
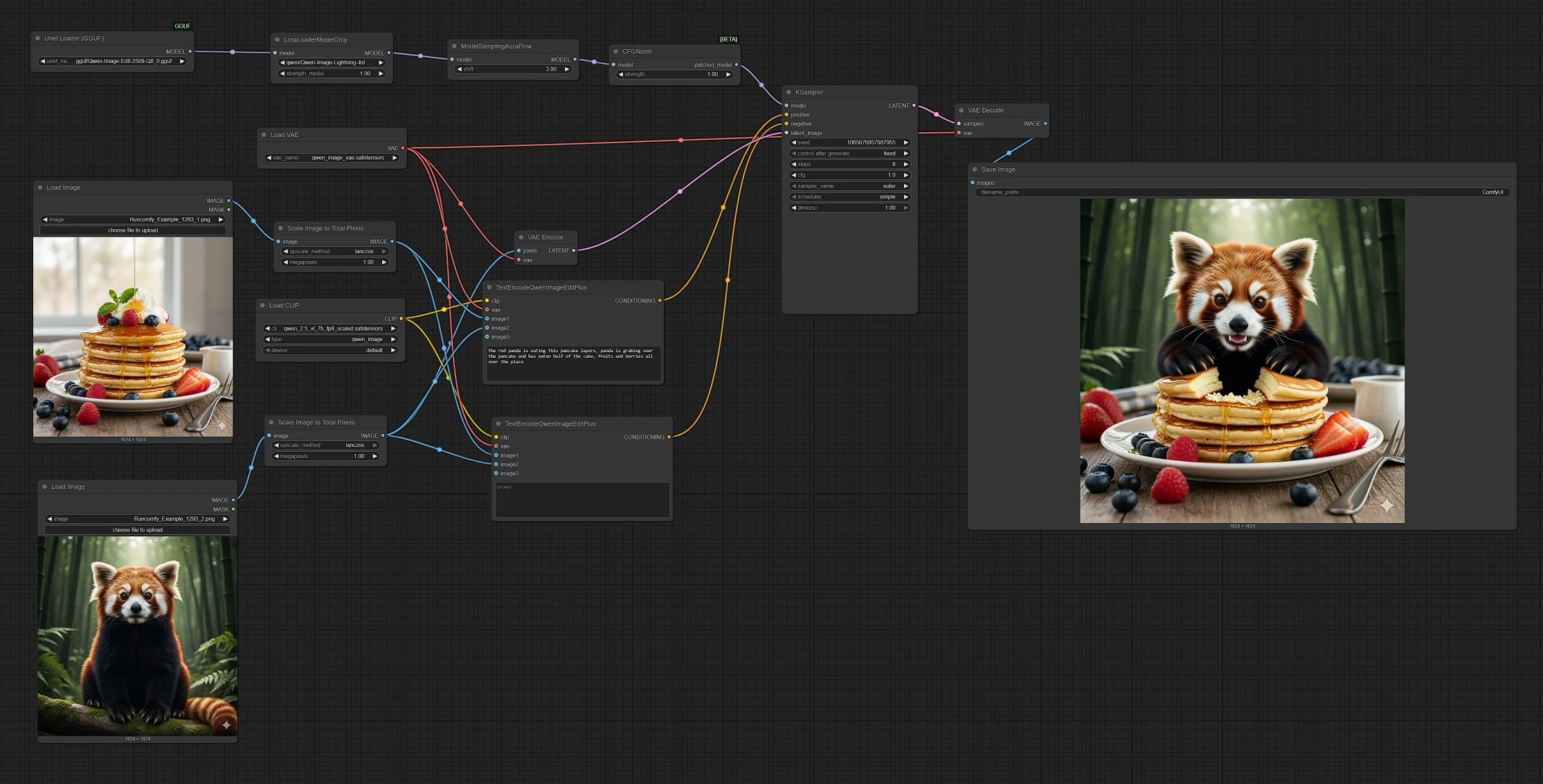






Qwen Image Edit 2509: editing e fusione multi-immagine guidati da prompt per ComfyUI#
Qwen Image Edit 2509 è un workflow di editing multi-immagine per ComfyUI che fonde 2–3 immagini di input sotto un unico prompt per creare modifiche precise e fusioni senza soluzione di continuità. È progettato per i creatori che desiderano comporre oggetti, rielaborare scene, sostituire elementi o fondere riferimenti mantenendo il controllo intuitivo e prevedibile.
