
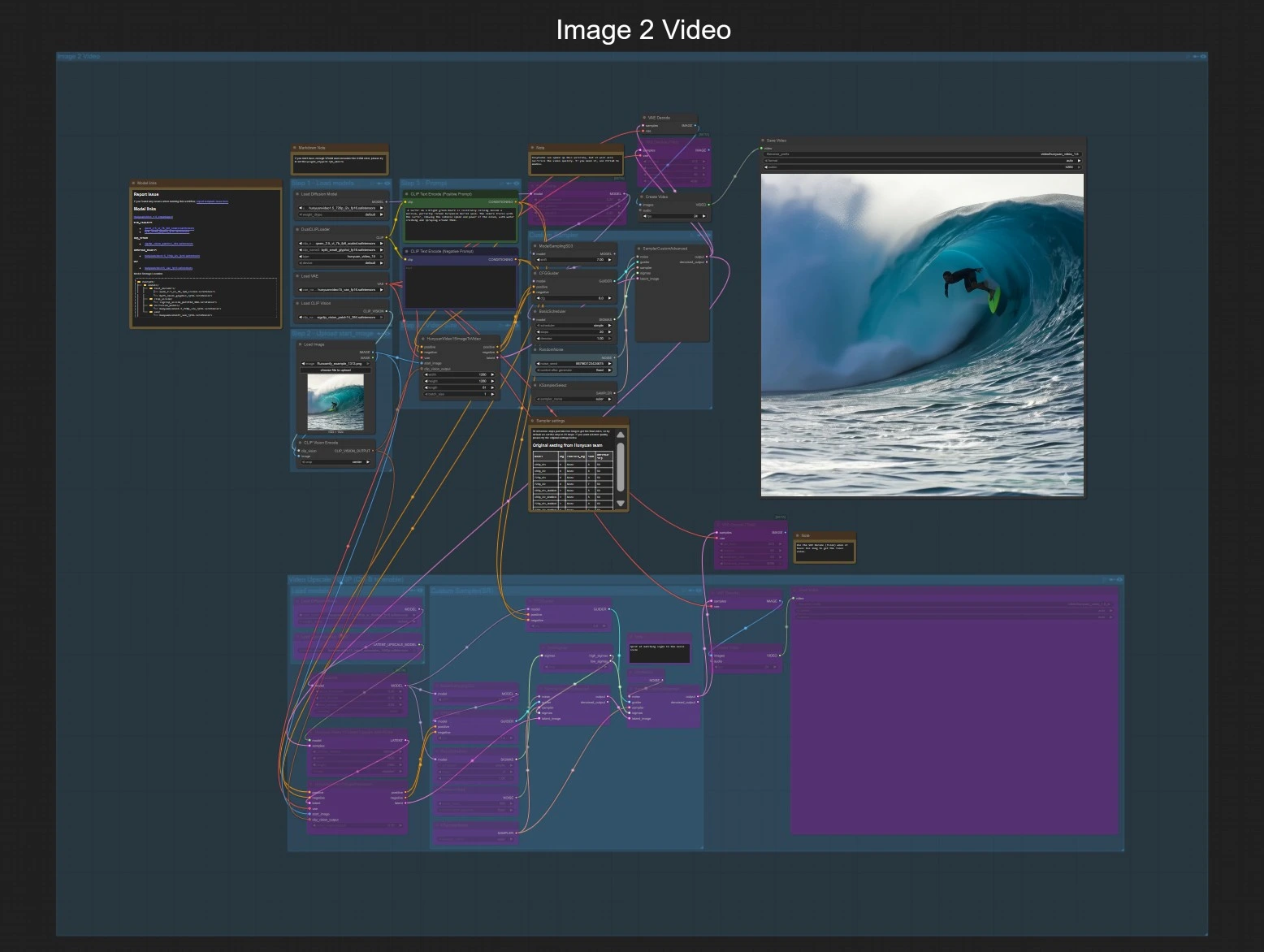
Workflow Hunyuan Video 1.5 ComfyUI: conversione rapida da testo a video e da immagine a video con super risoluzione a 1080p#
Questo workflow avvolge Hunyuan Video 1.5 in ComfyUI per offrire una generazione di video rapida e coerente su GPU consumer. Supporta sia la conversione da testo a video sia da immagine a video, quindi opzionalmente effettua l'upscaling a 1080p utilizzando un upsampler latente dedicato e un modello di super-risoluzione distillato. Sotto il cofano, Hunyuan Video 1.5 accoppia un Diffusion Transformer con un VAE causale 3D e una strategia di attenzione a tessere scorrevoli selettiva per bilanciare qualità, fedeltà del movimento e velocità.
I creatori, i team di prodotto e i ricercatori possono utilizzare questo workflow ComfyUI Hunyuan Video 1.5 per iterare rapidamente da prompt o da un'immagine fissa singola, effettuare un'anteprima a 720p e completare con output nitidi a 1080p quando necessario.
Modelli chiave nel workflow Comfyui Hunyuan Video 1.5#
- HunyuanVideo 1.5 720p Image-to-Video UNet. Produce coerenza di movimento e temporale da un'immagine di partenza. I pesi sono forniti nel repackage Comfy-Org su Hugging Face Comfy-Org/HunyuanVideo_1.5_repackaged.
