
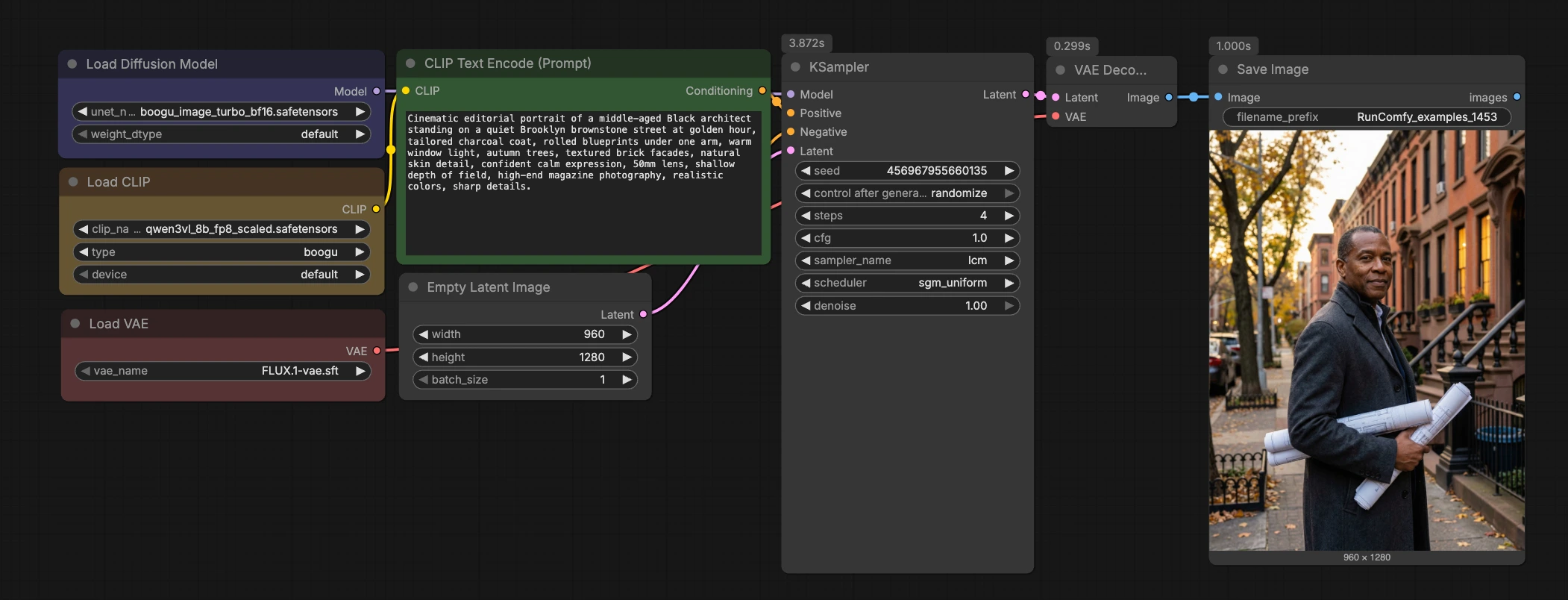






Flux de travail Boogu Turbo text-to-image ComfyUI#
Ce flux de travail Boogu Turbo text-to-image ComfyUI est un chemin rapide et propre du prompt à l'image en utilisant le checkpoint Boogu-Image-0.1-Turbo avec un échantillonnage LCM en quatre étapes. Il associe l'encodeur de texte Qwen3-VL avec le FLUX.1 VAE, vous permettant d'itérer rapidement tout en gardant le graphe minimal et facile à réutiliser dans divers projets.
Conçu pour une exploration visuelle rapide, le flux de travail excelle dans les environnements cinématographiques, les arrière-plans de style anime, les paysages atmosphériques, les machines de produits imaginatives et les scènes architecturales. Si vous souhaitez un flux de travail Boogu Turbo text-to-image ComfyUI léger, prêt pour RunComfy et simple à inspecter, ce modèle est un bon point de départ.
Modèles clés dans le flux de travail Comfyui Boogu Turbo text-to-image ComfyUI#
- Boogu-Image-0.1-Turbo. La variante Turbo distillée est construite pour une génération de texte en image rapide et photoréaliste avec une inférence typique de 3 à 4 étapes et une échelle de guidage proche de 1.0. Les poids du modèle officiel et les instructions sont disponibles sur Hugging Face, avec des fichiers repackagés prêts pour ComfyUI fournis par Comfy-Org. Voir Boogu/Boogu-Image-0.1-Turbo-fp8 et le pack ComfyUI à Comfy-Org/Boogu-Image.