Questo grafico ComfyUI abbina il modello di immagine Qwen con un encoder di testo consapevole dell'editing in modo da poter guidare i risultati con linguaggio naturale e uno o più riferimenti visivi. Pronto all'uso, Qwen Image Edit 2509 gestisce il trasferimento di stile, l'inserimento di oggetti e i remix di scene, producendo risultati coerenti anche quando le fonti variano nell'aspetto o nella qualità.
Modelli chiave nel workflow Comfyui Qwen Image Edit 2509#
- Qwen Image Edit 2509 (Diffusion Model & GGUF, Q8_0). Il checkpoint principale per l'editing di immagini, caricato in forma quantizzata per ridurre il VRAM mantenendo il comportamento di editing. Fornisce la base di diffusione che interpreta testo e immagini di riferimento durante il campionamento.
- Qwen Image VAE. Un VAE dedicato progettato per Qwen Image che codifica la tela di base nello spazio latente e decodifica i risultati finali in pixel. Fonte del bene: Comfy-Org/Qwen-Image_ComfyUI.
- Qwen 2.5 VL 7B text encoder (FP8 scalato). Un encoder di testo visione-linguaggio confezionato per ComfyUI che trasforma il tuo prompt più le immagini di riferimento in condizioni di editing. Fonte del bene: Comfy-Org/Qwen-Image_ComfyUI.
- Qwen‑Image‑Lightning‑4steps‑V1.0 LoRA. Un LoRA opzionale che orienta il modello verso aggiornamenti rapidi e ad alto impatto, utile per iterazioni veloci o conteggi di passi bassi. Pagina del modello: lightx2v/Qwen-Image-Lightning.
Come usare il workflow Comfyui Qwen Image Edit 2509#
Questo workflow segue un percorso chiaro dagli input all'output: carichi 2–3 immagini, scrivi un prompt, il grafico codifica sia il testo che i riferimenti, il campionamento avviene su una base latente e il risultato viene decodificato e salvato.
Fase 1 — Carica e dimensiona le tue fonti
- Usa
LoadImage(#103) per l'Immagine 1 eLoadImage(#109) per l'Immagine 2. L'Immagine 2 funge da tela di base che riceverà le modifiche. - Ogni immagine passa attraverso
ImageScaleToTotalPixels(#93 e #108) così entrambe le referenze condividono un budget di pixel coerente. Questo stabilizza la composizione e il trasferimento di stile. - Se desideri una terza referenza, collega un altro
LoadImagenell'inputimage3sui nodi di codifica. Qwen Image Edit 2509 accetta fino a tre immagini per una guida più ricca.
Fase 2 — Scrivi il prompt e imposta l'intento
- L'encoder positivo
TextEncodeQwenImageEditPlus(#104) combina il tuo prompt di testo con Immagine 1 e Immagine 2 per descrivere il risultato che desideri. Usa il linguaggio naturale per richiedere fusioni, sostituzioni o suggerimenti di stile. - L'encoder negativo
TextEncodeQwenImageEditPlus(#106) ti consente di allontanarti dai dettagli indesiderati. Lascialo vuoto per rimanere neutrale o aggiungi frasi che sopprimono artefatti o stili che non vuoi. - Entrambi gli encoder usano l'encoder di testo Qwen e VAE, quindi il modello "vede" i tuoi riferimenti come parte dell'istruzione.
Fase 3 — Prepara il modello
UnetLoaderGGUF(#102) carica la base Qwen Image Edit 2509 in formato GGUF per un'inferenza efficiente.LoraLoaderModelOnly(#89) applica il Qwen‑Image‑Lightning LoRA. Aumenta la sua influenza per modifiche più incisive o riducila per aggiornamenti più conservativi.- Il modello viene quindi preparato per il campionamento con una configurazione ottimizzata per la stabilità dell'editing.
Fase 4 — Generazione guidata
- La tela di base (Immagine 2) è codificata da
VAEEncode(#88) e fornita aKSampler(#3) come latente di partenza. Questo rende l'esecuzione immagine-a-immagine piuttosto che puro testo-a-immagine. KSampler(#3) fonde le condizioni positive e negative con la tela latente per produrre il risultato modificato. Blocca il seme per la riproducibilità o varia per esplorare alternative.- Le scelte di guida e campionamento bilanciano la fedeltà alle tue fonti con l'aderenza al prompt, conferendo a Qwen Image Edit 2509 la sua combinazione di precisione e flessibilità.
