
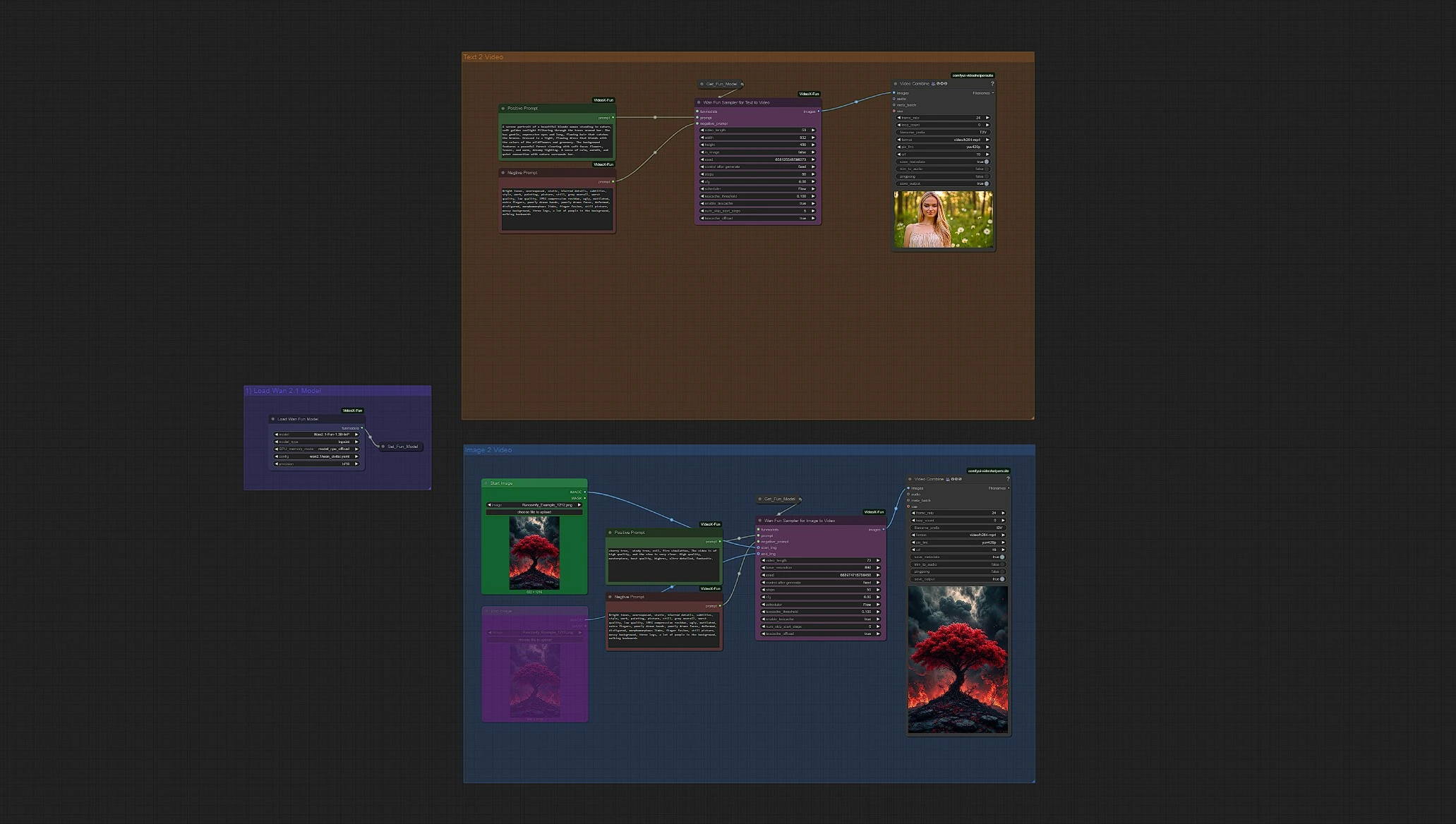
Wan 2.1 Fun | Generazione AI da Immagine a Video e da Testo a Video#
Wan 2.1 Fun Image-to-Video and Text-to-Video offre un flusso di lavoro di generazione video AI altamente versatile che dà vita sia a visuali statiche che a pura immaginazione. Alimentato dalla famiglia di modelli Wan 2.1 Fun, questo flusso di lavoro consente agli utenti di animare una singola immagine in un video completo o generare intere sequenze in movimento direttamente da prompt testuali—senza bisogno di filmati iniziali.
