
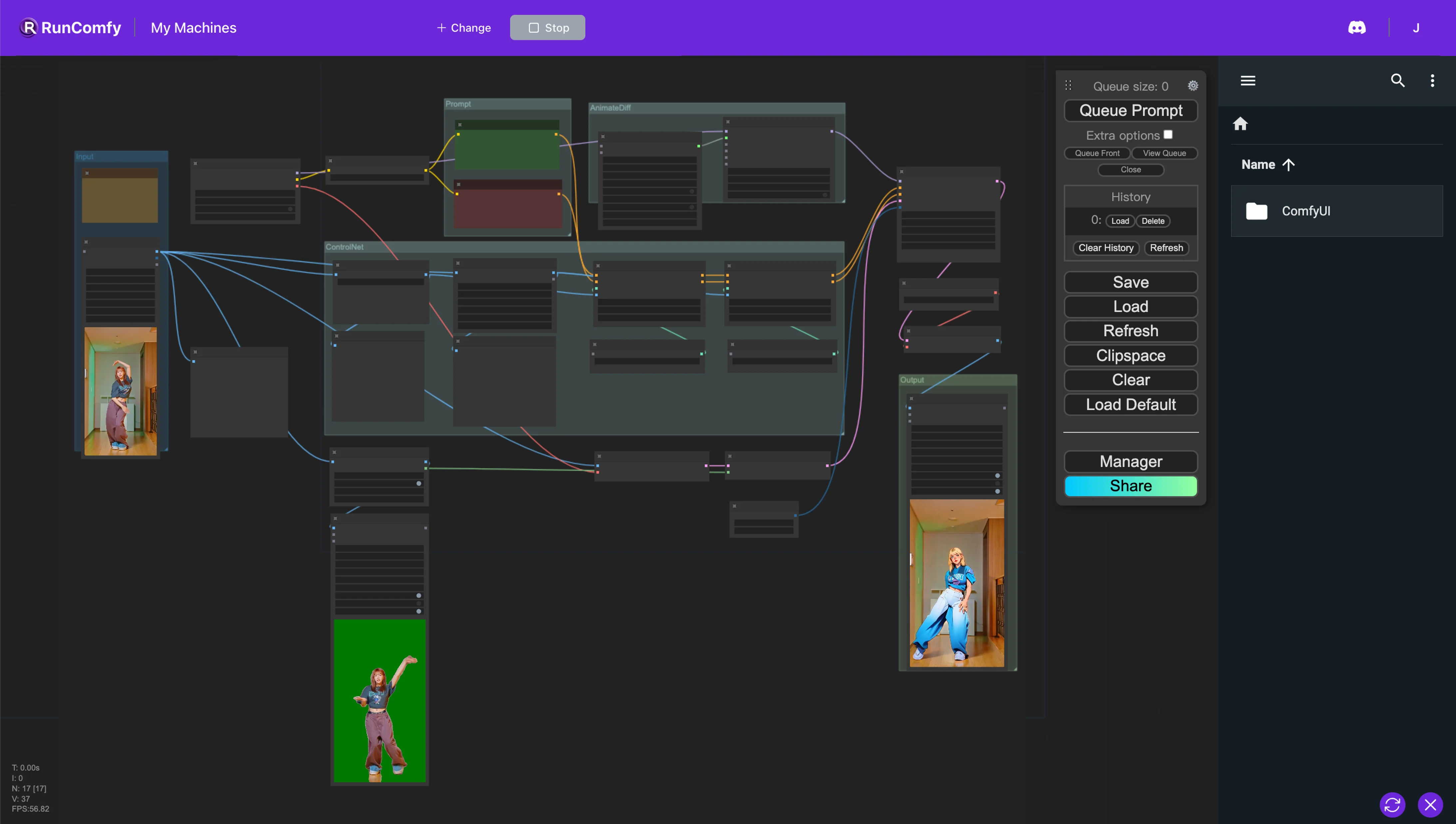
1. Workflow ComfyUI AnimateDiff, ControlNet e Auto Mask#
Questo workflow di ComfyUI introduce un potente approccio per la rielaborazione dei video, specificamente mirato a trasformare i personaggi in uno stile anime preservando gli sfondi originali. Questa trasformazione è supportata da diversi componenti chiave, tra cui AnimateDiff, ControlNet e Auto Mask.