- HunyuanVideo 1.5 720p Text-to-Video UNet. Genera video direttamente dai prompt testuali utilizzando la stessa architettura di base, ottimizzata per i workflow prompt-first. Vedi il repository repackage sopra.
- HunyuanVideo 1.5 1080p Super-Resolution UNet (distillato). Affina i latenti a 720p a un dettaglio più elevato preservando movimento e struttura della scena. Incluso nello stesso repackage su Hugging Face.
- HunyuanVideo 1.5 3D VAE. Codifica e decodifica i latenti video per una generazione efficiente e una decodifica a tessere.
- HunyuanVideo 1.5 Latent Upsampler 1080p. Scala le sequenze latenti a 1920×1080 prima del perfezionamento SR per velocità ed efficienza della memoria.
- Qwen 2.5 VL 7B text encoder e ByT5 Small text encoder. Forniscono robusta interpretazione delle istruzioni e tokenizzazione per prompt diversi, reimpacchettati per questo workflow nel pacchetto Hugging Face sopra. La scheda modello originale di ByT5: google/byt5-small.
- SigCLIP Vision (ViT-L/14, 384). Estrae caratteristiche visive di alta qualità dall'immagine di partenza per guidare il conditioning da immagine a video: Comfy-Org/sigclip_vision_384.
Come utilizzare il workflow Comfyui Hunyuan Video 1.5#
Questo grafico espone due percorsi indipendenti che condividono lo stesso stadio di esportazione e finitura opzionale a 1080p. Scegli Image to Video o Text to Video, quindi abilita opzionalmente il gruppo 1080p per finalizzare.
Image to Video#
Step 1 — Carica modelli I loader portano l'UNet Hunyuan Video 1.5 per image-to-video, il VAE 3D, i due encoder testuali e la visione SigCLIP. Questo prepara il workflow per accettare un'immagine di partenza e un prompt. Non è necessaria alcuna azione dell'utente oltre a confermare che i modelli siano disponibili.
Step 2 — Carica immagine di partenza Fornisci un'immagine pulita e ben esposta in LoadImage (#80). Il grafico codifica questa immagine con CLIPVisionEncode (#79) in modo che Hunyuan Video 1.5 possa ancorare movimento e stile al tuo riferimento. Preferisci immagini che corrispondano approssimativamente al tuo rapporto d'aspetto target per ridurre ritagli o padding.
Step 3 — Prompt Scrivi la tua descrizione in CLIP Text Encode (Positive Prompt) (#44). Usa il prompt negativo CLIP Text Encode (Negative Prompt) (#93) per evitare artefatti o stili indesiderati. Mantieni i prompt concisi ma specifici su soggetto, movimento e comportamento della telecamera.
Step 4 — Dimensione e durata del video HunyuanVideo15ImageToVideo (#78) imposta la risoluzione spaziale e il numero di fotogrammi da sintetizzare. Sequenze più lunghe richiedono più VRAM e tempo, quindi inizia con sequenze più brevi e aumenta una volta che ti piace il movimento.
Campionamento personalizzato Lo stack di campionamento (ModelSamplingSD3 (#130), CFGGuider (#129), BasicScheduler (#126), KSamplerSelect (#128), RandomNoise (#127), SamplerCustomAdvanced (#125)) controlla la forza della guida, i passi, il tipo di campionatore e il seed. Aumenta i passi per maggiore dettaglio e stabilità, e usa un seed fisso per riprodurre i risultati quando iteri sui prompt.
Anteprima e salva La sequenza latente viene decodificata con VAEDecode (#8), incorniciata in un video a 24 fps con CreateVideo (#101) e scritta da SaveVideo (#102). Questo ti offre un'anteprima rapida a 720p pronta per essere revisionata.
Finitura a 1080p (opzionale) Attiva il gruppo “Video Upscale 1080P” per abilitare la catena di finitura. L'upsampler latente si espande a 1920×1080, poi l'UNet di super-risoluzione distillato affina i dettagli in due fasi. VAEDecodeTiled e una seconda coppia CreateVideo/SaveVideo esportano il risultato a 1080p.
Text to Video#
Step 1 — Carica modelli I loader recuperano l'UNet Hunyuan Video 1.5 720p text-to-video, il VAE 3D e i due encoder testuali. Questo percorso non richiede un'immagine di partenza.
Step 3 — Prompt Inserisci la tua descrizione nell'encoder positivo CLIP Text Encode (Positive Prompt) (#149) e opzionalmente aggiungi un prompt negativo in CLIP Text Encode (Negative Prompt) (#155). Descrivi scena, soggetto, movimento e telecamera, mantenendo il linguaggio concreto.
Step 4 — Dimensione e durata del video EmptyHunyuanVideo15Latent (#183) alloca il latente iniziale con la larghezza, l'altezza e il conteggio dei fotogrammi scelti. Usalo per impostare quanto lungo e quanto grande dovrebbe essere il tuo video.
