
Character AI Ovi : image en vidéo avec discours synchronisé dans ComfyUI#
Character AI Ovi est un workflow de génération audiovisuelle qui transforme une seule image en un personnage parlant et mouvant avec un son coordonné. Basé sur la famille de modèles Wan et intégré via le WanVideoWrapper, il génère vidéo et audio en une seule passe, offrant une animation expressive, une synchronisation labiale intelligible et une ambiance contextuelle. Si vous créez des histoires courtes, des hôtes virtuels ou des clips sociaux cinématographiques, Character AI Ovi vous permet de passer de l'art statique à une performance complète en quelques minutes.
Ce workflow ComfyUI accepte une image plus une invite textuelle contenant un balisage léger pour le discours et la conception sonore. Il compose les images et les formes d'onde ensemble pour que la bouche, le rythme et l'audio de la scène semblent naturellement alignés. Character AI Ovi est conçu pour les créateurs qui souhaitent des résultats soignés sans assembler des outils TTS et vidéo séparés.
Modèles clés dans le workflow Comfyui Character AI Ovi#
- Ovi : Twin Backbone Cross-Modal Fusion for Audio-Video Generation. Le modèle central qui produit conjointement vidéo et audio à partir d'invites texte ou texte+image. character-ai/Ovi
- Wan 2.2 vidéo backbone et VAE. Le workflow utilise le VAE vidéo haute compression de Wan pour une génération efficace en 720p, 24 fps tout en préservant les détails et la cohérence temporelle. Wan-AI/Wan2.2-TI2V-5B-Diffusers • Wan-Video/Wan2.2
- Google UMT5-XXL encodeur de texte. Encode l'invite, y compris les balises de discours, en riches embeddings multilingues qui animent les deux branches. google/umt5-xxl
- MMAudio VAE avec BigVGAN vocoder. Décode les latents audio du modèle en discours et effets de haute qualité avec un timbre naturel. hkchengrex/MMAudio • nvidia/bigvgan_v2_44khz_128band_512x
- Poids Ovi prêts pour ComfyUI par Kijai. Points de contrôle sélectionnés pour la branche vidéo, la branche audio et le VAE en variantes scalées bf16 et fp8. Kijai/WanVideo_comfy/Ovi • Kijai/WanVideo_comfy_fp8_scaled/TI2V/Ovi
- Nœuds WanVideoWrapper pour ComfyUI. Wrapper qui expose les fonctionnalités Wan et Ovi en tant que nœuds composables. kijai/ComfyUI-WanVideoWrapper
Comment utiliser le workflow Comfyui Character AI Ovi#
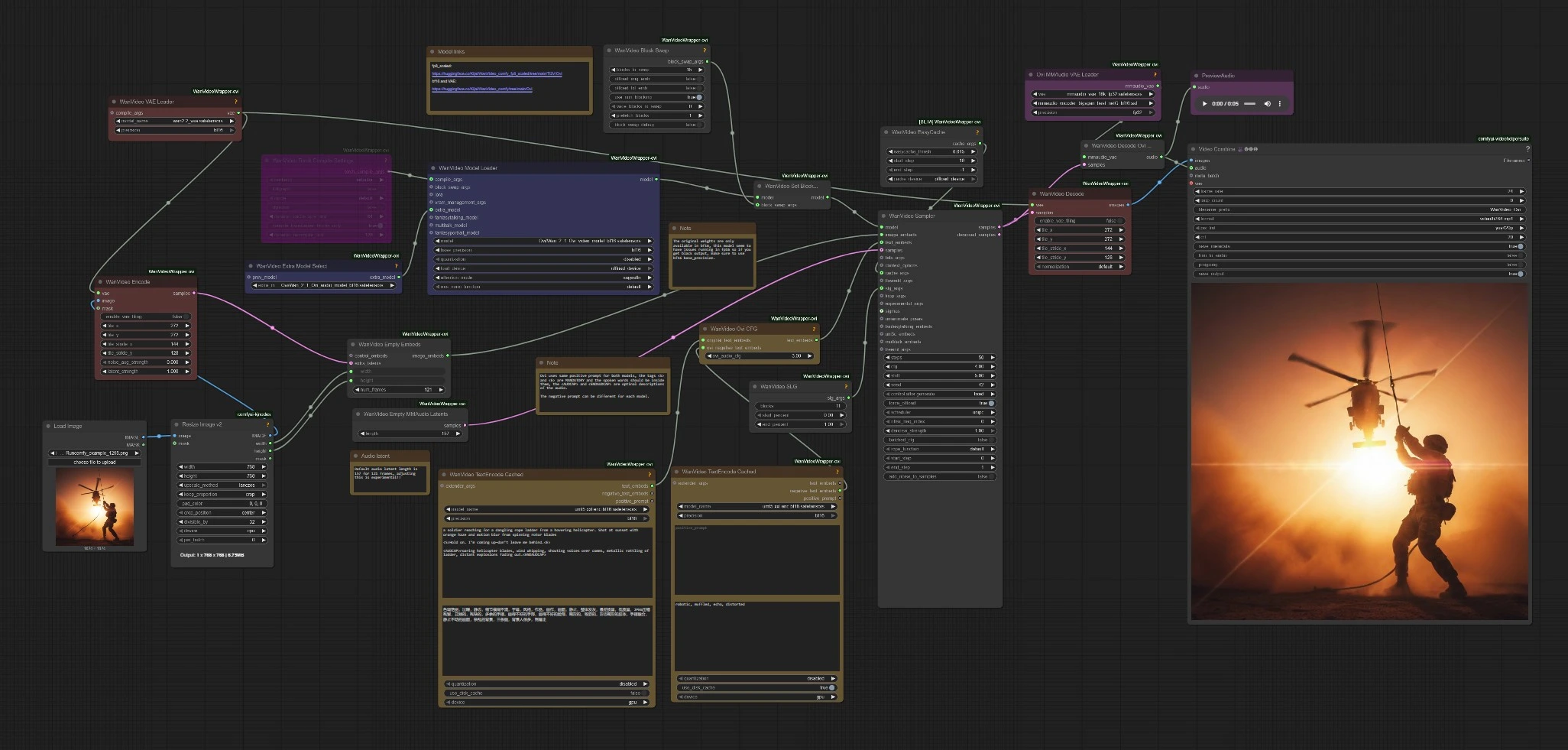
Ce workflow suit un chemin simple : encodez votre invite et votre image, chargez les points de contrôle Ovi, échantillonnez les latents audio+vidéo conjoints, puis décodez et multiplexez en MP4. Les sous-sections ci-dessous correspondent aux clusters de nœuds visibles pour que vous sachiez où interagir et quels changements affectent les résultats.
