
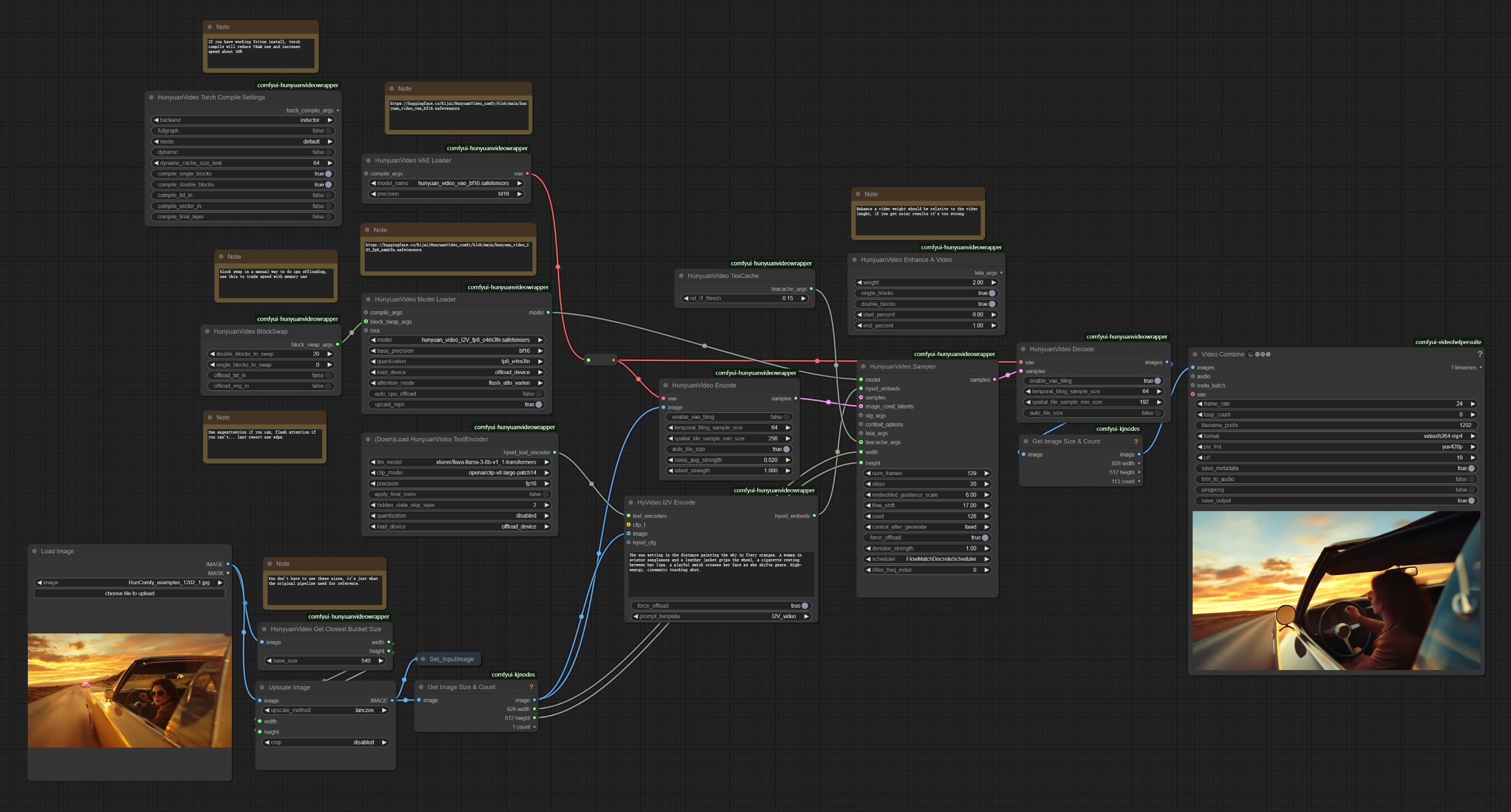
Description du Flux de Travail ComfyUI Hunyuan Image-to-Video#
1. Qu'est-ce que le Flux de Travail Hunyuan Image-to-Video ?#
Le flux de travail Hunyuan Image-to-Video est un pipeline puissant conçu pour transformer des images fixes en vidéos de haute qualité avec un mouvement naturel. Développée par Tencent, cette technologie de pointe permet aux utilisateurs de créer des animations cinématiques avec une lecture fluide à 24fps à des résolutions allant jusqu'à 720p. En tirant parti de la concaténation latente d'images et d'un modèle de langage multimodal, Hunyuan Image-to-Video interprète le contenu des images et applique des motifs de mouvement cohérents basés sur des invites textuelles.
