
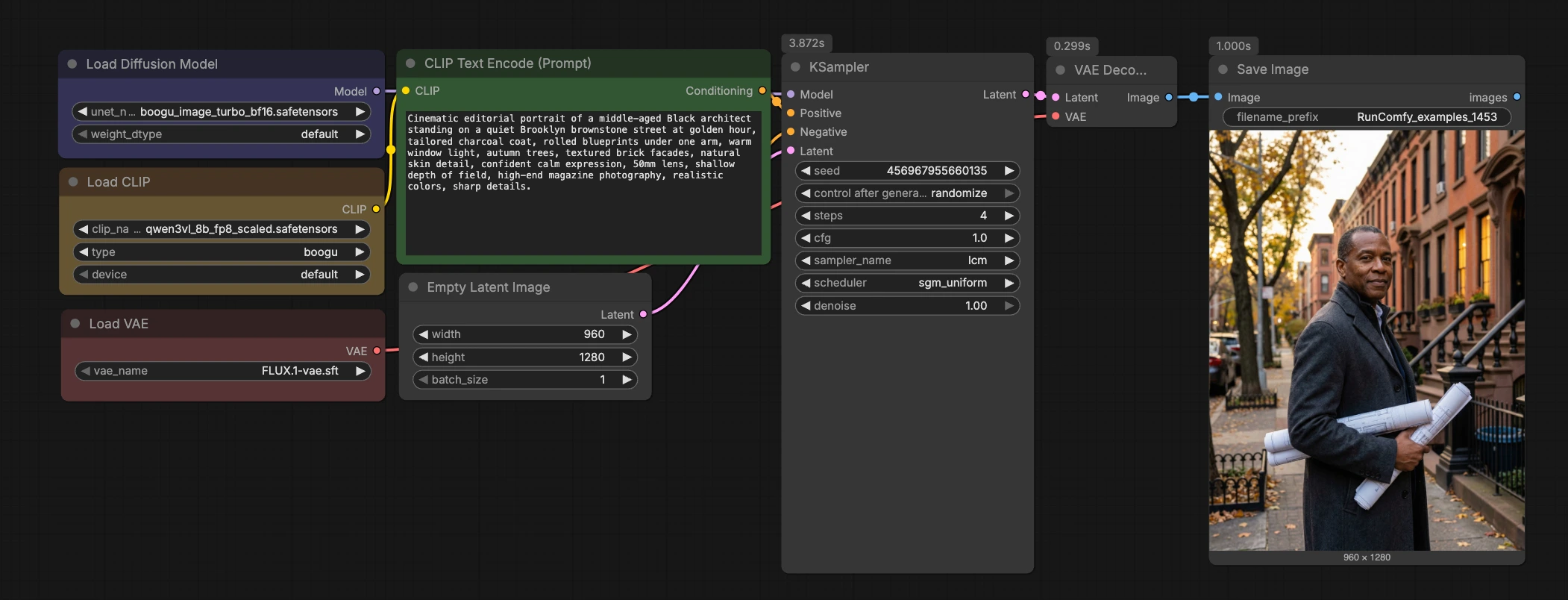






Boogu Turbo text-to-image ComfyUI workflow#
Questo workflow Boogu Turbo text-to-image ComfyUI è un percorso pulito e veloce dal prompt all'immagine usando il checkpoint Boogu-Image-0.1-Turbo con campionamento LCM a quattro passi. Abbina l'encoder di testo Qwen3-VL con il FLUX.1 VAE in modo da poter iterare rapidamente mantenendo il grafico minimale e facile da riutilizzare in diversi progetti.
Progettato per un'esplorazione visiva rapida, il workflow eccelle in ambienti cinematografici, sfondi in stile anime, paesaggi atmosferici, macchine di prodotto immaginative e scene architettoniche. Se desideri un workflow Boogu Turbo text-to-image ComfyUI leggero che sia pronto per RunComfy e semplice da ispezionare, questo modello è un ottimo punto di partenza.
Modelli chiave nel workflow Comfyui Boogu Turbo text-to-image ComfyUI#
- Boogu-Image-0.1-Turbo. La variante Turbo distillata è costruita per un text-to-image fotorealistico veloce con tipica inferenza in 3-4 passi e scala di guida vicino a 1.0. I pesi del modello ufficiale e le istruzioni sono disponibili su Hugging Face, con file ripacchettati pronti per ComfyUI forniti da Comfy-Org. Vedi Boogu/Boogu-Image-0.1-Turbo-fp8 e il pacchetto ComfyUI curato su Comfy-Org/Boogu-Image.
