
Wan2.2 S2V: Da Suono a Video da un'Unica Immagine in ComfyUI#
Wan2.2 S2V è un workflow da suono a video che trasforma un'immagine di riferimento più un clip audio in un video sincronizzato. È costruito attorno alla famiglia di modelli Wan 2.2 e progettato per i creatori che vogliono movimento espressivo, sincronizzazione labiale e dinamiche di scena che seguono suono o discorso. Usa Wan2.2 S2V per avatar parlanti, loop guidati dalla musica e rapide sequenze narrative senza animazione manuale.
Questo grafico ComfyUI accoppia caratteristiche audio con prompt di testo e un'immagine fissa per generare un breve clip, quindi mescola i fotogrammi con l'audio originale. Il risultato è una pipeline compatta e affidabile che mantiene l'aspetto della tua immagine di riferimento mentre lascia che l'audio guidi tempi ed espressione.
Modelli chiave nel workflow Comfyui Wan2.2 S2V#
- Wan 2.2 S2V UNet (14B, bf16). Il generatore principale che fonde caratteristiche audio, condizionamento del testo e un'immagine di riferimento per produrre latenti video.
- Wan VAE (wan_2.1_vae). Codifica/decodifica tra spazio latente e pixel per preservare dettaglio e fedeltà dei colori nei render di Wan2.2 S2V.
- UMT5-XXL text encoder. Fornisce condizionamento dei prompt per stile e contenuto; vedi la scheda del modello base per riferimento: google/umt5-xxl.
- Wav2Vec2 Large audio encoder. Estrae caratteristiche robuste di discorso e ritmo per generazione condizionata dal suono; vedi una scheda archetipica come facebook/wav2vec2-large-960h.
Come usare il workflow Comfyui Wan2.2 S2V#
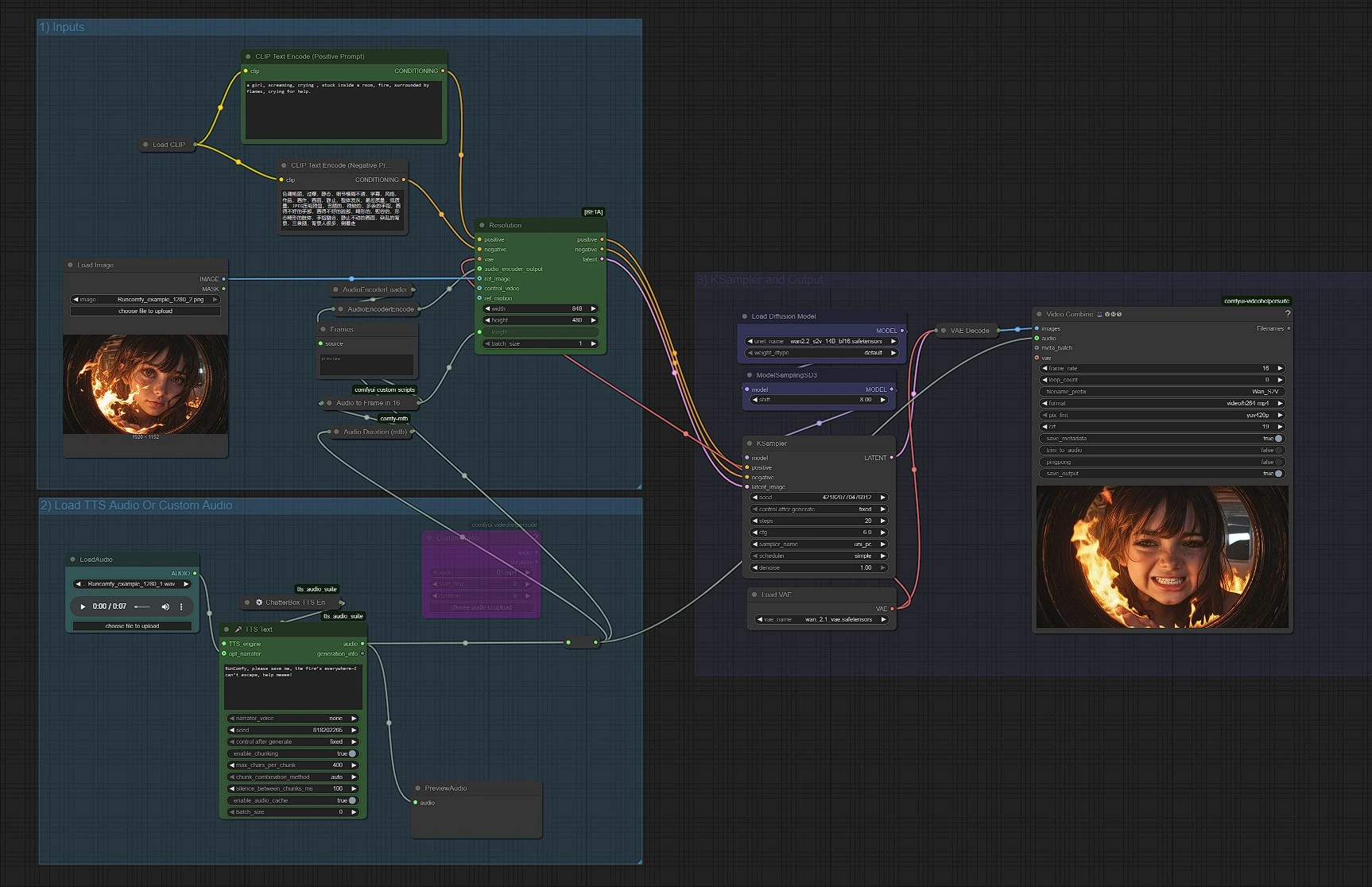
Il workflow è organizzato in tre gruppi. Puoi eseguirli da capo a fine o regolare ogni fase secondo necessità.
1) Inputs#