- Encodeur de texte Qwen3-VL 8B. Cette architecture moderne vision-langage est utilisée ici uniquement comme encodeur de texte pour produire des embeddings de prompt puissants pour le modèle de diffusion. Les encodeurs packagés ComfyUI sont hébergés chez Comfy-Org/Qwen3-VL et le dépôt officiel est QwenLM/Qwen3-VL.
- FLUX.1 VAE. L'autoencodeur de Black Forest Labs encode et décode les images entre les espaces de pixels et latents, aidant à préserver la fidélité des couleurs et des contrastes. Les poids de référence et la documentation sont disponibles chez black-forest-labs/FLUX.1-dev.
Comment utiliser le flux de travail Comfyui Boogu Turbo text-to-image ComfyUI#
En un coup d'œil, le flux de travail encode votre prompt, initialise une toile latente, exécute un échantillonneur LCM rapide via Boogu-Image-0.1-Turbo, décode avec le FLUX.1 VAE, et enregistre le résultat. Le graphe est intentionnellement compact pour que vous puissiez l'intégrer dans d'autres projets ou l'étendre avec LoRAs, ControlNets, ou des chaînes de post-traitement.
Encodage de prompt avec Qwen3-VL (CLIPLoader (#7) → CLIPTextEncode (#11))#
Cette étape charge un encodeur Qwen3-VL et convertit votre prompt textuel en vecteurs de conditionnement. Entrez votre prompt dans CLIPTextEncode (#11) en utilisant le langage naturel; des indices photographiques détaillés comme l'objectif, l'éclairage, l'heure de la journée et la texture fonctionnent bien. L'entrée négative est intentionnellement mise à zéro via ConditioningZeroOut (#9) pour garder les résultats stables avec le régime de faible guidage de Turbo. Si vous préférez des négatifs explicites, remplacez ConditioningZeroOut par un second CLIPTextEncode pour fournir un prompt négatif. Une bonne hygiène de prompt ici réduit le besoin d'un CFG élevé ou d'étapes supplémentaires plus tard.
Configuration latente et chargement du modèle (EmptyLatentImage (#8) + UNETLoader (#2))#
EmptyLatentImage (#8) crée la toile latente. L'aspect portrait par défaut 960×1280 est un point de départ équilibré pour les personnes, les intérieurs, et les photos de produits en hauteur; vous pouvez définir d'autres tailles pour des carrés ou des formats larges. UNETLoader (#2) charge les poids de diffusion Boogu Turbo du pack Comfy-Org, alignant le modèle avec votre encodeur et VAE choisis. L'échange de variantes BF16 et FP8 est simple si vous devez équilibrer VRAM et débit. Gardez le choix de modèle cohérent sur votre projet pour maintenir la continuité du style.
Échantillonnage rapide LCM (KSampler (#32) avec échantillonneur lcm)#
Le KSampler est configuré pour les modèles de consistance latente afin d'atteindre une haute qualité en environ quatre étapes. La distillation LCM cible des valeurs de guidage très faibles, c'est pourquoi ce flux de travail Boogu Turbo text-to-image ComfyUI fonctionne de manière stable avec un CFG proche de 1.0 tout en préservant l'adhérence au prompt. Si vous souhaitez un peu plus de micro-détails, augmentez modestement les étapes et fixez la graine pour des comparaisons A/B. Pour des changements de style ou de composition, relancez la graine et affinez le prompt plutôt que de pousser les étapes trop haut. La théorie de fond sur l'inférence en quelques étapes LCM est décrite dans l'article original Latent Consistency Models.
Décodage et sauvegarde (VAELoader (#5) → VAEDecode (#3) → SaveImage (#58))#
Le FLUX.1 VAE chargé dans VAELoader (#5) décode les latents en RGB dans VAEDecode (#3). Associer la famille VAE à votre modèle de diffusion produit généralement des couleurs et des textures plus fidèles, c'est pourquoi ce graphe est livré avec le FLUX.1 VAE. SaveImage (#58) écrit les résultats sur le disque; changez le préfixe de sortie pour organiser les expériences par prompt, graine, ou ratio d'aspect. Si vous ajoutez ensuite des upscalers ou des effets post-traitement, branchez à partir de la sortie Image de VAEDecode pour préserver un historique propre.
Nœuds clés dans le flux de travail Comfyui Boogu Turbo text-to-image ComfyUI#
CLIPTextEncode (#11)#
Ce nœud contient votre prompt textuel principal et produit le conditionnement positif utilisé par l'échantillonneur. Gardez les prompts concis, et ajoutez des indices de scène comme la longueur focale de la caméra, l'heure de la journée, et des adjectifs matériels. Si vous souhaitez utiliser des prompts négatifs, créez un second CLIPTextEncode et connectez-le à l'entrée négative de l'échantillonneur, en supprimant ConditioningZeroOut (#9).