- Qwen3-VL 8B text encoder. Questo moderno backbone vision-language è utilizzato qui puramente come encoder di testo per produrre forti embedding di prompt per il modello di diffusione. Gli encoder impacchettati per ComfyUI sono ospitati su Comfy-Org/Qwen3-VL e il repository ufficiale è QwenLM/Qwen3-VL.
- FLUX.1 VAE. L'autoencoder di Black Forest Labs codifica e decodifica immagini tra spazio pixel e latente, aiutando a preservare la fedeltà di colore e contrasto. I pesi di riferimento e la documentazione sono su black-forest-labs/FLUX.1-dev.
Come usare il workflow Comfyui Boogu Turbo text-to-image ComfyUI#
A colpo d'occhio, il workflow codifica il tuo prompt, inizializza una tela latente, esegue un campionatore LCM rapido attraverso Boogu-Image-0.1-Turbo, decodifica con il FLUX.1 VAE e salva il risultato. Il grafico è intenzionalmente compatto in modo che tu possa inserirlo in altri progetti o estenderlo con LoRAs, ControlNets o catene di post-elaborazione.
Codifica del prompt con Qwen3-VL (CLIPLoader (#7) → CLIPTextEncode (#11))#
Questa fase carica un encoder Qwen3-VL e converte il tuo prompt di testo in vettori di condizionamento. Inserisci il tuo prompt in CLIPTextEncode (#11) usando linguaggio naturale; indizi fotografici dettagliati come lente, illuminazione, ora del giorno e texture funzionano bene. L'input negativo è intenzionalmente azzerato tramite ConditioningZeroOut (#9) per mantenere i risultati stabili con il regime di bassa guida di Turbo. Se preferisci negativi espliciti, sostituisci ConditioningZeroOut con un secondo CLIPTextEncode per fornire un prompt negativo. Una buona igiene del prompt qui riduce la necessità di CFG elevato o passaggi extra in seguito.
Configurazione latente e caricamento del modello (EmptyLatentImage (#8) + UNETLoader (#2))#
EmptyLatentImage (#8) crea la tela latente. L'aspetto predefinito 960×1280 in verticale è un punto di partenza bilanciato per persone, interni e scatti di prodotti alti; puoi impostare altre dimensioni per quadrati o wides. UNETLoader (#2) carica i pesi di diffusione Boogu Turbo dal pacchetto Comfy-Org, allineando il modello al tuo encoder e VAE scelti. Scambiare le varianti BF16 e FP8 è semplice se hai bisogno di bilanciare VRAM e throughput. Mantieni la scelta del modello coerente in tutto il tuo progetto per mantenere la continuità dello stile.
Campionamento LCM veloce (KSampler (#32) con campionatore lcm)#
Il KSampler è configurato per i modelli di coerenza latente per ottenere alta qualità in circa quattro passi. La distillazione LCM prende di mira valori di guida molto bassi, motivo per cui questo workflow Boogu Turbo text-to-image ComfyUI funziona stabilmente con CFG vicino a 1.0 pur preservando l'aderenza al prompt. Se vuoi un tocco di micro-dettaglio in più, aumenta modestamente i passaggi e fissa il seed per confronti A/B. Per cambiamenti di stile o composizione, rilancia il seed e perfeziona il prompt piuttosto che spingere i passaggi troppo in alto. La teoria di base sull'inferenza in pochi passi LCM è descritta nel documento originale Latent Consistency Models.
Decodifica e salvataggio (VAELoader (#5) → VAEDecode (#3) → SaveImage (#58))#
Il FLUX.1 VAE caricato in VAELoader (#5) decodifica i latenti in RGB in VAEDecode (#3). Abbinare la famiglia VAE al tuo backbone di diffusione generalmente produce colori e texture più fedeli, motivo per cui questo grafico viene fornito con il FLUX.1 VAE. SaveImage (#58) scrive i risultati su disco; cambia il prefisso di output per organizzare gli esperimenti per prompt, seed o rapporto d'aspetto. Se in seguito concatenai upscalers o post-fx, ramifica dall'output Image di VAEDecode per preservare una cronologia pulita.
