
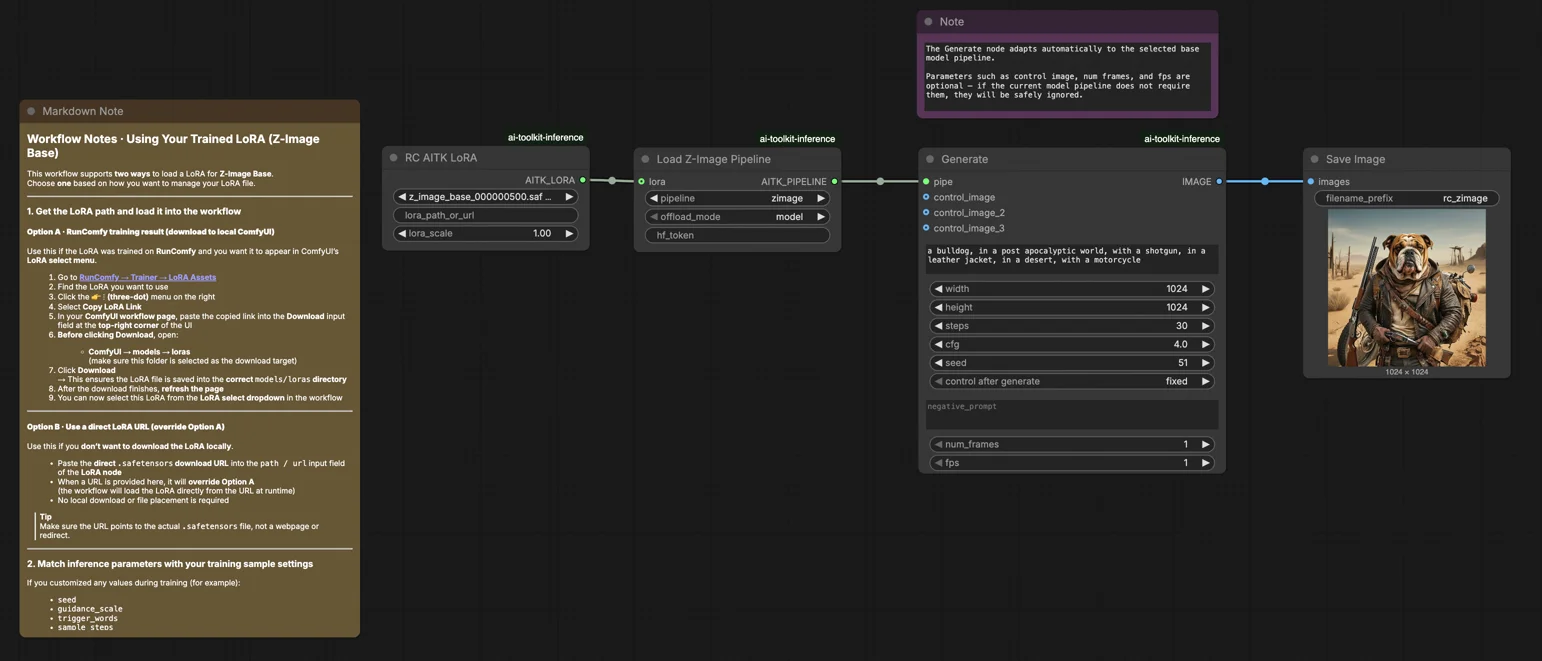
Inférence Z-Image Base LoRA ComfyUI : génération alignée sur l'entraînement avec AI Toolkit LoRAs#
Ce workflow RunComfy prêt pour la production vous permet d'exécuter des adaptateurs Z-Image LoRA entraînés avec l'AI Toolkit dans ComfyUI avec des résultats correspondant à l'entraînement. Construit autour de RC Z-Image (RCZimage)—un nœud personnalisé au niveau du pipeline open-source par RunComfy (source)—le workflow enveloppe le pipeline d'inférence Tongyi-MAI/Z-Image au lieu de s'appuyer sur un graphique d'échantillonneur générique. Votre adaptateur est injecté via lora_path et lora_scale à l'intérieur de ce pipeline, maintenant l'application de LoRA cohérente avec la manière dont l'AI Toolkit produit les aperçus d'entraînement.
Pourquoi l'inférence Z-Image Base LoRA ComfyUI semble souvent différente dans ComfyUI#
Les aperçus d'entraînement de l'AI Toolkit sont rendus par un pipeline d'inférence spécifique au modèle—la configuration du planificateur, le flux de conditionnement et l'injection de LoRA se produisent tous à l'intérieur de ce pipeline. Un graphique d'échantillonneur ComfyUI standard assemble ces éléments différemment, de sorte que même des invites, des graines et des comptes d'étapes identiques peuvent produire des sorties sensiblement différentes. L'écart n'est pas causé par un seul mauvais paramètre ; c'est un décalage au niveau du pipeline. RCZimage récupère le comportement aligné sur l'entraînement en enveloppant directement le pipeline Z-Image et en appliquant votre LoRA à l'intérieur. Référence d'implémentation : `src/pipelines/z_image.py`.
