니다.
포즈 및 카메라 움직임#
VHS_LoadVideo (#80)는 포즈 참조 비디오를 가져옵니다. ImageResizeKJv2 (#83)는 프레임을 목표 크기에 맞추고, DWPreprocessor (#78)는 YOLOX 탐지와 DWPose 키포인트로 포즈 지도로 변환합니다. 최종적으로 ImageResizeKJv2 (#81)는 포즈 프레임을 생성 해상도에 맞춰 정렬한 후 제어 비디오로 전달합니다. 포즈 출력을 미리 보려면 VHS_VideoCombine (#95)로 라우팅하여 참조 프레이밍 및 타이밍이 주제에 맞는지 확인할 수 있습니다.
조건 설정#
스타일 및 장면 의도를 CLIP Text Encode (Positive Prompt) (#6)에 작성하고, CLIP Text Encode (Negative Prompt) (#7)를 사용하여 원치 않는 아티팩트를 방지합니다. 프롬프트는 높은 수준의 미학 및 배경 모션을 유도하며, 오디오는 입 움직임을 구동하고 포즈 참조는 신체 역학을 통제합니다. 프롬프트는 간결하고 목표 카메라 각도 및 분위기에 맞춰야 합니다.
샘플 및 디코드#
WanSoundImageToVideo (#55)는 텍스트, 오디오 기능, 참조 이미지 및 포즈 제어 비디오를 융합한 후 잠재 시퀀스를 준비합니다. KSamplerAdvanced (#64)는 LightX2V 스타일 가속에 적합한 저단계 노이즈 제거를 수행하고, VAEDecode (#8)는 프레임을 재구성합니다. VHS_VideoCombine (#62)는 프레임을 MP4로 조합하고 원본 오디오를 첨부하여 출력을 검토하거나 편집할 준비를 합니다.
ComfyUI 포즈 제어 LipSync의 Wan2.2 S2V 워크플로우의 주요 노드#
WanSoundImageToVideo (#55)#
프롬프트, 보컬, 주제 이미지 및 포즈 제어 비디오로 Wan2.2-S2V를 조건화하는 워크플로우의 핵심입니다. 중요한 것만 조정하세요: 주제 이미지와 오디오 길이에 맞춰 width, height, length를 설정하고 모션 제어를 위한 사전 처리된 포즈 비디오를 연결합니다. 별도의 카메라 트랙을 주입할 계획이 없는 한 ref_motion은 비워 두세요. 모델의 스피치-비디오 동작은 Wan-AI/Wan2.2-S2V-14B 및 Wan-Video/Wan2.2에 설명되어 있습니다.
DWPreprocessor (#78)#
YOLOX를 사용하여 감지하고 DWPose로 전체 몸 키포인트를 생성하여 포즈 지도를 생성합니다. 강력한 포즈 신호는 Wan이 팔다리와 몸통을 따르도록 도와주며 오디오는 입과 표현을 제어합니다. 참조에 무거운 카메라 움직임이 있는 경우 의도된 공연과 시점 및 타이밍이 맞는 포즈 비디오를 사용하세요. DWPose 및 그 변형은 IDEA-Research/DWPose에 문서화되어 있습니다.
KSamplerAdvanced (#64)#
잠재 시퀀스를 위한 노이즈 제거를 수행합니다. LightX2V LoRA가 로드되면 단계 수를 낮게 유지하여 빠른 미리보기를 제공하면서 모션 일관성을 유지할 수 있습니다; 최대 세부 사항을 추구할 때는 단계를 증가시키세요. 스케줄러 선택은 모션의 부드러움 대 선명도에 영향을 미치며, LoRA 사용과 함께 Wan의 Diffusers 문서에 설명된 대로 조정해야 합니다.
VHS_LoadVideo (#80)#
포즈 참조를 가져오고 스크럽합니다. 노드 내 프레임 선택 도구를 사용하여 오디오 세그먼트와 일치하는 정확한 세그먼트를 선택하세요. 참조 이미지와 프레이밍 및 주제 크기를 일치시킴으로써 모션 전송을 안정화할 수 있습니다. 노드는 VideoHelperSuite의 일부입니다: ComfyUI-VideoHelperSuite.
VHS_VideoCombine (#62)#
생성된 프레임과 오디오를 MP4로 결합하고 워크플로우 메타데이터를 저장합니다. 이 워크플로우에서 오디오 지속 시간에서 계산된 프레임 수와 일치하도록 출력 프레임 속도를 16 fps로 설정합니다. 자산 관리 요구에 따라 메타데이터 저장을 비활성화하거나 활성화하세요. VideoHelperSuite 문서는 ComfyUI-VideoHelperSuite에서 확인할 수 있습니다.
AudioSeparation (#85)#
악기나 FX의 간섭 없이 입 모양을 구동하도록 Wav2Vec2 기능을 사용하여 보컬을 분리합니다. 입력이 이미 깨끗한 음성인 경우에는 분리를 건너뛸 수 있습니다. 최상의 결과를 위해 오디오 레벨을 일관되게 유지하고 반향을 최소화하세요.
선택적 추가 사항#
- 최상의 립 싱크를 위해 깨끗한 음성이나 아카펠라 보컬을 선호하세요. Wav2Vec2는 16 kHz에서 작동하며, 대부분의 파이프라인은 자동으로 리샘플링하지만 16 kHz 파일을 제공하는 것이 도움이 됩니다.
- 잘 조명된 정면 주제 이미지로 치아와 입술이 보이는 이미지를 사용하세요. 가림은 정확성을 감소시킵니다.
- 포즈 참조의 프레이밍 및 움직임을 주제에 맞추세요. 큰 카메라 움직임은 포즈 비디오 길이가 오디오 세그먼트와 일치할 때 가장 잘 작동합니다.
- 빠른 반복을 위해 480p에서 시작하고 최종 품질을 위해 720p로 이동하세요. Wan 2.2는 S2V에서 두 해상도를 모두 지원합니다.
- 프롬프트는 짧고 이미지와 포즈 참조의 카메라 설정과 일관되게 유지하여 충돌을 피하세요.
- LoRA를 실험할 때는 Wan 2.2 노이즈 제거기와 호환되는지 확인하세요. Wan Diffusers 문서에서 LoRA 노트 확인하세요.
이 포즈 제어 LipSync with Wan2.2 S2V 워크플로우는 오디오와 정지 이미지에서 제어 가능한, 박자에 맞는 퍼포먼스를 빠르게 생성하여 일관되고 표현적인 느낌을 제공합니다.
감사의 말#
이 워크플로우는 다음의 작업 및 리소스를 구현하고 기반으로 합니다. 우리는 Pose Control LipSync with Wan2.2 S2VDemo의 @ArtOfficialLabs의 기여와 유지 관리를 진심으로 감사드립니다. 권위 있는 세부 사항은 아래에 연결된 원본 문서 및 저장소를 참조하십시오.
리소스#
- YouTube/Pose Control LipSync with Wan2.2 S2VDemo
- @ArtOfficialLabs의 문서 / 릴리스 노트: Pose Control LipSync with Wan2.2 S2VDemo
참고: 참조된 모델, 데이터 세트 및 코드의 사용은 해당 저자 및 유지 관리자가 제공한 라이센스 및 조건에 따릅니다.