Che tu stia creando paesaggi onirici surreali da poche parole o trasformando un pezzo di concept art in un momento vivente, questo setup Wan 2.1 Fun facilita la produzione di output video coerenti e stilizzati. Con supporto per transizioni fluide, impostazioni di durata flessibili e prompt multilingue, Wan 2.1 Fun è perfetto per narratori, artisti digitali e creatori che desiderano spingere i confini visivi con il minimo sforzo.
Perché utilizzare Wan 2.1 Fun Image-to-Video + Text-to-Video?#
Il flusso di lavoro Wan 2.1 Fun Image-to-Video and Text-to-Video fornisce un modo semplice ed espressivo per generare video di alta qualità da un'immagine o un semplice prompt testuale:
- Converti una singola immagine in movimento con transizioni ed effetti automatici
- Genera video direttamente da prompt testuali, con previsione intelligente dei frame
- Include InP (previsione del frame iniziale/finale) per narrazioni visive controllate
- Funziona con varianti di modelli 1.3B e 14B per qualità e velocità scalabili
- Ottimo per ideazione creativa, narrazione, scene animate e sequenze cinematografiche
Che tu stia visualizzando una scena da zero o animando un'immagine fissa, questo flusso di lavoro Wan 2.1 Fun offre risultati rapidi, accessibili e visivamente impressionanti utilizzando i modelli Wan 2.1 Fun.
Come utilizzare Wan 2.1 Fun Image-to-Video + Text-to-Video?#
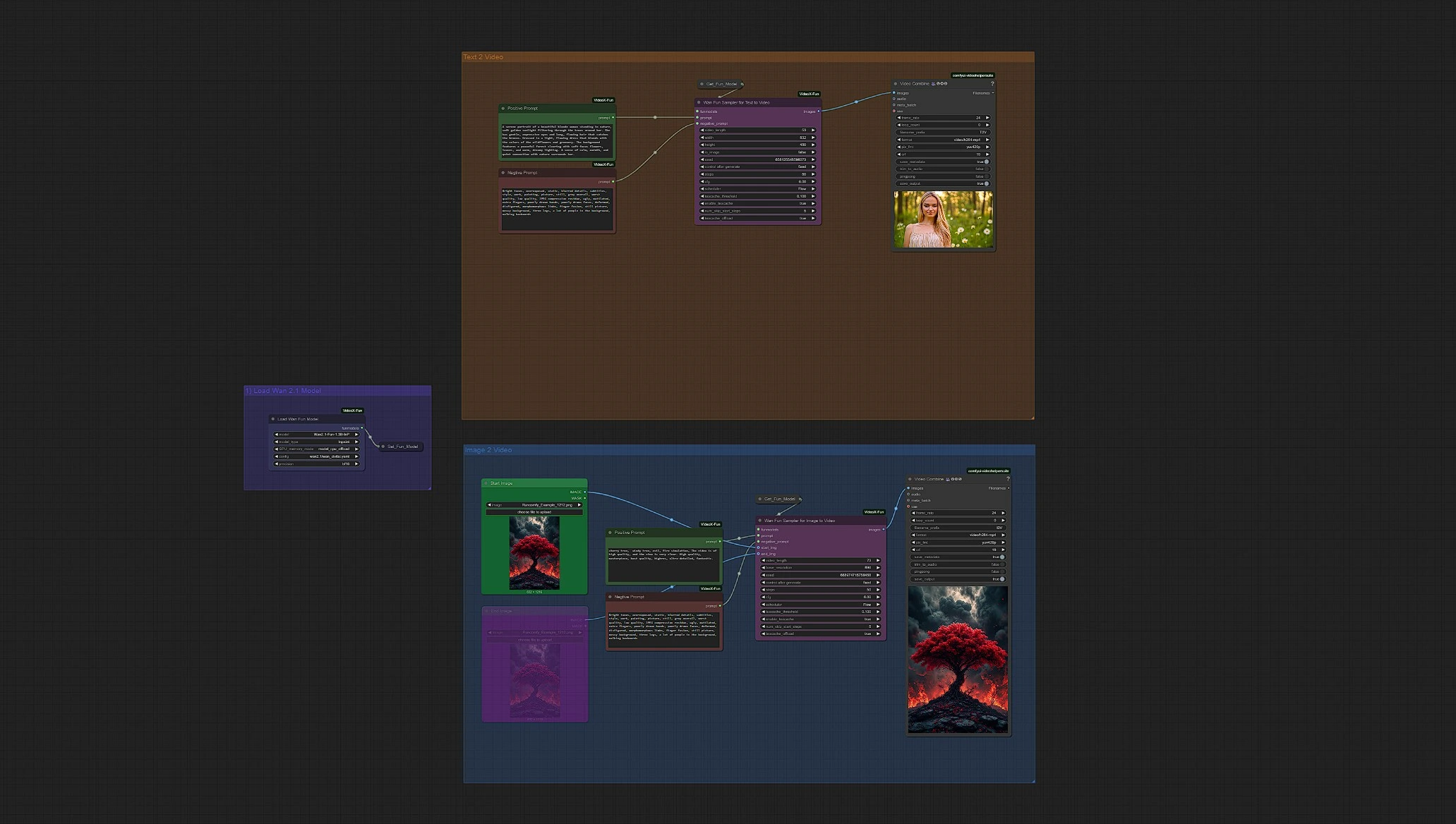
Panoramica di Wan 2.1 Fun Image-to-Video + Text-to-Video#
Load WanFun Model: Carica la variante appropriata del modello Wan 2.1 Fun (1.3B o 14B)Enter Prompts or Upload Image: Supporta sia i prompt testuali che gli input di immagini utilizzando il loro gruppo separatoSet Inference Settings: Regola frame, durata, risoluzione e opzioni di movimentoWan Fun Sampler: Utilizza WanFun per la previsione iniziale/finale e la coerenza temporaleSave Video: Il video di output viene renderizzato e salvato automaticamente dopo il campionamento
Passaggi rapidi per iniziare:#
- Seleziona il tuo modello