Comment utiliser le workflow d'inférence Z-Image Base LoRA ComfyUI#
Étape 1 : Obtenez le chemin LoRA et chargez-le dans le workflow (2 options)#
Option A — Résultat d'entraînement RunComfy → télécharger sur ComfyUI localement :
- Allez sur Trainer → LoRA Assets
- Trouvez le LoRA que vous souhaitez utiliser
- Cliquez sur le menu ⋮ (trois points) à droite → sélectionnez Copier le lien LoRA
- Dans la page de workflow ComfyUI, collez le lien copié dans le champ Download en haut à droite de l'interface
- Avant de cliquer sur Télécharger, assurez-vous que le dossier cible est défini sur ComfyUI → models → loras (ce dossier doit être sélectionné comme cible de téléchargement)
- Cliquez sur Télécharger — cela enregistre le fichier LoRA dans le répertoire
models/lorascorrect - Après la fin du téléchargement, rafraîchissez la page
- Le LoRA apparaît maintenant dans le menu déroulant de sélection LoRA dans le workflow — sélectionnez-le

Option B — URL LoRA directe (remplace l'Option A) :
- Collez l'URL de téléchargement directe
.safetensorsdans le champ d'entréepath / urldu nœud LoRA - Lorsqu'une URL est fournie ici, elle remplace l'Option A — le workflow charge le LoRA directement depuis l'URL à l'exécution
- Aucun téléchargement local ou placement de fichier n'est requis
Astuce : l'URL doit pointer vers le fichier .safetensors réel, pas une page web ou une redirection.

Étape 2 : Adaptez les paramètres d'inférence avec les paramètres de votre échantillon d'entraînement#
Réglez lora_scale sur le nœud LoRA — commencez à la même intensité que vous avez utilisée lors des aperçus d'entraînement, puis ajustez au besoin.
Les paramètres restants se trouvent sur le nœud Generate :
prompt— votre invite de texte ; incluez tous les mots déclencheurs que vous avez utilisés lors de l'entraînementnegative_prompt— laissez vide sauf si votre YAML d'entraînement incluait des négatifswidth/height— résolution de sortie ; correspondez à votre taille d'aperçu pour une comparaison directe (multiples de 32)sample_steps— nombre d'étapes d'inférence ; Z-Image base par défaut à 30 (utilisez le même compte de votre configuration d'aperçu)guidance_scale— intensité CFG ; par défaut 4.0 (reflétez d'abord la valeur de votre aperçu d'entraînement)seed— fixez une graine pour reproduire des sorties spécifiques ; changez-la pour explorer des variationsseed_mode— choisissezfixedourandomizehf_token— jeton Hugging Face ; requis uniquement si le modèle de base ou le dépôt LoRA est privé/protégé
Conseil d'alignement d'entraînement : si vous avez personnalisé des valeurs d'échantillonnage lors de l'entraînement, copiez ces valeurs exactes dans les champs correspondants. Si vous vous êtes entraîné sur RunComfy, ouvrez Trainer → LoRA Assets → Config pour voir le YAML résolu et copier les paramètres d'aperçu/d'échantillon dans le nœud.

Étape 3 : Exécutez l'inférence Z-Image Base LoRA ComfyUI#
Cliquez sur Queue/Run — le nœud SaveImage écrit automatiquement les résultats dans votre dossier de sortie ComfyUI.
Liste de contrôle rapide :
- ✅ LoRA est soit : téléchargé dans
ComfyUI/models/loras(Option A), soit chargé via une URL directe.safetensors(Option B) - ✅ Page rafraîchie après le téléchargement local (Option A uniquement)
- ✅ Les paramètres d'inférence correspondent à la configuration
sampled'entraînement (si personnalisée)
Si tout ce qui précède est correct, les résultats d'inférence ici devraient correspondre étroitement à vos aperçus d'entraînement.
Dépannage de l'inférence Z-Image Base LoRA ComfyUI#
La plupart des écarts “aperçu d'entraînement vs inférence ComfyUI” pour Z-Image Base (Tongyi-MAI/Z-Image) proviennent de différences au niveau du pipeline (comment le modèle est chargé, quels paramètres par défaut/planificateur sont utilisés, et où/comment le LoRA est injecté). Pour les Z-Image Base LoRAs entraînés avec l'AI Toolkit, la manière la plus fiable de revenir à un comportement aligné sur l'entraînement dans ComfyUI est de générer à travers RCZimage (le wrapper de pipeline RunComfy) et d'injecter le LoRA via lora_path / lora_scale à l'intérieur de ce pipeline.