Rédaction d'invites pour le discours et le son#
Écrivez une invite positive pour la scène et la ligne de discours. Utilisez les balises Ovi exactement comme montré : entourez les mots à prononcer avec <S> et <E>, et décrivez éventuellement l'audio non-verbal avec <AUDCAP> et <ENDAUDCAP>. La même invite positive conditionne à la fois les branches vidéo et audio pour que le mouvement des lèvres et le timing soient alignés. Vous pouvez utiliser différentes invites négatives pour la vidéo et l'audio pour supprimer les artefacts indépendamment. Character AI Ovi répond bien à des instructions scéniques concises plus une seule ligne de dialogue claire.
Ingérer et conditionner l'image#
Chargez un seul portrait ou une image de personnage, puis le workflow redimensionne et encode en latents. Cela établit l'identité, la pose et le cadrage initial pour l'échantillonneur. La largeur et la hauteur de l'étape de redimensionnement définissent le format vidéo ; choisissez carré pour les avatars ou vertical pour les courts métrages. Les latents encodés et les embeddings dérivés de l'image guident l'échantillonneur pour que le mouvement semble ancré au visage d'origine.
Chargement de modèles et aides à la performance#
Character AI Ovi charge trois éléments essentiels : le modèle vidéo Ovi, le VAE Wan 2.2 pour les images, et le VAE MMAudio plus BigVGAN pour l'audio. La compilation Torch et un cache léger sont inclus pour accélérer les démarrages à chaud. Un assistant d'échange de blocs est intégré pour réduire l'utilisation de la VRAM en déchargeant les blocs de transformateurs si nécessaire. Si vous êtes limité en VRAM, augmentez le déchargement de blocs dans le nœud d'échange de blocs et gardez le cache activé pour les exécutions répétées.
Échantillonnage conjoint avec guidage#
L'échantillonneur exécute les doubles backbones d'Ovi ensemble pour que la bande-son et les images co-évoluent. Un assistant de guidage de couche de saut améliore la stabilité et le détail sans sacrifier le mouvement. Le workflow route également vos embeddings textuels originaux via un mélangeur CFG spécifique à Ovi pour que vous puissiez incliner l'équilibre entre l'adhérence stricte à l'invite et l'animation plus libre. Character AI Ovi a tendance à produire le meilleur mouvement des lèvres lorsque la ligne prononcée est courte, littérale et uniquement encadrée par les balises <S> et <E>.