Wan 2.1 Funnel gruppo Load Model - Inserisci prompt positivi e negativi per guidare la generazione
- Scegli la modalità di input:
- Carica un'immagine per il gruppo Image-to-Video
- Oppure affidati solo a prompt testuali per il gruppo Text-to-Video
- Regola le impostazioni nel nodo
Wan Fun Sampler(frame, risoluzione, opzioni di movimento) - Esegui il flusso di lavoro cliccando il pulsante
Queue Prompt - Visualizza e scarica il tuo video finale Wan 2.1 Fun dal nodo Video Save (
Outputsfolder)
1 - Carica il modello WanFun#
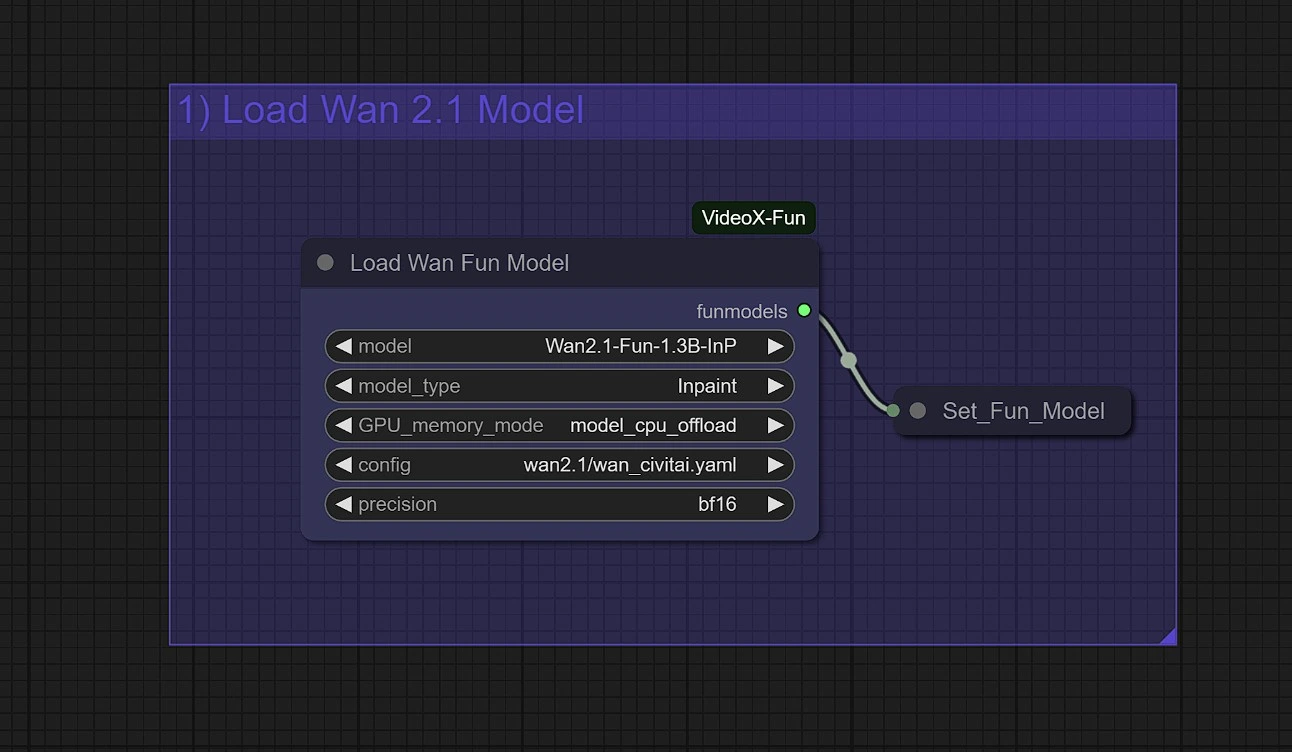
Scegli la giusta variante di modello per il tuo compito:
Wan2.1-Fun-Control (1.3B / 14B): Per generazione video guidata con Depth, Canny, OpenPose e controllo della traiettoriaWan2.1-Fun-InP (1.3B / 14B): Per testo a video con previsione del frame iniziale e finale
Consigli di memoria per Wan 2.1 Fun:
- usa
model_cpu_offloadper una generazione più veloce con 1.3B Wan 2.1 Fun - usa
sequential_cpu_offloadper ridurre l'uso della memoria GPU con 14B Wan 2.1 Fun
2 - Inserisci i prompt#