(1) Lors de l'utilisation de Z-Image LoRA avec ComfyUI, le message "lora key not loaded" apparaît.#
Pourquoi cela se produit Cela signifie généralement que votre LoRA a été entraîné contre une disposition de module/clé différente de celle que votre chargeur Z-Image ComfyUI actuel attend. Avec Z-Image, le “même nom de modèle” peut encore impliquer des conventions de clé différentes (par exemple, original/style diffusers vs nommage spécifique à Comfy), et c'est suffisant pour déclencher “clé non chargée”.
Comment résoudre (recommandé)
- Exécutez l'inférence à travers RCZimage (le wrapper de pipeline du workflow) et chargez votre adaptateur via
lora_pathsur le chemin RCAITKLoRA / RCZimage, au lieu de l'injecter à travers un chargeur Z-Image LoRA générique séparé. - Gardez le workflow format-consistent : Z-Image Base LoRA entraîné avec AI Toolkit → inférer avec le pipeline RCZimage aligné sur l'AI Toolkit, pour ne pas dépendre des remappages/converteurs de clés côté ComfyUI.
(2) Des erreurs sont survenues lors de la phase VAE lors de l'utilisation du chargeur ZIMAGE LORA (modèle uniquement).#
Pourquoi cela se produit Certains utilisateurs signalent que l'ajout du chargeur ZIMAGE LoRA (modèle uniquement) peut causer des ralentissements majeurs et des échecs ultérieurs à l'étape finale de décodage VAE, même lorsque le workflow Z-Image par défaut fonctionne bien sans le chargeur.
Comment résoudre (confirmé par l'utilisateur)
- Retirez le chargeur ZIMAGE LORA (modèle uniquement) et réexécutez le chemin de workflow Z-Image par défaut.
- Dans ce workflow RunComfy, le “baseline sûr” équivalent est : utilisez RCZimage +
lora_path/lora_scalepour que l'application LoRA reste à l'intérieur du pipeline, évitant le chemin problématique “chargeur LoRA modèle uniquement”.
(3) Le format Comfy de Z-Image ne correspond pas au code original#
Pourquoi cela se produit Z-Image dans ComfyUI peut impliquer un format spécifique à Comfy (y compris des différences de nommage de clés par rapport aux conventions “originales”). Si votre LoRA a été entraîné avec l'AI Toolkit sur une convention de nommage/disposition, et que vous essayez de l'appliquer dans ComfyUI en en attendant une autre, vous verrez une application partielle/échouée et un comportement “ça fonctionne mais ça ne ressemble pas à ce qu'il faut”.
Comment résoudre (recommandé)
- Ne mélangez pas les formats lorsque vous essayez de correspondre aux aperçus d'entraînement. Utilisez RCZimage pour que l'inférence exécute le pipeline Z-Image de la même “famille” que les aperçus AI Toolkit utilisent, et injectez le LoRA à l'intérieur via
lora_path/lora_scale. - Si vous devez utiliser une pile Z-Image au format Comfy, assurez-vous que votre LoRA est dans le même format attendu par cette pile (sinon les clés ne s'aligneront pas).
(4) Z-Image oom en utilisant lora#
Pourquoi cela se produit Z-Image + LoRA peut pousser la VRAM au-delà de ses limites selon la précision/quantification, la résolution et le chemin de chargeur. Certains rapports mentionnent OOM sur des configurations VRAM de 12 Go lors de la combinaison de LoRA avec des modes de précision inférieure.
Comment résoudre (baseline sûr)
- Validez d'abord votre baseline : exécutez Z-Image Base sans LoRA à votre résolution cible.
- Ensuite, ajoutez le LoRA via RCZimage (
lora_path/lora_scale) et gardez les comparaisons contrôlées (mêmewidth/height,sample_steps,guidance_scale,seed). - Si vous rencontrez toujours OOM, réduisez d'abord la résolution (Z-Image est sensible au nombre de pixels), puis envisagez de réduire
sample_steps, et réintroduisez seulement des paramètres plus élevés après confirmation de la stabilité. Dans RunComfy, vous pouvez également passer à une machine plus grande.
Exécutez maintenant l'inférence Z-Image Base LoRA ComfyUI#
Ouvrez le workflow RunComfy Z-Image Base LoRA ComfyUI Inference, définissez votre lora_path, et laissez RCZimage garder la sortie ComfyUI alignée avec vos aperçus d'entraînement de l'AI Toolkit.