Décodage, aperçu et exportation#
Après l'échantillonnage, les latents vidéo sont décodés via le VAE Wan tandis que les latents audio sont décodés via MMAudio avec BigVGAN. Un combinateur vidéo multiplexe les images et l'audio en un MP4 à 24 fps, prêt à être partagé. Vous pouvez également prévisualiser l'audio directement pour vérifier l'intelligibilité du discours avant de sauvegarder. Le chemin par défaut de Character AI Ovi vise 5 secondes ; étendez prudemment pour garder les lèvres et le rythme synchronisés.
Nœuds clés dans le workflow Comfyui Character AI Ovi#
WanVideoTextEncodeCached(#85)
Encode l'invite positive principale et l'invite négative vidéo en embeddings utilisés par les deux branches. Gardez le dialogue à l'intérieur de <S>…<E> et placez la conception sonore à l'intérieur de <AUDCAP>…<ENDAUDCAP>. Pour un meilleur alignement, évitez plusieurs phrases dans une balise de discours et gardez la ligne concise.
WanVideoTextEncodeCached(#96)
Fournit un embedding de texte négatif dédié pour l'audio. Utilisez-le pour supprimer les artefacts tels que le ton robotique ou une réverbération lourde sans affecter les visuels. Commencez par des descripteurs courts et développez seulement si vous entendez toujours le problème.
WanVideoOviCFG(#94)
Mélange les embeddings textuels originaux avec les négatifs spécifiques à l'audio via un guidage sans classeur conscient d'Ovi. Augmentez-le lorsque le contenu du discours dérive de la ligne écrite ou que les mouvements des lèvres semblent décalés. Abaissez-le légèrement si le mouvement devient rigide ou trop contraint.
WanVideoSampler(#80)
Le cœur de Character AI Ovi. Il consomme les embeddings d'image, les embeddings textuels conjoints et le guidage optionnel pour échantillonner un latent unique contenant à la fois vidéo et audio. Plus d'étapes augmentent la fidélité mais aussi le temps d'exécution. Si vous constatez une pression mémoire ou des blocages, associez un échange de blocs plus élevé avec le cache activé, et envisagez de désactiver la compilation torch pour un dépannage rapide.
WanVideoEmptyMMAudioLatents(#125)
Initialise la chronologie des latents audio. La longueur par défaut est réglée pour un clip de 121 images à 24 fps. Ajuster cela pour changer la durée est expérimental ; changez-le uniquement si vous comprenez comment il doit suivre le nombre d'images.
VHS_VideoCombine(#88)
Multiplexe les images décodées et l'audio en MP4. Réglez le taux de trame pour correspondre à votre cible d'échantillonnage et activez la découpe-à-l'audio si vous voulez que la coupe finale suive la forme d'onde générée. Utilisez le contrôle CRF pour équilibrer la taille du fichier et la qualité.
Extras optionnels#
- Utilisez bf16 pour la vidéo Ovi et le VAE Wan 2.2. Si vous rencontrez des images noires, passez à la précision de base
bf16pour les chargeurs de modèles et l'encodeur de texte. - Gardez les discours courts. Character AI Ovi synchronise les lèvres de manière plus fiable avec un dialogue court et d'une seule phrase à l'intérieur de
<S>et<E>. - Séparez les négatifs. Mettez les artefacts visuels dans l'invite négative vidéo et les artefacts tonaux dans l'invite négative audio pour éviter les compromis involontaires.
- Prévisualisez d'abord. Utilisez la prévisualisation audio pour confirmer la clarté et le rythme avant d'exporter le MP4 final.
- Obtenez les poids exacts utilisés. Le workflow s'attend aux points de contrôle vidéo et audio Ovi plus le VAE Wan 2.2 à partir des miroirs de modèles de Kijai. WanVideo_comfy/Ovi • WanVideo_comfy_fp8_scaled/TI2V/Ovi
Avec ces éléments en place, Character AI Ovi devient un pipeline compact et convivial pour les créateurs, pour des avatars parlants expressifs et des scènes narratives qui sonnent aussi bien qu'elles ne paraissent.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement kijai et Character AI pour Ovi pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts d'origine liés ci-dessous.
Ressources#
- Source Character AI Ovi
- Workflow: wanvideo_2_2_5B_ovi_testing @kijai
- Github: character-ai/Ovi
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.
