
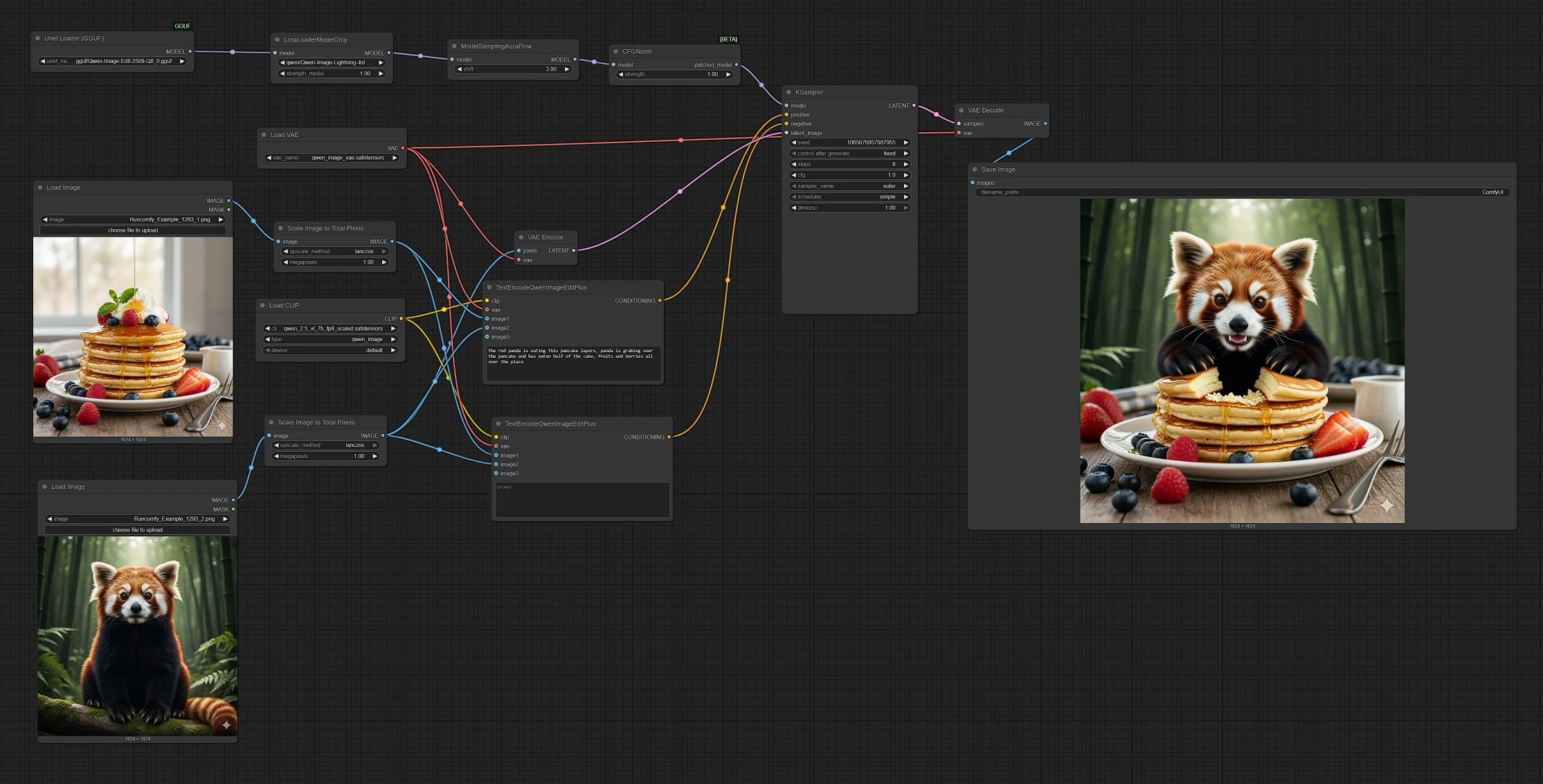






Qwen Image Edit 2509 : édition multi-images, pilotée par des invites et fusion pour ComfyUI#
Qwen Image Edit 2509 est un workflow d'édition multi-images pour ComfyUI qui fusionne 2 à 3 images d'entrée sous une seule invite pour créer des éditions précises et des fusions harmonieuses. Il est conçu pour les créateurs qui souhaitent composer des objets, restyler des scènes, remplacer des éléments ou fusionner des références tout en gardant un contrôle intuitif et prévisible.