Nel gruppo appropriato che scegli, Image-2-Video o Text-2-Video, inserisci il tuo prompt positivo e negativo.
- Prompt Positivo:
- guida il movimento, il dettaglio e la profondità del tuo restyling video
- l'uso di un linguaggio descrittivo e artistico può migliorare il tuo output finale Wan 2.1 Fun
- Prompt Negativo:
- l'uso di prompt negativi più lunghi come "Sfocatura, mutazione, deformazione, distorsione, scuro e solido, fumetti." può aumentare la stabilità Wan 2.1 Fun
- l'aggiunta di parole come "silenzioso, solido" può aumentare il dinamismo nei video Wan 2.1 Fun
3 - Gruppo Immagine 2 Video con Wan 2.1 Fun#
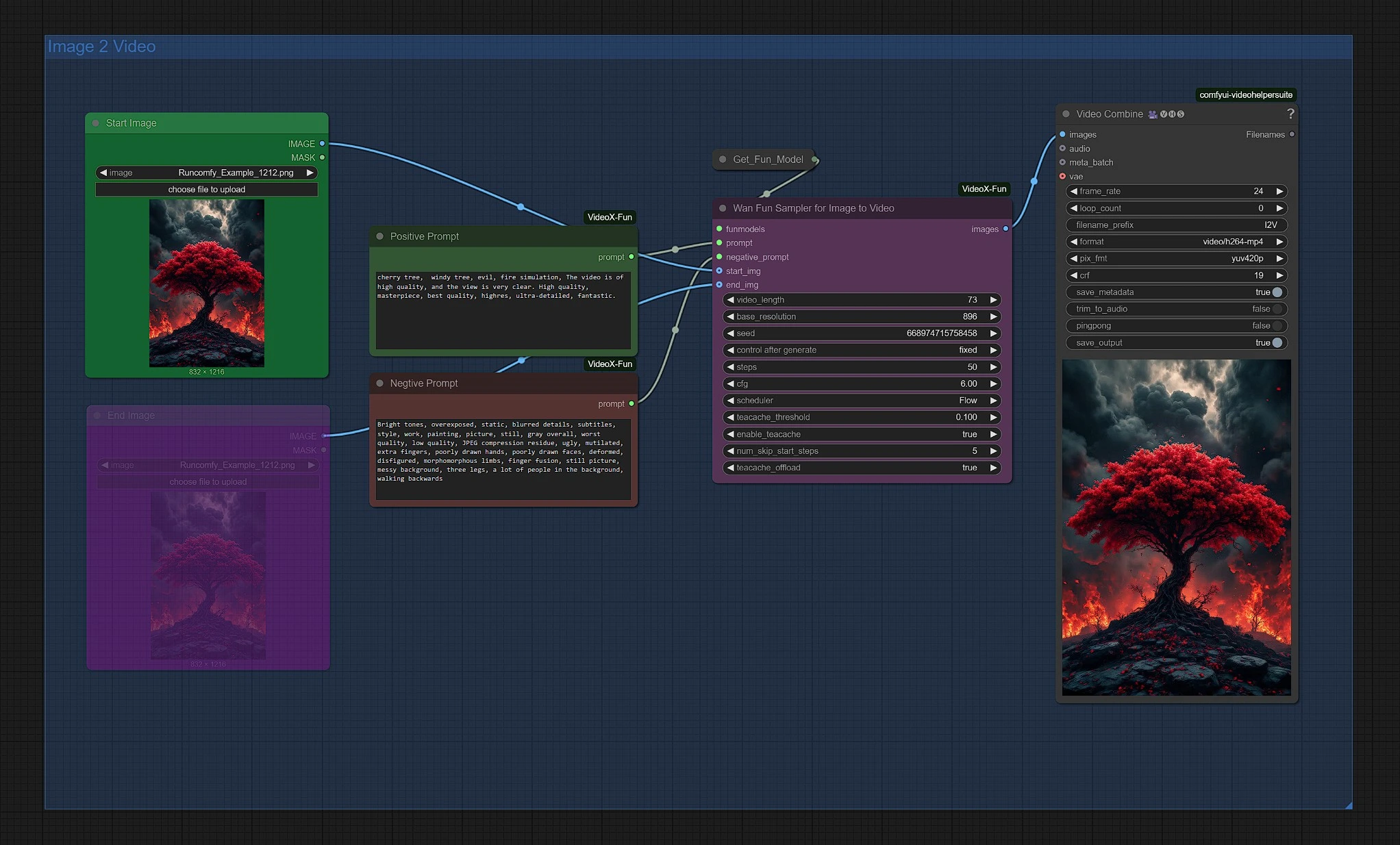
Carica la tua immagine iniziale per avviare la generazione Wan 2.1 Fun. Puoi regolare la risoluzione e la durata nel nodo Wan Fun Sampler.
[Facoltativo] Attiva il nodo dell'immagine finale; questa immagine servirà come immagine finale, con l'intermedio renderizzato attraverso il campionatore Wan 2.1.
Il tuo video finale Wan 2.1 Fun si trova nella cartella Outputs del nodo Video Save.