AnimateDiff è progettato per tecniche di animazione differenziale, consentendo il mantenimento di un contesto coerente all'interno delle animazioni. Questo componente si concentra sull'addolcimento delle transizioni e sul miglioramento della fluidità del movimento nei contenuti video rielaborati.
ControlNet svolge un ruolo critico nella replica e manipolazione precisa delle pose umane. Sfrutta la stima avanzata della posa per catturare e controllare accuratamente le sfumature del movimento umano, facilitando la trasformazione dei personaggi in forme anime preservando le loro pose originali.
Auto Mask è coinvolto nella segmentazione automatica, abile nell'isolare i personaggi dagli sfondi. Questa tecnologia consente una rielaborazione selettiva degli elementi video, garantendo che le trasformazioni dei personaggi vengano eseguite senza alterare l'ambiente circostante, mantenendo l'integrità degli sfondi originali.
Questo workflow di ComfyUI realizza la conversione di contenuti video standard in animazioni stilizzate, concentrandosi sull'efficienza e sulla qualità della generazione di personaggi in stile anime.
2. Panoramica di AnimateDiff#
2.1. Introduzione ad AnimateDiff#
AnimateDiff emerge come uno strumento AI progettato per animare immagini statiche e prompt di testo in video dinamici, sfruttando i modelli di Stable Diffusion e un modulo di movimento specializzato. Questa tecnologia automatizza il processo di animazione prevedendo transizioni senza soluzione di continuità tra i fotogrammi, rendendolo accessibile agli utenti senza competenze di codifica o risorse di calcolo attraverso una piattaforma online gratuita.
2.2. Caratteristiche chiave di AnimateDiff#
2.2.1. Supporto completo dei modelli: AnimateDiff è compatibile con varie versioni, tra cui AnimateDiff v1, v2, v3 per Stable Diffusion V1.5 e AnimateDiff sdxl per Stable Diffusion SDXL. Permette l'uso simultaneo di più modelli di movimento, facilitando la creazione di animazioni complesse e stratificate.
2.2.2. La dimensione del batch di contesto determina la lunghezza dell'animazione: AnimateDiff consente la creazione di animazioni di lunghezza infinita attraverso la regolazione della dimensione del batch di contesto. Questa funzione consente agli utenti di personalizzare la lunghezza e la transizione delle animazioni in base alle loro esigenze specifiche, fornendo un processo di animazione altamente adattabile.
2.2.3. Lunghezza del contesto per transizioni fluide: Lo scopo della lunghezza del contesto uniforme in AnimateDiff è garantire transizioni senza interruzioni tra i diversi segmenti di un'animazione. Regolando la lunghezza del contesto uniforme, gli utenti possono controllare la dinamica di transizione tra le scene: lunghezze maggiori per transizioni più fluide e continue, e lunghezze più brevi per cambiamenti più rapidi e pronunciati.
2.2.4. Dinamiche del movimento: In AnimateDiff v2, speciali LoRA di movimento sono disponibili per aggiungere movimenti cinematografici della telecamera alle animazioni. Questa funzione introduce un livello dinamico alle animazioni, migliorandone significativamente l'appeal visivo.
2.2.5. Funzioni di supporto avanzate: AnimateDiff è progettato per funzionare con una varietà di strumenti tra cui ControlNet, SparseCtrl e IPAdapter, offrendo significativi vantaggi agli utenti che mirano ad espandere le possibilità creative dei loro progetti.
3. Panoramica di ControlNet#
3.1. Introduzione a ControlNet#
ControlNet introduce un framework per aumentare i modelli di diffusione delle immagini con input condizionali, con l'obiettivo di perfezionare e guidare il processo di sintesi delle immagini. Raggiunge questo obiettivo duplicando i blocchi della rete neurale all'interno di un dato modello di diffusione in due set: uno rimane "bloccato" per preservare la funzionalità originale, mentre l'altro diventa "addestrabile", adattandosi alle condizioni specifiche fornite. Questa struttura duale consente agli sviluppatori di incorporare una varietà di input condizionali utilizzando modelli come OpenPose, Tile, IP-Adapter, Canny, Depth, LineArt, MLSD, Normal Map, Scribbles, Segmentation, Shuffle e T2I Adapter, influenzando direttamente l'output generato. Attraverso questo meccanismo, ControlNet offre agli sviluppatori uno strumento potente per controllare e manipolare il processo di generazione delle immagini, migliorando la flessibilità del modello di diffusione e la sua applicabilità a diverse attività creative.