Fase 5 — Decodifica e salva
VAEDecode(#8) converte il latente finale in un'immagine, eSaveImage(#60) lo scrive nella tua cartella di output. I nomi dei file riflettono l'esecuzione così puoi confrontare facilmente le versioni.
Nodi chiave nel workflow Comfyui Qwen Image Edit 2509#
TextEncodeQwenImageEditPlus (#104)#
Questo nodo crea la condizione di editing positiva combinando il tuo prompt con fino a tre immagini di riferimento tramite l'encoder Qwen. Usalo per specificare cosa dovrebbe apparire, quale stile adottare e quanto fortemente i riferimenti dovrebbero influenzare il risultato. Inizia con un obiettivo chiaro in una singola frase, quindi aggiungi descrittori di stile o suggerimenti di fotocamera secondo necessità. Gli asset per l'encoder sono confezionati in Comfy-Org/Qwen-Image_ComfyUI.
TextEncodeQwenImageEditPlus (#106)#
Questo nodo forma la condizione negativa per prevenire tratti indesiderati. Aggiungi brevi frasi che bloccano artefatti, eccessiva levigatura o stili non corrispondenti. Mantienilo minimale per evitare di combattere l'intento positivo. Usa lo stesso stack di encoder e VAE Qwen del percorso positivo.
UnetLoaderGGUF (#102)#
Carica il checkpoint Qwen Image Edit 2509 in formato GGUF per un'inferenza amica del VRAM. Una quantizzazione più alta consente di risparmiare memoria ma può influire leggermente sui dettagli fini; se hai margine, prova una quantizzazione meno aggressiva per massimizzare la fedeltà. Riferimento all'implementazione: city96/ComfyUI-GGUF.
LoraLoaderModelOnly (#89)#
Applica il Qwen‑Image‑Lightning LoRA sopra il modello di base per accelerare la convergenza e rafforzare le modifiche. Aumenta strength_model per enfatizzare l'effetto di questo LoRA o abbassalo per una guida più sottile. Pagina del modello: lightx2v/Qwen-Image-Lightning. Riferimento al nodo principale: comfyanonymous/ComfyUI.
ImageScaleToTotalPixels (#93, #108)#
Ridimensiona ciascun input a un conteggio totale di pixel coerente utilizzando il campionamento di alta qualità. Aumentare il target di megapixel produce risultati più nitidi a scapito di tempo e memoria; abbassarlo velocizza l'iterazione. Mantieni entrambe le referenze a scale simili per aiutare Qwen Image Edit 2509 a fondere gli elementi in modo pulito. Riferimento al nodo principale: comfyanonymous/ComfyUI.
KSampler (#3)#
Esegue i passaggi di diffusione che trasformano la tela latente secondo le tue condizioni. Regola i passaggi e il campionatore per bilanciare velocità e fedeltà, e varia il seme per esplorare più composizioni dalla stessa configurazione. Per modifiche strette che preservano la struttura dall'Immagine 2, mantieni i conteggi dei passaggi moderati e affidati al prompt e ai riferimenti per il controllo. Riferimento al nodo principale: comfyanonymous/ComfyUI.
Extra opzionali#
- Tratta l'Immagine 2 come la tela e l'Immagine 1 come il donatore; descrivi nel prompt quali elementi dovrebbero trasferirsi e quali dovrebbero rimanere.
- Usa negativi concisi per frenare aloni, deriva delle texture o eccessiva stilizzazione; liste negative lunghe possono confliggere con il tuo obiettivo.
- Se i risultati sembrano troppo conservativi, aumenta leggermente la forza del LoRA o i passaggi di campionamento; se si allontanano troppo dalla base, riducili.
- Aumenta il target di megapixel quando finalizzi, quindi riutilizza lo stesso seme per ingrandire la composizione esatta che ti piaceva.
- Mantieni i prompt concreti: soggetto, azione, ambientazione e stile. Qwen Image Edit 2509 risponde meglio a un intento chiaro con pochi descrittori forti.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine RobbaW per il Qwen Image Edit 2509 Workflow per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- RobbaW/Qwen Image Edit 2509 Workflow
- Hugging Face: QuantStack/Qwen-Image-Edit-2509-GGUF
- Documenti / Note di rilascio: Qwen Image Edit 2509 Workflow @RobbaW from Reddit r/comfyui
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.