Ce graphe ComfyUI associe le modèle d'image Qwen avec un encodeur de texte conscient de l'édition afin que vous puissiez orienter les résultats avec un langage naturel et une ou plusieurs références visuelles. Prêt à l'emploi, Qwen Image Edit 2509 gère le transfert de style, l'insertion d'objets, et les remixes de scènes, produisant des résultats cohérents même lorsque les sources varient en apparence ou en qualité.
Modèles clés dans le workflow Comfyui Qwen Image Edit 2509#
- Qwen Image Edit 2509 (Modèle de Diffusion & GGUF, Q8_0). Le point de contrôle principal d'édition d'image, chargé sous forme quantifiée pour réduire la VRAM tout en préservant le comportement d'édition. Il fournit l'épine dorsale de diffusion qui interprète le texte et les images de référence lors de l'échantillonnage.
- Qwen Image VAE. Un VAE dédié pour Qwen Image qui encode la toile de base en espace latent et décode les résultats finaux en pixels. Source des actifs : Comfy-Org/Qwen-Image_ComfyUI.
- Encodeur de texte Qwen 2.5 VL 7B (FP8 échelonné). Un encodeur de texte vision-langage emballé pour ComfyUI qui transforme votre invite et les images de référence en conditions d'édition. Source des actifs : Comfy-Org/Qwen-Image_ComfyUI.
- Qwen-Image-Lightning-4steps-V1.0 LoRA. Un LoRA optionnel qui incline le modèle vers des mises à jour rapides et percutantes, utile pour des itérations rapides ou des comptes d'étapes faibles. Page du modèle : lightx2v/Qwen-Image-Lightning.
Comment utiliser le workflow Comfyui Qwen Image Edit 2509#
Ce workflow suit un chemin clair des entrées à la sortie : vous chargez 2 à 3 images, écrivez une invite, le graphe encode à la fois le texte et les références, un échantillonnage s'exécute sur une base latente, et le résultat est décodé et enregistré.
Étape 1 — Charger et dimensionner vos sources
- Utilisez
LoadImage(#103) pour l'Image 1 etLoadImage(#109) pour l'Image 2. L'Image 2 sert de toile de fond qui recevra les éditions. - Chaque image passe par
ImageScaleToTotalPixels(#93 et #108) afin que les deux références partagent un budget de pixels cohérent. Cela stabilise la composition et le transfert de style. - Si vous voulez une troisième référence, branchez une autre
LoadImagedans l'entréeimage3sur les nœuds d'encodage. Qwen Image Edit 2509 accepte jusqu'à trois images pour un guidage plus riche.
Étape 2 — Écrire l'invite et définir l'intention
- L'encodeur positif
TextEncodeQwenImageEditPlus(#104) combine votre invite texte avec l'Image 1 et l'Image 2 pour décrire le résultat souhaité. Utilisez un langage naturel pour demander des fusions, des remplacements ou des indices de style. - L'encodeur négatif
TextEncodeQwenImageEditPlus(#106) vous permet de vous éloigner des détails indésirables. Laissez-le vide pour rester neutre ou ajoutez des phrases qui suppriment les artefacts ou les styles que vous ne voulez pas. - Les deux encodeurs utilisent l'encodeur de texte Qwen et le VAE, de sorte que le modèle "voit" vos références comme faisant partie de l'instruction.
Étape 3 — Préparer le modèle
UnetLoaderGGUF(#102) charge l'épine dorsale Qwen Image Edit 2509 au format GGUF pour une inférence efficace.LoraLoaderModelOnly(#89) applique le Qwen-Image-Lightning LoRA. Augmentez son influence pour des éditions plus percutantes ou réduisez-la pour des mises à jour plus conservatrices.- Le modèle est ensuite prêt pour l'échantillonnage avec une configuration ajustée pour la stabilité de l'édition.
Étape 4 — Génération guidée
- La toile de fond (Image 2) est encodée par
VAEEncode(#88) et fournie àKSampler(#3) comme point de départ latent. Cela permet un passage de l'image à l'image plutôt qu'un simple texte à l'image. KSampler(#3) fusionne les conditions positives et négatives avec la toile latente pour produire le résultat édité. Verrouillez la graine pour la reproductibilité ou variez-la pour explorer des alternatives.- Les choix de guidage et d'échantillonnage équilibrent la fidélité à vos sources avec l'adhésion à l'invite, donnant à Qwen Image Edit 2509 son mélange de précision et de flexibilité.
