
LatentSync est un cadre de synchronisation labiale de bout en bout à la pointe de la technologie qui exploite la puissance des modèles de diffusion latente conditionnés par l'audio pour une génération réaliste de synchronisation labiale. Ce qui distingue LatentSync, c'est sa capacité à modéliser directement les corrélations complexes entre les composants audio et visuels sans s'appuyer sur une quelconque représentation intermédiaire du mouvement, révolutionnant l'approche de la synthèse de synchronisation labiale.
Au cœur du pipeline de LatentSync se trouve l'intégration de la Stable Diffusion, un modèle génératif puissant réputé pour sa capacité exceptionnelle à capturer et générer des images de haute qualité. En exploitant les capacités de la Stable Diffusion, LatentSync peut apprendre et reproduire efficacement les dynamiques complexes entre l'audio de la parole et les mouvements labiaux correspondants, aboutissant à des animations de synchronisation labiale très précises et convaincantes.
L'un des principaux défis des méthodes de synchronisation labiale basées sur la diffusion est de maintenir la cohérence temporelle entre les images générées, ce qui est crucial pour des résultats réalistes. LatentSync relève ce défi de front avec son module révolutionnaire d'Alignement de REPréSentation Temporelle (TREPA), spécialement conçu pour améliorer la cohérence temporelle des animations de synchronisation labiale. TREPA emploie des techniques avancées pour extraire des représentations temporelles des images générées en utilisant des modèles vidéo auto-supervisés à grande échelle. En alignant ces représentations avec les images de vérité terrain, le cadre de LatentSync assure un haut degré de cohérence temporelle, aboutissant à des animations de synchronisation labiale remarquablement fluides et convaincantes qui correspondent étroitement à l'entrée audio.
1.1 Comment Utiliser le Workflow LatentSync ?#
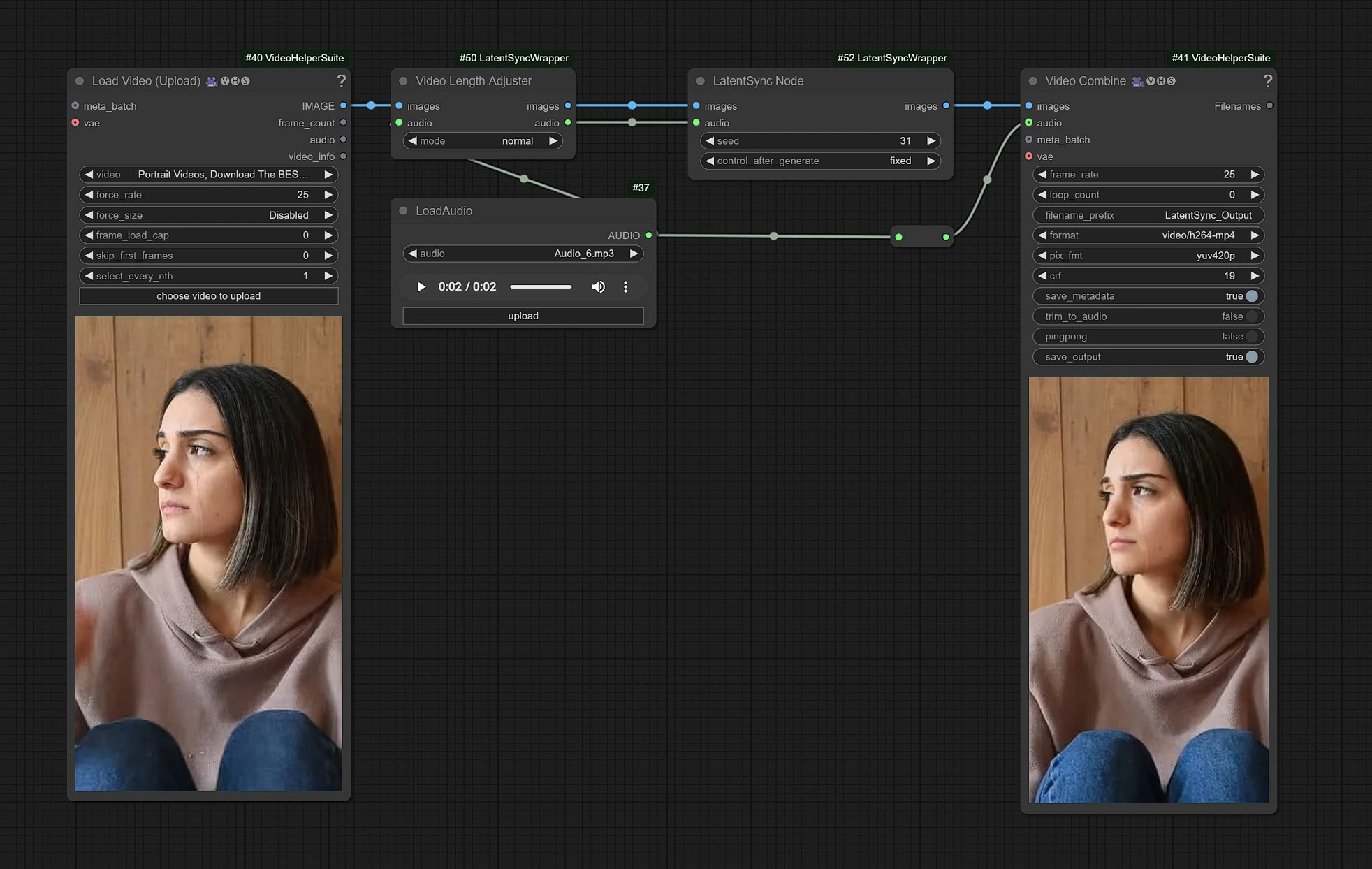