2. Avantages de Hunyuan Image-to-Video :#
- Sortie Haute Résolution - Génère des vidéos jusqu'à 720p à 24fps
- Génération de Mouvement Naturel - Crée des animations fluides et réalistes à partir d'images statiques
- Animation Guidée par le Texte - Utilise des invites textuelles pour guider le mouvement et les effets visuels
- Qualité Cinématographique - Produit des vidéos de qualité professionnelle avec une haute fidélité
- Effets Personnalisables - Prend en charge les effets formés par LoRA comme la pousse des cheveux, les expressions faciales et les ajustements de style
- Utilisation Optimisée de la Mémoire - Utilise des poids FP8 pour une meilleure gestion des ressources
3. Comment Utiliser le Flux de Travail Hunyuan Image-to-Video#
3.1 Méthodes de Génération avec Hunyuan Image-to-Video#
Exemple de Flux de Travail :#
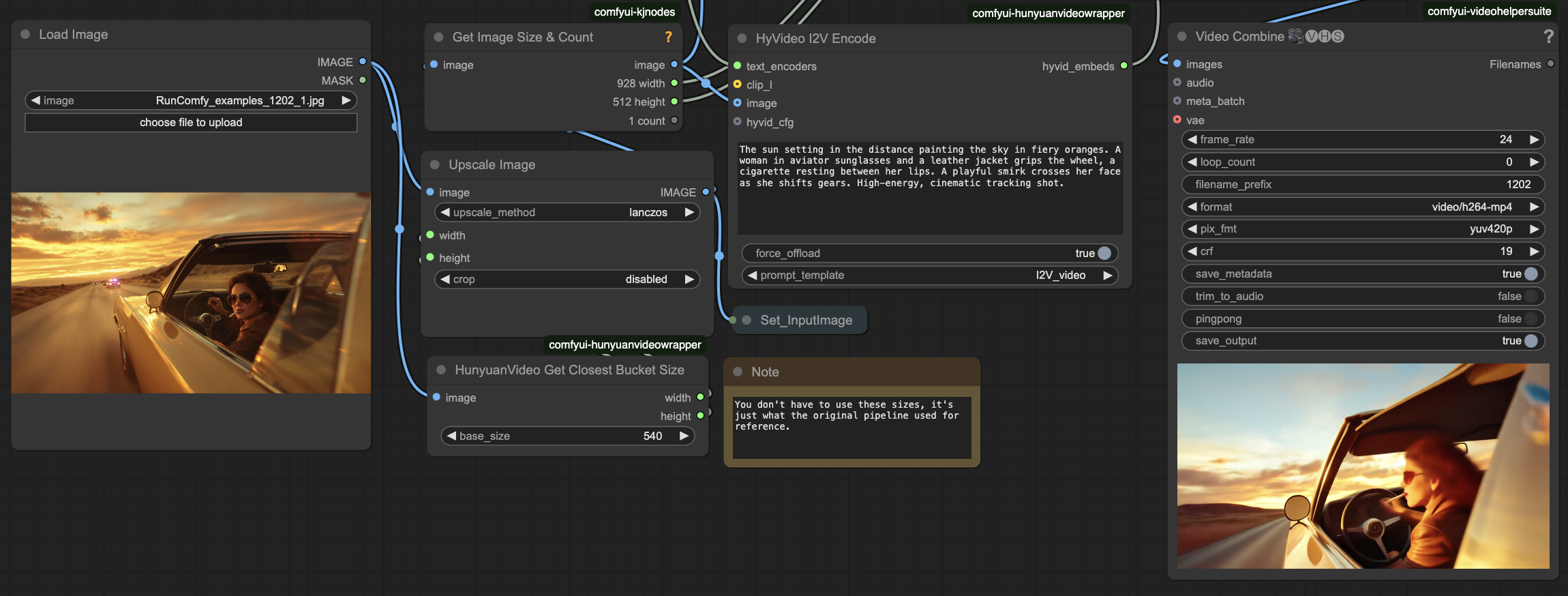
- Préparer les Entrées
- Dans Charger Image : Téléchargez votre image source
- Entrer la Description du Mouvement
- Dans HyVideo I2V Encode : Entrez une invite textuelle descriptive pour le mouvement souhaité
- Affinement (Optionnel)
- Dans HunyuanVideo Sampler : Ajustez
framespour contrôler la longueur de la vidéo (par défaut : 129 frames ≈ 5 secondes) - Dans HunyuanVideo TeaCache : Modifiez