Preprocessori e integrazione dei modelli
3.1.1. Configurazione del preprocessing: L'avvio con ControlNet prevede la selezione di un preprocessore adatto. Si consiglia di attivare l'opzione di anteprima per una comprensione visiva dell'impatto del preprocessing. Dopo il preprocessing, il flusso di lavoro passa all'utilizzo dell'immagine preprocessata per ulteriori fasi di elaborazione.
3.1.2. Corrispondenza dei modelli: Semplificando il processo di selezione del modello, ControlNet garantisce la compatibilità allineando i modelli con i loro corrispondenti preprocessori in base alle parole chiave condivise, facilitando un processo di integrazione senza soluzione di continuità.
3.2. Caratteristiche chiave di ControlNet#
Esplorazione approfondita dei modelli ControlNet
3.2.1. Suite OpenPose: Progettata per il rilevamento preciso delle pose umane, la suite OpenPose comprende modelli per il rilevamento di pose del corpo, espressioni facciali e movimenti delle mani con eccezionale accuratezza. Vari preprocessori OpenPose sono adattati a requisiti di rilevamento specifici, dall'analisi di base delle pose alla cattura dettagliata delle sfumature facciali e delle mani.
3.2.2. Modello Tile Resample: Migliorando la risoluzione e i dettagli delle immagini, il modello Tile Resample viene utilizzato in modo ottimale insieme a uno strumento di upscaling, mirando ad arricchire la qualità dell'immagine senza compromettere l'integrità visiva.
3.2.3. Modello IP-Adapter: Facilitando l'uso innovativo delle immagini come prompt, l'IP-Adapter integra elementi visivi dalle immagini di riferimento negli output generati, unendo le capacità di diffusione da testo a immagine per un contenuto visivo arricchito.
3.2.4. Rilevatore di bordi Canny: Rinomato per le sue capacità di rilevamento dei bordi, il modello Canny enfatizza l'essenza strutturale delle immagini, consentendo reinterpretazioni visive creative pur mantenendo le composizioni principali.
3.2.5. Modelli di percezione della profondità: Attraverso una varietà di preprocessori di profondità, ControlNet è abile nell'estrarre e applicare indizi di profondità dalle immagini, offrendo una prospettiva di profondità stratificata nelle immagini generate.
3.2.6. Modelli LineArt: Converti le immagini in disegni a linee artistiche con i preprocessori LineArt, rispondendo a diverse preferenze artistiche, dall'anime agli schizzi realistici, ControlNet si adatta a uno spettro di desideri stilistici.
3.2.7. Elaborazione degli scarabocchi: Con preprocessori come Scribble HED, Pidinet e xDoG, ControlNet trasforma le immagini in un'arte unica di scarabocchi, offrendo stili vari per il rilevamento dei bordi e la reinterpretazione artistica.
3.2.8. Tecniche di segmentazione: Le capacità di segmentazione di ControlNet classificano accuratamente gli elementi dell'immagine, consentendo una manipolazione precisa basata sulla categorizzazione degli oggetti, ideale per costruzioni di scene complesse.
3.2.9. Modello Shuffle: Introducendo un metodo per l'innovazione degli schemi di colore, il modello Shuffle randomizza le immagini di input per generare nuovi pattern di colore, alterando creativamente l'originale pur mantenendone l'essenza.
3.2.10. Innovazioni T2I Adapter: I modelli T2I Adapter, tra cui Color Grid e CLIP Vision Style, spingono ControlNet in nuovi domini creativi, mescolando e adattando colori e stili per produrre output visivamente accattivanti che rispettano lo schema di colori o gli attributi stilistici dell'originale.
3.2.11. MLSD (Mobile Line Segment Detection): Specializzato nel rilevamento di linee rette, MLSD è prezioso per progetti incentrati su progettazioni architettoniche e di interni, dando priorità alla chiarezza e alla precisione strutturale.
3.2.12. Elaborazione delle mappe normali: Utilizzando i dati di orientamento delle superfici, i preprocessori Normal Map replicano la struttura 3D delle immagini di riferimento, migliorando il realismo del contenuto generato attraverso un'analisi dettagliata delle superfici.