ConditioningZeroOut (#9)#
Cela désactive le conditionnement négatif en introduisant un vecteur zéro dans le port négatif de l'échantillonneur. Le laisser en place est un bon défaut pour la configuration de faible guidage de Turbo. Retirez-le uniquement lorsque vous avez spécifiquement besoin de prompts négatifs et pouvez les articuler clairement.
EmptyLatentImage (#8)#
Contrôle les dimensions de sortie et la taille du lot. Commencez à 960×1280 pour les portraits ou 1280×960 pour les environnements plus larges; ajustez en fonction du sujet et du budget mémoire. Des latents plus grands offrent plus de toile pour les détails fins mais augmentent l'utilisation de la VRAM et le temps de décodage.
UNETLoader (#2)#
Sélectionne le checkpoint Boogu-Image-0.1-Turbo à utiliser pour la génération. Utilisez la variante BF16 pour une fidélité maximale sur les GPU capables ou la variante FP8 pour une VRAM inférieure et des chargements plus rapides, toutes deux disponibles dans le package Comfy-Org. Les fichiers de modèle et leurs dossiers prévus sont documentés chez Comfy-Org/Boogu-Image.
KSampler (#32)#
Exécute le processus de diffusion avec l'échantillonneur lcm pour une inférence en quelques étapes. Les leviers clés sont la graine, le nombre d'étapes, et le CFG; Turbo est conçu pour fonctionner avec un très faible guidage et quelques étapes tout en maintenant la qualité, comme reflété dans les paramètres officiels de Turbo sur la carte modèle à Boogu/Boogu-Image-0.1-Turbo-fp8. Pour des explorations contrôlées, fixez la graine et variez les étapes ou le libellé du prompt un changement à la fois.
VAELoader (#5) et VAEDecode (#3)#
Charge et applique le FLUX.1 VAE pour le décodage. Rester avec la famille FLUX.1 garde les couleurs, le contraste, et le comportement de texture cohérents avec la configuration d'entraînement du UNet. Mélanger les VAE est possible mais peut subtilement modifier la tonalité ou la saturation; testez avant de vous engager dans un nouveau look. Poids de référence : black-forest-labs/FLUX.1-dev.
SaveImage (#58)#
Contrôle la dénomination et la destination de la sortie. Utilisez des préfixes significatifs comme le nom du projet, l'étiquette d'aspect, ou la graine pour garder les exécutions organisées. Lors de l'expansion du pipeline, branchez ici pour ajouter des upscalers, des corrections de couleur, ou des légendeurs sans perturber la sauvegarde de base.
Extras optionnels#
- Gardez le CFG près de 1.0 et les étapes autour de quatre pour les itérations les plus rapides; passez à 6-8 étapes uniquement lorsque vous avez besoin d'un peu plus de texture ou de stabilité.
- Relancez la graine pour explorer la composition; fixez la graine pour affiner le style et le micro-détail.
- Préférez les poids BF16 pour la meilleure qualité sur les GPU à haute mémoire; passez à FP8 pour accélérer le chargement et réduire la VRAM.
- Pour la lisibilité du texte dans l'image, essayez une résolution légèrement plus élevée et incluez des indices typographiques explicites dans le prompt.
- Sauvegardez souvent les favoris intermédiaires; de petites modifications du prompt dans ce flux de travail Boogu Turbo text-to-image ComfyUI peuvent produire des scènes sensiblement différentes en quelques secondes.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions RunningHub pour la référence du flux de travail, Boogu pour le dépôt Boogu-Image et le modèle Boogu-Image-0.1-Turbo, Comfy-Org pour les poids Boogu ComfyUI, et ComfyUI pour le tutoriel Boogu pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- RunningHub/Référence de flux de travail
- Docs / Notes de version : Publication RunningHub
- Boogu/Site du projet
- Docs / Notes de version : boogu.org
- Boogu/Dépôt d'image Boogu
- GitHub : boogu-project/Boogu-Image
- Hugging Face : Boogu/Boogu-Image-0.1-Turbo
- Boogu/Modèle Boogu-Image-0.1-Turbo
- Hugging Face : Boogu/Boogu-Image-0.1-Turbo
- GitHub : boogu-project/Boogu-Image
- Poids Boogu ComfyUI de Comfy-Org
- Hugging Face : Comfy-Org/Boogu-Image
- Tutoriel Boogu de ComfyUI
- Docs / Notes de version : Tutoriel ComfyUI
Note : L'utilisation des modèles, jeux de données et code référencés est soumise aux licences et termes respectifs fournis par leurs auteurs et mainteneurs.