cache_factorpour une utilisation optimisée de la mémoire - Dans HunyuanVideo Enhance A Video : Activez pour une cohérence temporelle et une réduction du scintillement
- Dans HunyuanVideo Sampler : Ajustez
- Sortie
- Dans Combiner Vidéo : Vérifiez l'aperçu et trouvez le résultat enregistré dans ComfyUI > Dossier de sortie
3.2 Référence des Paramètres pour Hunyuan Image-to-Video#
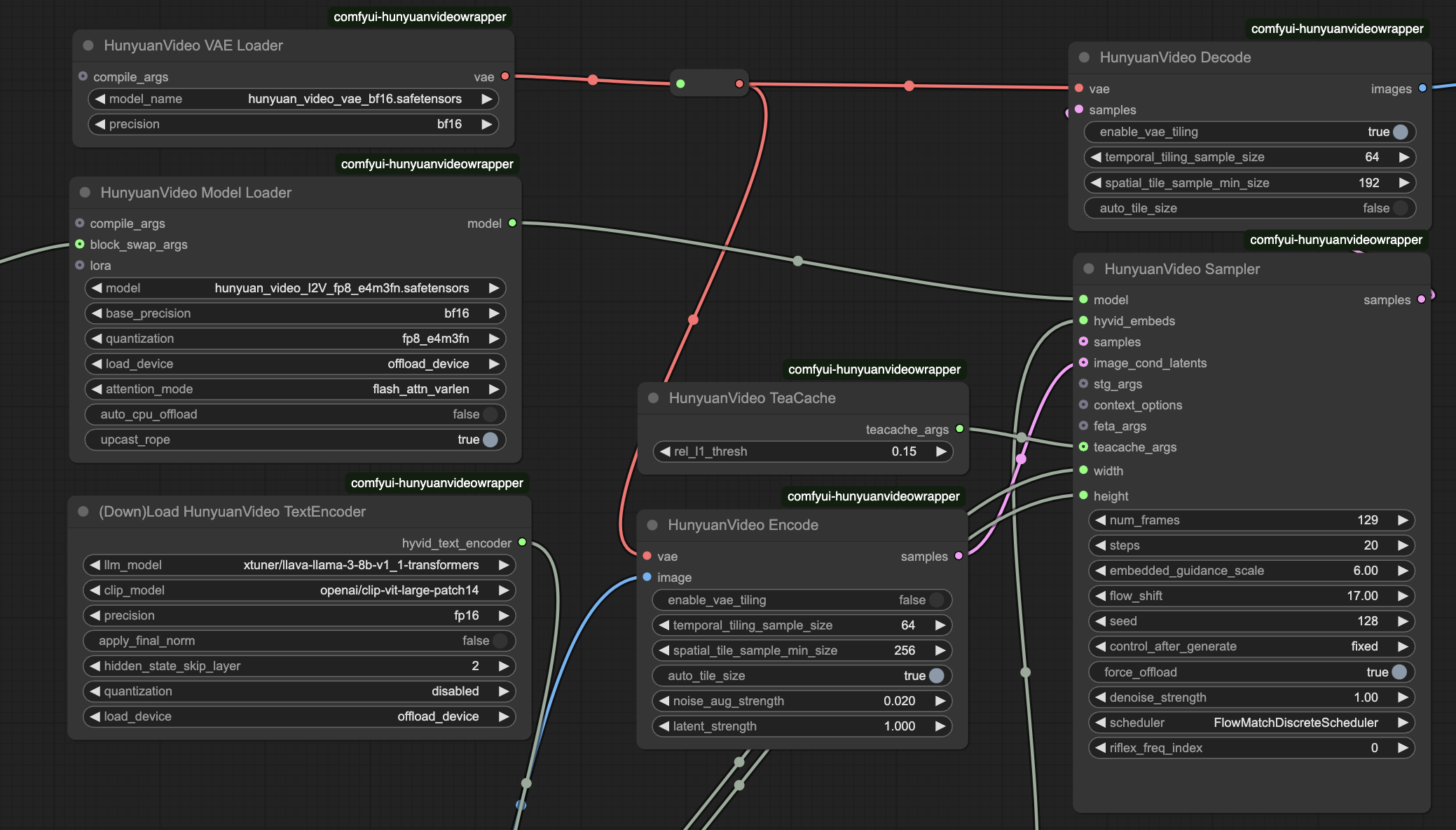
- Chargeur de Modèle HunyuanVideo
model_name: hunyuan_video_I2V_fp8_e4m3fn.safetensors - Modèle principal pour la conversion image-à-vidéoweight_precision: bf16 - Définit le niveau de précision pour les poids du modèlescale_weights: fp8_e4m3fn - Optimise l'utilisation de la mémoireattention_implementation: flash_attn_varlen - Contrôle l'efficacité du traitement de l'attention
- Échantillonneur HunyuanVideo
frames: 129 - Nombre de frames (5.4 secondes à 24fps)steps: 20 - Étapes d'échantillonnage (des valeurs plus élevées améliorent la qualité)cfg: 6 - Contrôle la force d'adhérence aux invitesseed: varies - Assure la cohérence de la génération
- HyVideo I2V Encode
prompt: [text field] - Invite descriptive pour le mouvement et le styleadd_prepend: true - Active le formatage automatique du texte
