
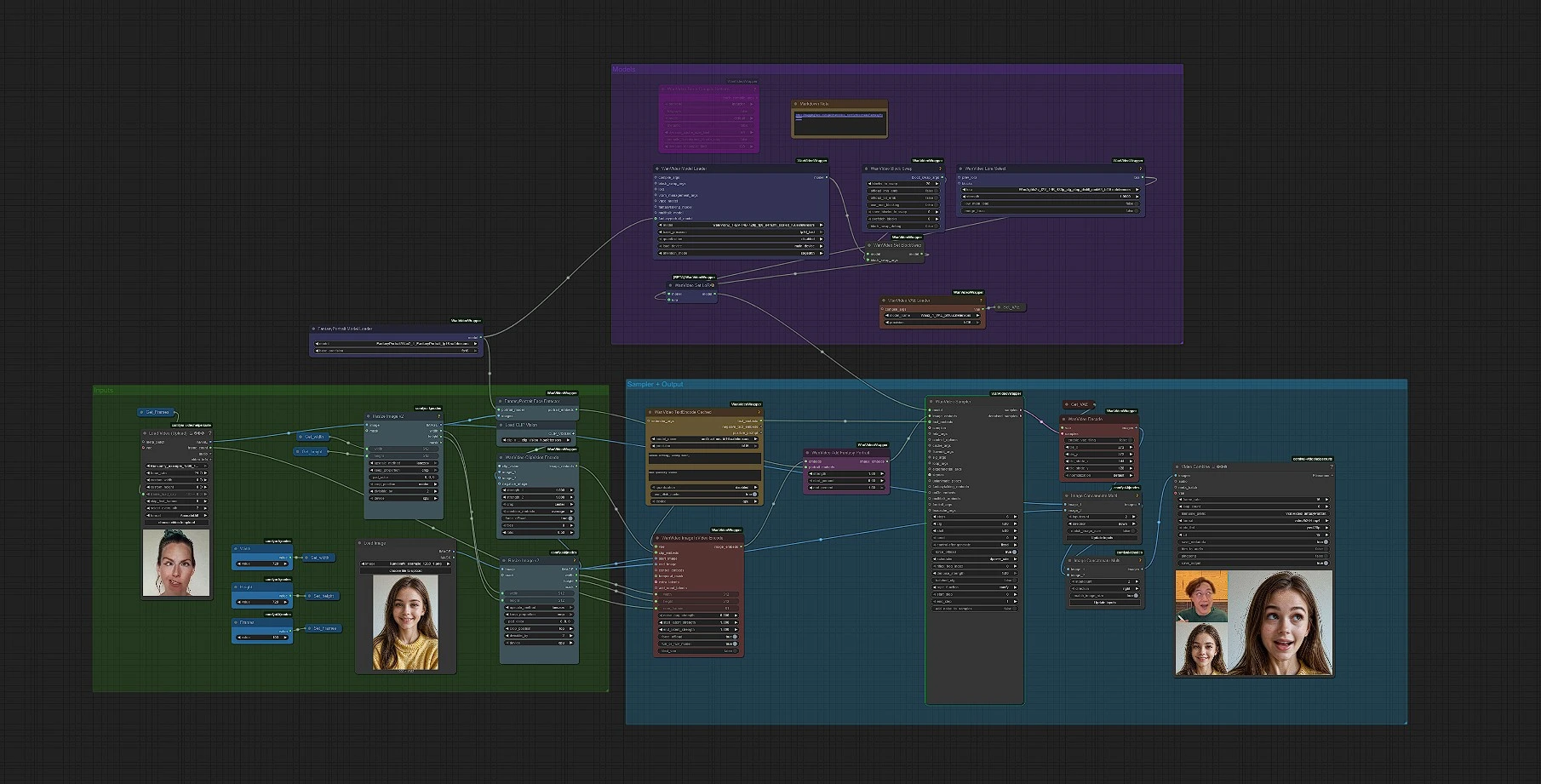
Ritratto Fantasy: Animazione di ritratto ricca di espressioni in ComfyUI#
Questo flusso di lavoro trasforma una singola immagine statica in un'animazione di Ritratto Fantasy ad alta fedeltà. Integra il modello FantasyPortrait di Fantasy-AMAP con trasformatori di diffusione arricchiti di espressioni e lo avvolge in una pipeline di immagine-a-video Wan Video 2.1, così puoi generare scene parlanti dense di emozioni e conservazione dell'identità con un'impostazione minima. È progettato per i creatori che vogliono movimento cinematografico di Ritratto Fantasy da una singola foto, con controlli chiari per l'inquadratura, la durata e lo stile.