Nodi chiave nel workflow Comfyui Boogu Turbo text-to-image ComfyUI#
CLIPTextEncode (#11)#
Questo nodo ospita il tuo prompt di testo principale e produce il condizionamento positivo utilizzato dal campionatore. Mantieni i prompt concisi e aggiungi indizi di scena come lunghezza focale della fotocamera, ora del giorno e aggettivi materiali. Se vuoi usare prompt negativi, crea un secondo CLIPTextEncode e collegalo all'input negativo del campionatore, rimuovendo ConditioningZeroOut (#9).
ConditioningZeroOut (#9)#
Questo disabilita il condizionamento negativo fornendo un vettore zero alla porta negativa del campionatore. Lasciarlo in posizione è una buona impostazione predefinita per la configurazione a bassa guida di Turbo. Rimuovilo solo quando hai specificamente bisogno di prompt negativi e puoi articolare chiaramente.
EmptyLatentImage (#8)#
Controlla le dimensioni dell'output e la dimensione del batch. Inizia a 960×1280 per ritratti o 1280×960 per ambienti più ampi; regola in base al soggetto e al budget di memoria. Latenti più grandi forniscono più tela per dettagli fini ma aumentano l'uso di VRAM e il tempo di decodifica.
UNETLoader (#2)#
Seleziona il checkpoint Boogu-Image-0.1-Turbo da usare per la generazione. Usa la variante BF16 per la massima fedeltà su GPU capaci o la variante FP8 per minore VRAM e caricamenti più veloci, entrambe disponibili nel pacchetto Comfy-Org. I file del modello e le loro cartelle previste sono documentati su Comfy-Org/Boogu-Image.
KSampler (#32)#
Esegue il processo di diffusione con il campionatore lcm per inferenze in pochi passi. Le leve chiave sono il seed, il numero di passi e CFG; Turbo è progettato per funzionare con guida molto bassa e pochi passi mantenendo la qualità, come riflesso nelle impostazioni ufficiali di Turbo sulla scheda del modello su Boogu/Boogu-Image-0.1-Turbo-fp8. Per esplorazioni controllate, fissa il seed e varia i passi o la formulazione del prompt un cambiamento alla volta.
VAELoader (#5) e VAEDecode (#3)#
Carica e applica il FLUX.1 VAE per la decodifica. Attenersi alla famiglia FLUX.1 mantiene i colori, il contrasto e il comportamento della texture coerenti con il setup di allenamento dell'UNet. Mescolare i VAE è possibile ma potrebbe spostare sottilmente la tonalità o la saturazione; testa prima di impegnarti in un nuovo look. Pesi di riferimento: black-forest-labs/FLUX.1-dev.
SaveImage (#58)#
Controlla la denominazione e la destinazione dell'output. Usa prefissi significativi come nome del progetto, tag dell'aspetto o seed per mantenere le esecuzioni organizzate. Quando espandi la pipeline, ramifica qui per aggiungere upscalers, grading del colore o captioners senza interrompere il salvataggio base.
Extra opzionali#
- Mantieni CFG vicino a 1.0 e passi intorno a quattro per iterazioni più veloci; passa a 6–8 passi solo quando hai bisogno di un po' più di texture o stabilità.
- Rilancia il seed per esplorare la composizione; fissa il seed per affinare stile e micro-dettaglio.
- Preferisci i pesi BF16 per la migliore qualità su GPU ad alta memoria; passa a FP8 per velocizzare il caricamento e ridurre la VRAM.
- Per la leggibilità del testo nell'immagine, prova una risoluzione leggermente più alta e includi indizi tipografici espliciti nel prompt.
- Salva spesso i preferiti intermedi; piccoli aggiustamenti del prompt in questo workflow Boogu Turbo text-to-image ComfyUI possono produrre scene significativamente diverse in pochi secondi.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine RunningHub per il riferimento del workflow, Boogu per il repository Boogu-Image e il modello Boogu-Image-0.1-Turbo, Comfy-Org per i pesi ComfyUI Boogu e ComfyUI per il tutorial Boogu per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- RunningHub/Workflow reference
- Docs / Note di rilascio: RunningHub post
- Boogu/Sito del progetto
- Docs / Note di rilascio: boogu.org
- Boogu/Boogu Image repository
- GitHub: boogu-project/Boogu-Image
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- Boogu/Boogu-Image-0.1-Turbo model
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- GitHub: boogu-project/Boogu-Image
- Comfy-Org/Boogu ComfyUI weights
- Hugging Face: Comfy-Org/Boogu-Image
- ComfyUI/Boogu tutorial
- Docs / Note di rilascio: ComfyUI tutorial
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.