Voici le workflow LatentSync, les nœuds de gauche sont les entrées pour télécharger la vidéo, le milieu est le traitement des nœuds LatentSync, et à droite se trouve le nœud de sortie.
- Téléchargez votre Vidéo dans les nœuds d'entrée.
- Téléchargez votre entrée Audio des dialogues.
- Cliquez sur Rendre !!!
1.2 Entrée Vidéo#
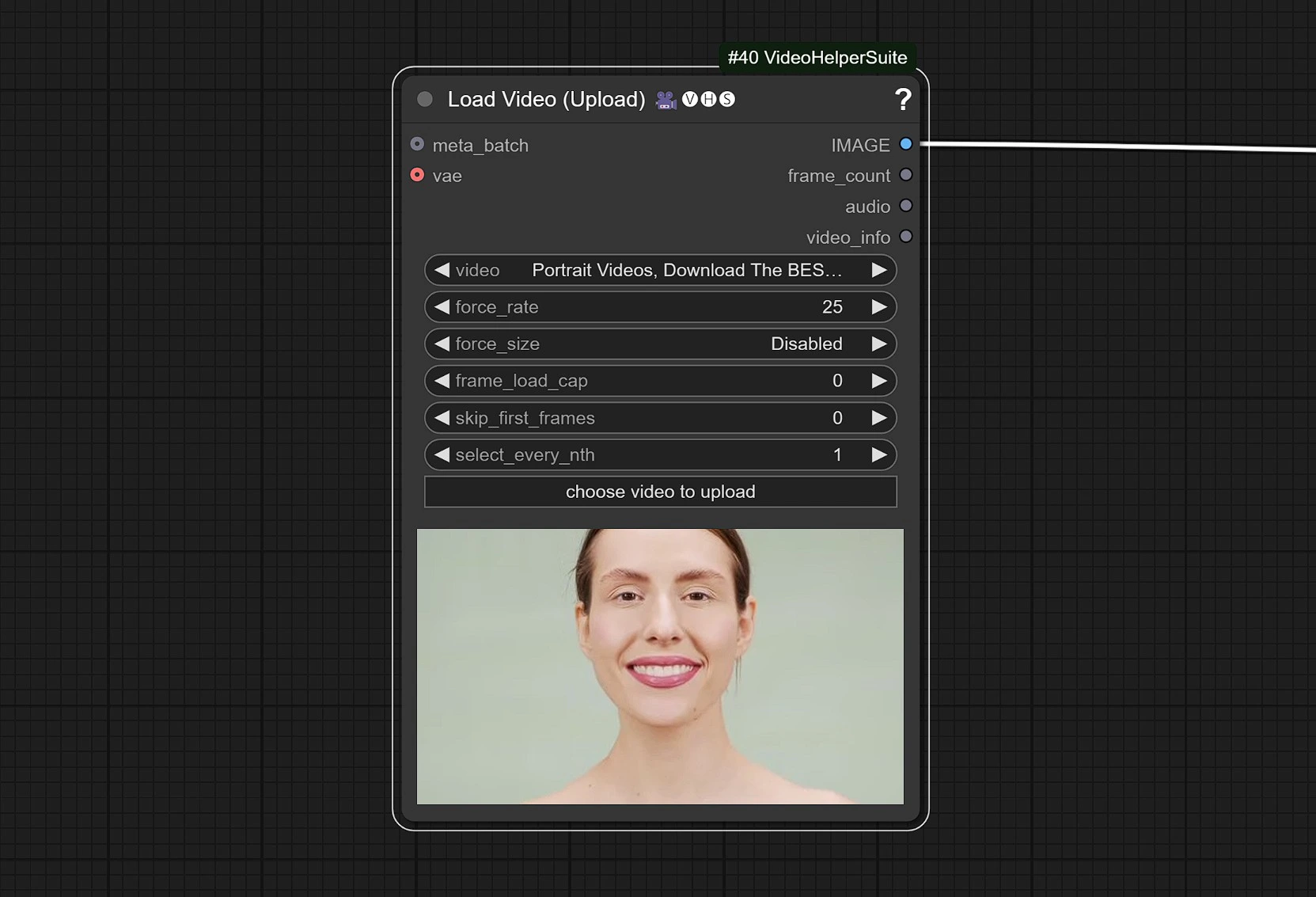
- Cliquez et Téléchargez votre Vidéo de Référence qui contient un visage.
La vidéo est ajustée à 25 FPS pour synchroniser correctement avec le modèle Audio
1.3 Entrée Audio#
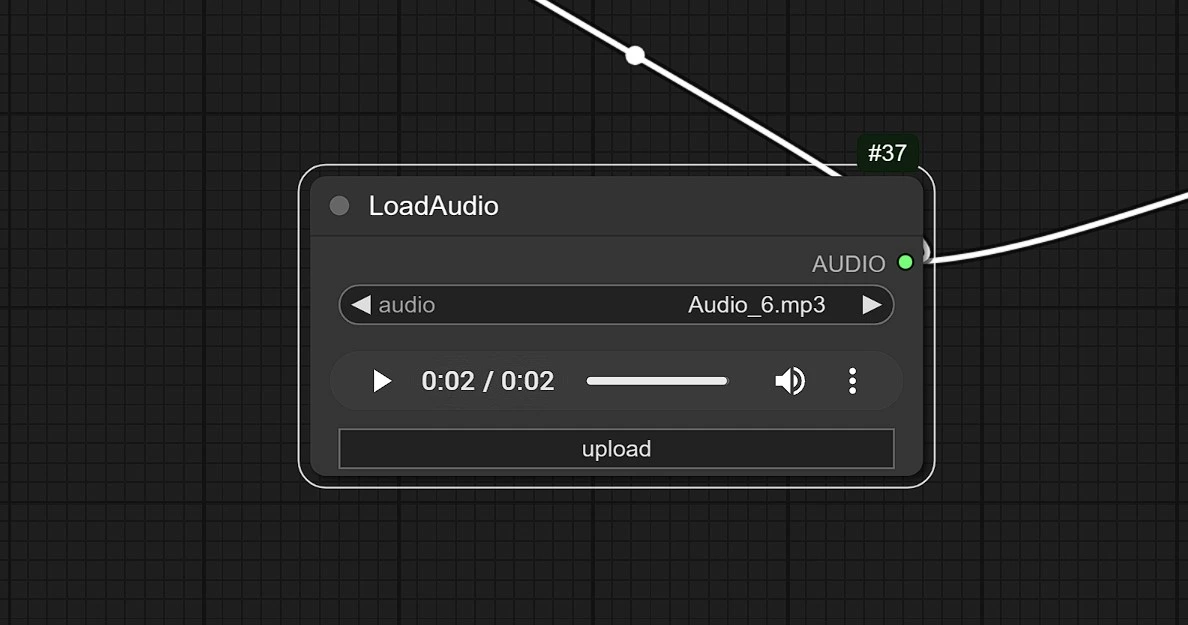
- Cliquez et Téléchargez votre audio ici.
LatentSync établit une nouvelle référence pour la synchronisation labiale avec son approche innovante de la génération audio-visuelle. En combinant précision, cohérence temporelle et la puissance de la Stable Diffusion, LatentSync transforme la manière dont nous créons du contenu synchronisé. Redéfinissez ce qui est possible en synchronisation labiale avec LatentSync.