3.3 Optimisation Avancée avec Hunyuan Image-to-Video#
- Optimisation de la Mémoire
- HunyuanVideo BlockSwap : Déchargement CPU pour l'efficacité de la VRAM
- HunyuanVideo TeaCache : Contrôle le comportement du cache pour équilibrer mémoire vs vitesse
- scale_weights : Poids FP8 (
e4m3fn format) pour la réduction de la mémoire
- Optimisation de la Vitesse
- Paramètres de Compilation Torch HunyuanVideo : Active la compilation Torch pour un traitement plus rapide
- attention_implementation : Sélectionne les mécanismes d'attention efficaces pour un gain de performance
- offload_device : Configure la gestion de la mémoire GPU/CPU
Plus d'Informations#
Pour plus de détails sur le flux de travail Hunyuan Image-to-Video, visitez le dépôt HunyuanVideo-I2V de Tencent.
Remerciements#
Ce flux de travail est propulsé par Hunyuan Image-to-Video, développé par Tencent. L'intégration ComfyUI inclut des nœuds d'enveloppe créés par Kijai, permettant des fonctionnalités avancées telles que le fenêtrage contextuel et le support d'intégration directe d'images. Tout le crédit revient aux créateurs originaux pour leurs contributions au flux de travail Hunyuan Image-to-Video !