La pipeline è completamente automatizzata: inserisci un ritratto, scegli la tua risoluzione e il numero di fotogrammi, opzionalmente aggiungi un prompt e LoRA, quindi rendi in MP4. Sotto il cofano, il grafico rileva il volto, codifica l'immagine e la guida testuale, fonde gli embedding di identità di Ritratto Fantasy nel condizionatore I2V di Wan, campiona un video e decodifica i fotogrammi prima di salvare il clip finale.
Modelli chiave nel flusso di lavoro ComfyUI Ritratto Fantasy#
FantasyPortrait (Fantasy-AMAP)
Modulo di identità ed espressione principale. Fornisce embedding arricchiti di espressioni che preservano i tratti del soggetto consentendo un movimento facciale sfumato. GitHub | Paper (arXiv)
WanVideo 2.1 I2V (14B, 720p)
Ossatura di diffusione video utilizzata per il campionamento dell'animazione dal ritratto e condizionamento testo/immagine. Pesi quantizzati, pronti per Comfy, sono disponibili tramite il pacchetto modello di Kijai. Hugging Face: Kijai/WanVideo_comfy
UMT5-XXL encoder
Encoder di testo ad alta capacità utilizzato per la guida dei prompt nel campionatore video. Peso di esempio: umt5-xxl-enc-bf16.safetensors in Kijai/WanVideo_comfy
Wan 2.1 VAE
VAE ottimizzato per video per la codifica/decodifica dei latenti. Peso di esempio: Wan2_1_VAE_bf16.safetensors in Kijai/WanVideo_comfy
Come usare il flusso di lavoro ComfyUI Ritratto Fantasy#
Il flusso di lavoro funziona da sinistra a destra dagli input al video finale. Imposterai principalmente tre cose all'inizio: immagine, dimensioni e durata. Poi puoi affinare con un breve prompt o un LoRA se lo desideri.
1) Input immagine e dimensionamento#
Carica un singolo ritratto in LoadImage, quindi viene ridimensionato per l'elaborazione. Due fasi di ridimensionamento assicurano che l'immagine corrisponda alla larghezza e all'altezza scelte mantenendo la composizione. Usa i controlli Width, Height e Frames per definire la dimensione di uscita (predefinito 720 × 720) e la lunghezza dell'animazione. Questo mantiene il tuo inquadramento di Ritratto Fantasy coerente in tutta la pipeline.
2) Rilevamento del volto e embedding di Ritratto Fantasy#
FantasyPortraitModelLoader carica i pesi di FantasyPortrait, e FantasyPortraitFaceDetector estrae embedding di ritratti consapevoli di identità ed espressione dalla tua immagine. L'idea principale è separare chi è il soggetto da come esprime emozioni, in modo che l'animazione finale preservi l'identità consentendo un movimento espressivo. Non è necessario sintonizzare nulla qui a meno che non si cambino i modelli.
3) Condizionamento immagine e testo#
Per la guida dell'immagine, CLIPVisionLoader con WanVideoClipVisionEncode produce robuste caratteristiche visive dal ritratto. Per la guida del testo, WanVideoTextEncodeCached utilizza l'encoder UMT5-XXL per trasformare i tuoi prompt positivi e negativi in embedding di condizione video. Un prompt breve e semplice come "primo piano in studio naturale, sorriso gentile" è spesso sufficiente per un aspetto pulito di Ritratto Fantasy.
4) Codifica I2V con controllo della durata#
VHS_LoadVideo è utilizzato come comodo contatore di fotogrammi. Puoi lasciare il clip segnaposto o caricare un riferimento con la durata preferita; il suo conteggio dei fotogrammi alimenta WanVideoImageToVideoEncode, che trasforma la tua immagine di partenza più gli embedding immagine/testo in condizionamento I2V. Se preferisci una lunghezza fissa, imposta direttamente Frames e ignora il caricatore di riferimento.