Questo gruppo carica i componenti di testo, immagine e VAE di Wan, e prepara i tuoi prompt. Usa CLIPLoader (#38) con CLIPTextEncode (#6) per il prompt positivo e CLIPTextEncode (#7) per il prompt negativo per guidare stile e qualità. Carica la tua immagine di riferimento con LoadImage (#52); questo ancora identità, inquadratura e palette per Wan2.2 S2V. Mantieni i prompt positivi descrittivi ma brevi in modo che l'audio mantenga il controllo sul movimento. Il VAE (VAELoader (#39)) e il caricatore del modello (UNETLoader (#37)) sono preconfigurati e solitamente lasciati così.
2) Carica Audio TTS o Audio Personalizzato#
Scegli come fornire l'audio. Per test rapidi, genera discorso con UnifiedTTSTextNode (#71) e anteprima con PreviewAudio (#65). Per usare la tua musica o dialogo, usa LoadAudio (#78) per file locali o VHS_LoadAudioUpload (#87) per upload; entrambi alimentano un Reroute (#88) così che i nodi a valle vedano una singola fonte audio. La durata è misurata da Audio Duration (mtb) (#68), poi convertita in un conteggio di fotogrammi da MathExpression|pysssss (#67) etichettato “Audio to Frame in 16 FPS.” Le caratteristiche audio sono prodotte da AudioEncoderLoader (#57) e AudioEncoderEncode (#56), che insieme forniscono al nodo Wan2.2 S2V un AUDIO_ENCODER_OUTPUT.
3) KSampler e Output#
WanSoundImageToVideo (#55) è il cuore di Wan2.2 S2V. Consuma i tuoi prompt, VAE, caratteristiche audio, immagine di riferimento, e un intero length (fotogrammi) per emettere una sequenza latente condizionata. Quel latente va a KSampler (#3), le cui impostazioni di campionamento governano coerenza e dettaglio complessivi rispettando il tempo guidato dall'audio. Il latente campionato è decodificato da VAEDecode (#8) in fotogrammi, quindi VHS_VideoCombine (#66) assembla il video e mescola il tuo audio originale per produrre un MP4. ModelSamplingSD3 (#54) è usato per impostare la corretta famiglia di sampler per il backbone Wan.