Étape 5 — Décoder et enregistrer
VAEDecode(#8) convertit le latent final en une image, etSaveImage(#60) l'enregistre dans votre dossier de sortie. Les noms de fichiers reflètent l'exécution afin que vous puissiez comparer facilement les versions.
Nœuds clés dans le workflow Comfyui Qwen Image Edit 2509#
TextEncodeQwenImageEditPlus (#104)#
Ce nœud crée la condition d'édition positive en combinant votre invite avec jusqu'à trois images de référence via l'encodeur Qwen. Utilisez-le pour spécifier ce qui doit apparaître, quel style adopter, et comment les références doivent influencer fortement le résultat. Commencez par un objectif clair en une phrase, puis ajoutez des descripteurs de style ou des indices de caméra au besoin. Les actifs pour l'encodeur sont emballés dans Comfy-Org/Qwen-Image_ComfyUI.
TextEncodeQwenImageEditPlus (#106)#
Ce nœud forme la condition négative pour prévenir les traits indésirables. Ajoutez des phrases courtes qui bloquent les artefacts, le lissage excessif ou les styles mal assortis. Gardez-le minimal pour éviter de lutter contre l'intention positive. Il utilise le même encodeur Qwen et la pile VAE que le chemin positif.
UnetLoaderGGUF (#102)#
Charge le point de contrôle Qwen Image Edit 2509 au format GGUF pour une inférence VRAM-amicale. Une quantification plus élevée économise de la mémoire mais peut légèrement affecter les détails fins ; si vous avez de la marge, essayez une quantification moins agressive pour maximiser la fidélité. Référence d'implémentation : city96/ComfyUI-GGUF.
LoraLoaderModelOnly (#89)#
Applique le Qwen-Image-Lightning LoRA sur le modèle de base pour accélérer la convergence et renforcer les éditions. Augmentez strength_model pour accentuer l'effet de ce LoRA ou abaissez-le pour un guidage subtil. Page du modèle : lightx2v/Qwen-Image-Lightning. Référence du nœud principal : comfyanonymous/ComfyUI.
ImageScaleToTotalPixels (#93, #108)#
Redimensionne chaque entrée à un nombre total de pixels cohérent en utilisant un échantillonnage de haute qualité. Augmenter la cible en mégapixels donne des résultats plus nets au détriment du temps et de la mémoire ; la réduire accélère l'itération. Gardez les deux références à des échelles similaires pour aider Qwen Image Edit 2509 à fusionner les éléments proprement. Référence du nœud principal : comfyanonymous/ComfyUI.
KSampler (#3)#
Exécute les étapes de diffusion qui transforment la toile latente selon vos conditions. Ajustez les étapes et l'échantillonneur pour équilibrer la vitesse et la fidélité, et variez la graine pour explorer plusieurs compositions à partir de la même configuration. Pour des éditions serrées qui préservent la structure de l'Image 2, gardez le nombre d'étapes modéré et fiez-vous à l'invite et aux références pour le contrôle. Référence du nœud principal : comfyanonymous/ComfyUI.
Extras optionnels#
- Traitez l'Image 2 comme la toile et l'Image 1 comme le donneur ; décrivez dans l'invite quels éléments doivent être transférés et lesquels doivent rester.
- Utilisez des négatifs concis pour limiter les halos, la dérive de texture ou la sur-stylisation ; de longues listes négatives peuvent entrer en conflit avec votre objectif.
- Si les résultats semblent trop conservateurs, augmentez légèrement la force du LoRA ou les étapes d'échantillonnage ; s'ils s'éloignent trop de la base, réduisez-les.
- Augmentez la cible en mégapixels lors de la finalisation, puis réutilisez la même graine pour agrandir exactement la composition que vous avez aimée.
- Gardez les invites concrètes : sujet, action, cadre et style. Qwen Image Edit 2509 répond le mieux à une intention claire avec quelques descripteurs forts.
Remerciements#
Ce workflow met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions vivement RobbaW pour le Qwen Image Edit 2509 Workflow pour leurs contributions et leur maintenance. Pour des détails autoritatifs, veuillez vous référer à la documentation et aux référentiels originaux liés ci-dessous.
Ressources#
- RobbaW/Qwen Image Edit 2509 Workflow
- Hugging Face : QuantStack/Qwen-Image-Edit-2509-GGUF
- Docs / Notes de version : Qwen Image Edit 2509 Workflow @RobbaW from Reddit r/comfyui
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences respectives et conditions fournies par leurs auteurs et mainteneurs.