4 - Gruppo Testo 2 Video con Wan 2.1 Fun#
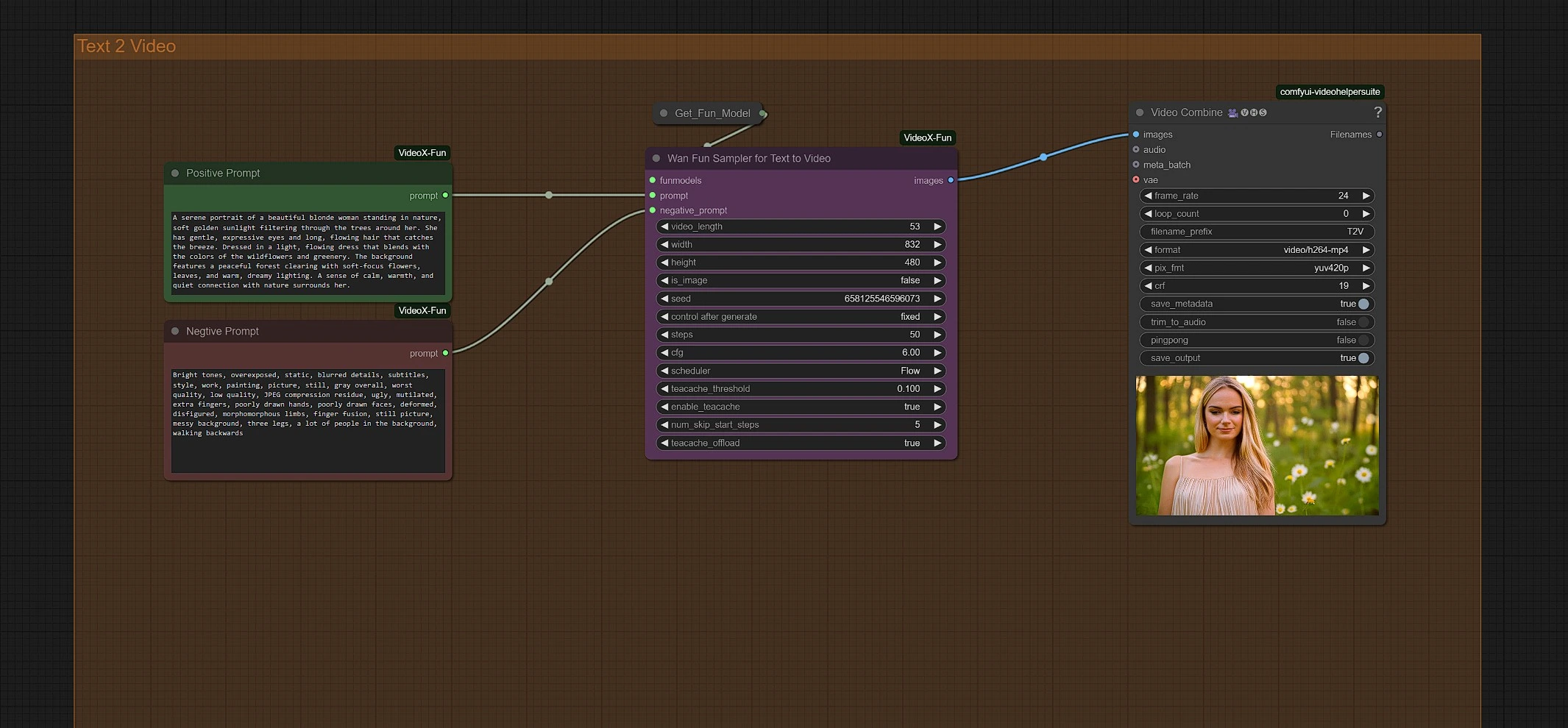
Inserisci i tuoi prompt per avviare la generazione. Puoi regolare la risoluzione e la durata nel nodo Wan Fun Sampler.
Il tuo video finale Wan 2.1 Fun si trova nella cartella Outputs del nodo Video Save.
Riconoscimenti#
Il flusso di lavoro Wan 2.1 Fun Image-to-Video and Text-to-Video è stato sviluppato da bubbliiiing e hkunzhe, il cui lavoro sulla famiglia di modelli Wan 2.1 Fun ha reso la generazione di video basata su prompt più accessibile e flessibile. I loro contributi permettono agli utenti di trasformare sia immagini statiche che puro testo in video dinamici e stilizzati con un setup minimo e la massima libertà creativa utilizzando Wan 2.1 Fun. Apprezziamo profondamente la loro innovazione e l'impatto continuo nello spazio della generazione video AI.