Nodi chiave nel workflow Comfyui Wan2.2 S2V#
WanSoundImageToVideo (#55)#
Guida il movimento sincronizzato con l'audio da un'unica immagine. Imposta ref_image sul ritratto o scena che vuoi animare, collega audio_encoder_output dall'encoder, e fornisci un length in fotogrammi. Aumenta length per clip più lunghi o riduci per anteprime più scattanti. Se cambi FPS altrove, aggiorna il valore dei fotogrammi di conseguenza in modo che il tempo rimanga sincronizzato.
AudioEncoderLoader (#57) e AudioEncoderEncode (#56)#
Carica ed esegui l'encoder basato su Wav2Vec2 che trasforma discorso o musica in caratteristiche che Wan può seguire. Usa discorso pulito per la sincronizzazione labiale, o audio percussivo/pesante di battiti per movimento ritmico. Se la tua lingua di input o dominio differisce, sostituisci un checkpoint compatibile di Wav2Vec2 per migliorare l'allineamento.
CLIPTextEncode (#6) e CLIPTextEncode (#7)#
Encoder di prompt positivi e negativi per il condizionamento UMT5/CLIP. Mantieni i prompt positivi concisi, concentrandoti su soggetto, stile e termini di ripresa; usa i prompt negativi per evitare artefatti indesiderati. I prompt eccessivamente forzati possono contrastare con l'audio, quindi preferisci una guida leggera e lascia che Wan2.2 S2V gestisca il movimento.
KSampler (#3)#
Campiona la sequenza latente prodotta dal nodo Wan2.2 S2V. Regola il tipo di campionatore e i passi per scambiare velocità con fedeltà; mantieni un seme fisso quando desideri un tempo riproducibile con lo stesso audio. Se il movimento sembra troppo rigido o rumoroso, piccoli cambiamenti qui possono migliorare notevolmente la stabilità temporale.
VHS_VideoCombine (#66)#
Crea il video finale e allega l'audio. Imposta frame_rate per adattarlo al tuo FPS previsto e conferma che la lunghezza del clip corrisponda ai tuoi fotogrammi length. Il contenitore, il formato pixel e i controlli di qualità sono esposti per esportazioni rapide; usa qualità superiore quando hai intenzione di post-elaborare in un editor.
Extra opzionali#
- Inizia con un'immagine di riferimento ben illuminata e frontale al tuo rapporto d'aspetto target per minimizzare la deriva dell'identità e il ritaglio.
- Per la sincronizzazione labiale, mantieni la bocca non ostruita e usa narrazione pulita; la musica con forti transitori funziona bene per il movimento guidato dal ritmo.
- La conversione FPS predefinita assume 16 fps; se cambi FPS, aggiorna la matematica in “Audio to Frame in 16 FPS” in modo che i fotogrammi si allineino con la durata dell'audio.
- Usa l'anteprima audio e l'anteprima live VHS per iterare rapidamente, quindi aumenta la qualità una volta che ti piace il tempo.
- Clip più lunghe scalano il calcolo e la VRAM; taglia il silenzio o dividi lunghe sceneggiature in brevi scene quando produci video multi-shot con Wan2.2 S2V.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Riconosciamo con gratitudine Wan-Video per Wan2.2 (incluso codice di inferenza S2V), Wan-AI per Wan2.2-S2V-14B, e Gao et al. (2025) per Wan-S2V: Audio-Driven Cinematic Video Generation per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Wan-Video/Wan2.2 S2V Demo
- GitHub: Wan-Video/Wan2.2
- Hugging Face: Wan-AI/Wan2.2-S2V-14B
- arXiv: Wan-S2V: Audio-Driven Cinematic Video Generation
- Docs / Note di Rilascio: Wan2.2 S2V Demo
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.