Campionamento personalizzato ModelSamplingSD3 (#165), CFGGuider (#164), BasicScheduler (#161), KSamplerSelect (#163), RandomNoise (#162), e SamplerCustomAdvanced (#166) collaborano per trasformare il rumore in un video coerente guidato dal tuo testo. Regola i passi e la guida per scambiare velocità con fedeltà, e fissa il seed per rendere le esecuzioni comparabili.
Anteprima e salva I fotogrammi decodificati sono assemblati da CreateVideo (#168) e salvati da SaveVideo (#167) per una rapida revisione a 720p a 24 fps.
Finitura a 1080p (opzionale) Abilita il gruppo “Video Upscale 1080P” per effettuare l'upscaling dei latenti a 1080p e affinare con l'UNet SR distillato. Il campionamento a due fasi migliora la nitidezza mantenendo il movimento. Un decodificatore a tessere e una seconda fase di salvataggio esportano il video finale a 1080p.
Nodi chiave nel workflow Comfyui Hunyuan Video 1.5#
HunyuanVideo15ImageToVideo (#78) Genera un video condizionando su un'immagine di partenza e sui tuoi prompt. Regola la sua risoluzione e il totale dei fotogrammi per corrispondere al tuo obiettivo creativo. Risoluzioni più elevate e clip più lunghe aumentano VRAM e tempo. Questo nodo è centrale per la qualità da immagine a video perché fonde le caratteristiche CLIP-Vision con la guida testuale prima del campionamento.
EmptyHunyuanVideo15Latent (#183) Inizializza la griglia latente per il text-to-video con larghezza, altezza e conteggio dei fotogrammi. Usalo per definire la lunghezza della sequenza in anticipo in modo che il programmatore e il campionatore possano pianificare una traiettoria di denoising stabile. Mantieni il rapporto d'aspetto coerente con il tuo output previsto per evitare padding extra più tardi.
CFGGuider (#129) Imposta la forza della guida classifier-free, bilanciando l'aderenza al prompt contro la naturalezza. Aumenta la guida per seguire il prompt più strettamente; abbassala per ridurre l'oversaturazione e lo sfarfallio. Usa valori moderati durante la generazione di base e abbassa la guida per il perfezionamento della super-risoluzione.
BasicScheduler (#126) Controlla il numero di passi di denoising e il programma. Più passi solitamente significano maggior dettaglio e stabilità ma rendering più lunghi. Abbina il conteggio dei passi alla scelta del campionatore per i migliori risultati; questo workflow predefinisce un campionatore veloce e generico.
SamplerCustomAdvanced (#125) Esegue il ciclo di denoising con il campionatore e la guida selezionati. Nella catena di finitura a 1080p, funziona in due fasi divise da SplitSigmas per stabilire prima la struttura a rumore più alto e poi affinare i dettagli a basso rumore. Mantieni i seed fissi mentre ottimizzi passi e guida in modo da poter confrontare gli output in modo affidabile.
HunyuanVideo15LatentUpscaleWithModel (#109) Scala la sequenza latente a 1920×1080 utilizzando l'upsampler dedicato dai pesi reimpacchettati. L'upscaling nello spazio latente è più veloce e più efficiente in termini di memoria rispetto al ridimensionamento nello spazio pixel, e prepara il terreno per il modello SR distillato per aggiungere dettagli fini. Obiettivi più grandi richiedono più VRAM; mantieni 16:9 per la migliore produttività.
HunyuanVideo15SuperResolution (#113) Affina il latente upscalato con l'UNet SR distillato a 1080p dal pacchetto Hunyuan Video 1.5, opzionalmente prendendo spunto dall'immagine di partenza e dagli indizi CLIP-Vision per la coerenza. Questo aggiunge texture nitide e linee di lavoro mantenendo il movimento. I pesi SR sono disponibili in Comfy-Org/HunyuanVideo_1.5_repackaged.
EasyCache (#116) Memorizza in cache gli stati intermedi dei modelli per accelerare le iterazioni di anteprima. Abilitalo quando desideri un turnaround più rapido e disabilitalo per la massima qualità nel passaggio finale. È particolarmente utile quando si iterano i prompt con la stessa risoluzione e durata.
Extra opzionali#
- Mantieni i prompt concreti. Descrivi soggetto, verbi di movimento e movimenti di telecamera. Usa un breve prompt negativo per sopprimere artefatti che vedi ripetutamente.
- Preferisci immagini di partenza pulite e ad alto contrasto per image-to-video. Abbina il rapporto d'aspetto alla tua risoluzione target per minimizzare il padding.
- Per velocità, itera a durate più brevi e 720p; attiva il gruppo 1080p solo per le esecuzioni finali.
- Se la VRAM è limitata, attiva il decode VAE a tessere e considera di caricare i pesi in una impostazione di precisione inferiore esposta dal caricatore di modelli.
- Fissa i seed mentre ottimizzi passi, guida e formulazione per rendere le modifiche misurabili tra le esecuzioni.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine Comfy.org per il tutorial sul workflow Hunyuan Video 1.5 per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Hunyuan Video 1.5 Source
- Docs / Note di Rilascio: Hunyuan Video 1.5 Source
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.