5) Fusione di Ritratto Fantasy#
WanVideoAddFantasyPortrait fonde il condizionamento I2V con gli embedding del ritratto dal passaggio 2. Questo è ciò che dà all'animazione finale di Ritratto Fantasy la sua forte preservazione dell'identità e il dettaglio espressivo. Non sono necessari input aggiuntivi una volta caricata l'immagine.
6) Configurazione del modello e LoRA#
WanVideoModelLoader carica Wan 2.1, quindi WanVideoLoraSelect applica opzionalmente un I2V LoRA leggero dal pacchetto Kijai per influenzare il movimento o l'estetica senza riaddestramento. Questo è un buon punto per sperimentare se desideri un Ritratto Fantasy leggermente più stilizzato mantenendo l'identità intatta.
7) Campionamento video e decodifica#
WanVideoSampler genera fotogrammi latenti usando il condizionamento fuso. Mantieni i prompt semplici, aumenta i passi moderatamente se hai bisogno di più dettagli, e evita di sovra-constraining con negativi lunghi. WanVideoDecode converte i latenti in immagini, e il flusso di lavoro concatena le anteprime prima che VHS_VideoCombine scriva un MP4 (predefinito 16 fps, yuv420p). Il prefisso del nome del file di output è impostato per comodità.
Nodi chiave nel flusso di lavoro ComfyUI Ritratto Fantasy#
FantasyPortraitModelLoader (#138)#
Carica i pesi di FantasyPortrait. Scambia qui se stai testando un rilascio più recente di Fantasy-AMAP. Non è richiesta alcuna sintonizzazione, ma mantieni la precisione coerente con il tuo modello Wan e VAE.
FantasyPortraitFaceDetector (#142)#
Estrae gli embedding dei ritratti dall'immagine ridimensionata. Buoni risultati provengono da foto ben illuminate, frontali e con minima occlusione. Se il movimento sembra disallineato, verifica il ritaglio di input e prova con un'immagine sorgente più pulita.
WanVideoImageToVideoEncode (#151)#
Costruisce il condizionamento I2V di Wan dalle caratteristiche dell'immagine CLIP, la tua immagine di partenza e la durata. Regola width, height, e num_frames per controllare l'impronta del rendering e la lunghezza. Sequenze più lunghe richiedono più VRAM e tempo.
WanVideoAddFantasyPortrait (#150)#
Fonde identità/espressioni del Ritratto Fantasy nel condizionatore I2V. Usa questo per mantenere il soggetto riconoscibilmente lo stesso attraverso i fotogrammi consentendo cambiamenti di espressione sfumati. Nessun parametro richiede tipicamente aggiustamenti.
WanVideoSampler (#149)#
Genera i latenti video. Se vuoi dettagli più nitidi, aumenta i passi moderatamente. Se il movimento deraglia, riduci la complessità del prompt o prova un LoRA differente. Mantieni la guida coerente piuttosto che prolissa.
WanVideoTextEncodeCached (#155)#
Codifica i prompt positivi/negativi con UMT5-XXL. Usa frasi brevi e descrittive. Prompt negativi troppo forti (ad esempio, stack pesanti di "cattiva qualità") possono sopprimere l'espressione.
Consigli#
- Inizia con 720 × 720 quadrato e 4 a 6 secondi per iterazioni veloci, poi scala se necessario.
- Usa un ritratto pulito, illuminato frontalmente con occhi visibili. Evita occlusioni pesanti, occhiali da sole o angoli estremi.
- Mantieni i prompt di Ritratto Fantasy concisi. Descrivi l'illuminazione e l'umore, non l'identità.
- Prova un LoRA delicato dal pacchetto Kijai se vuoi una sensazione di movimento diversa senza perdere l'identità.
Riconoscimenti#
Questo flusso di lavoro sfrutta il modello Ritratto Fantasy del team Fantasy-AMAP, integrando Transformers di Diffusione Arricchiti di Espressione in ComfyUI per una pipeline di animazione di ritratto completamente automatizzata e di alta qualità. Un ringraziamento speciale a kijai per aver creato e integrato il nodo Wan Video Wrapper, rendendo possibile eseguire l'animazione del ritratto in un framework immagine-a-video senza soluzione di continuità. Ringraziamo anche la più ampia comunità di ComfyUI per i continui contributi agli strumenti creativi aperti.
Link:
