



¡Hola, compañeros artistas de IA! 👋 Bienvenidos a nuestro tutorial amigable para principiantes sobre ComfyUI, una herramienta increíblemente poderosa y flexible para crear impresionantes obras de arte generadas por IA. 🎨 En esta guía, te guiaremos a través de los conceptos básicos de ComfyUI, exploraremos sus características y te ayudaremos a desbloquear su potencial para llevar tu arte de IA al siguiente nivel. 🚀
Cubriremos:
- 1. ¿Qué es ComfyUI?
- 1.1. ComfyUI vs. AUTOMATIC1111
- 1.2. ¿Por dónde empezar con ComfyUI?
- 1.3. Controles básicos
- 2. Flujos de trabajo de ComfyUI: De texto a imagen
- 2.1. Seleccionar un modelo
- 2.2. Ingresar el prompt positivo y negativo
- 2.3. Generar una imagen
- 2.4. Explicación técnica de ComfyUI
- 2.4.1 Nodo Load Checkpoint
- 2.4.2. CLIP Text Encode
- 2.4.3. Empty Latent Image
- 2.4.4. VAE
- 2.4.5. KSampler
- 3. Flujo de trabajo de ComfyUI: De imagen a imagen
- 4. ComfyUI SDXL
- 5. ComfyUI Inpainting
- 6. ComfyUI Outpainting
- 7. ComfyUI Upscale
- 7.1. Upscale Pixel
- 7.1.1. Upscale Pixel por algoritmo
- 7.1.2. Upscale Pixel por modelo
- 7.2. Upscale Latent
- 7.3. Upscale Pixel vs. Upscale Latent
- 8. ComfyUI ControlNet
- 9. Administrador de ComfyUI
- 9.1. Cómo instalar nodos personalizados faltantes
- 9.2. Cómo actualizar nodos personalizados
- 9.3. Cómo cargar nodos personalizados en tu flujo de trabajo
- 10. Embeddings de ComfyUI
- 10.1. Embedding con autocompletar
- 10.2. Peso de embedding
- 11. ComfyUI LoRA
- 11.1. Flujos de trabajo simples de LoRA
- 11.2. Múltiples LoRAs
- 12. Atajos y trucos para ComfyUI
- 12.1. Copiar y pegar
- 12.2. Mover múltiples nodos
- 12.3. Omitir un nodo
- 12.4. Minimizar un nodo
- 12.5. Generar imagen
- 12.6. Flujo de trabajo incrustado
- 12.7. Fijar semillas para ahorrar tiempo
1. ¿Qué es ComfyUI? 🤔#
ComfyUI es como tener una varita mágica 🪄 para crear impresionantes obras de arte generadas por IA con facilidad. En esencia, ComfyUI es una interfaz gráfica de usuario (GUI) basada en nodos construida sobre Stable Diffusion, un modelo de aprendizaje profundo de vanguardia que genera imágenes a partir de descripciones de texto. 🌟 Pero lo que hace que ComfyUI sea realmente especial es cómo empodera a artistas como tú para liberar tu creatividad y dar vida a tus ideas más salvajes.
Imagina un lienzo digital donde puedes construir tus propios flujos de trabajo únicos de generación de imágenes conectando diferentes nodos, cada uno representando una función u operación específica. 🧩 ¡Es como construir una receta visual para tus obras maestras generadas por IA!
¿Quieres generar una imagen desde cero usando un prompt de texto? ¡Hay un nodo para eso! ¿Necesitas aplicar un sampler específico o ajustar el nivel de ruido? Simplemente agrega los nodos correspondientes y observa la magia suceder. ✨
Pero aquí está la mejor parte: ComfyUI descompone el flujo de trabajo en elementos reordenables, dándote la libertad de crear tus propios flujos de trabajo personalizados adaptados a tu visión artística. 🖼️ Es como tener un kit de herramientas personalizado que se adapta a tu proceso creativo.
1.1. ComfyUI vs. AUTOMATIC1111 🆚#
AUTOMATIC1111 es la GUI predeterminada para Stable Diffusion. Entonces, ¿deberías usar ComfyUI en su lugar? Comparemos:
✅ Beneficios de usar ComfyUI:
- Ligero: Se ejecuta rápida y eficientemente.
- Flexible: Altamente configurable para adaptarse a tus necesidades.
- Transparente: El flujo de datos es visible y fácil de entender.
- Fácil de compartir: Cada archivo representa un flujo de trabajo reproducible.
- Bueno para prototipos: Crea prototipos con una interfaz gráfica en lugar de codificar.
❌ Desventajas de usar ComfyUI:
- Interfaz inconsistente: Cada flujo de trabajo puede tener un diseño de nodos diferente.
- Demasiados detalles: Los usuarios promedio pueden no necesitar conocer las conexiones subyacentes.
1.2. ¿Por dónde empezar con ComfyUI? 🏁#
Creemos que la mejor manera de aprender ComfyUI es sumergiéndote en ejemplos y experimentándolo de primera mano. 🙌 Es por eso que hemos creado este tutorial único que se distingue de los demás. En este tutorial, encontrarás una guía detallada paso a paso que puedes seguir.
Pero aquí está la mejor parte: 🌟 ¡Hemos integrado ComfyUI directamente en esta página web! Podrás interactuar con ejemplos de ComfyUI en tiempo real a medida que avanzas en la guía.🌟 ¡Sumerjámonos!
2. Flujos de trabajo de ComfyUI: De texto a imagen 🖼️#
Comencemos con el caso más simple: generar una imagen a partir de texto. Haz clic en Queue Prompt para ejecutar el flujo de trabajo. Después de una breve espera, ¡deberías ver tu primera imagen generada! Para verificar tu cola, simplemente haz clic en View Queue.
Aquí hay un flujo de trabajo predeterminado de texto a imagen para que lo pruebes:
Bloques de construcción básicos 🕹️#
El flujo de trabajo de ComfyUI consta de dos bloques de construcción básicos: Nodos y Bordes.
- Nodos son los bloques rectangulares, por ejemplo, Load Checkpoint, Clip Text Encoder, etc. Cada nodo ejecuta un código específico y requiere entradas, salidas y parámetros.
- Bordes son los cables que conectan las salidas y entradas entre los nodos.
Controles básicos 🕹️#
- Acerca y aleja con la rueda del mouse o pellizco de dos dedos.
- Arrastra y mantén presionado el punto de entrada o salida para crear conexiones entre nodos.
- Muévete por el espacio de trabajo manteniendo y arrastrando con el botón izquierdo del mouse.
Profundicemos en los detalles de este flujo de trabajo.#
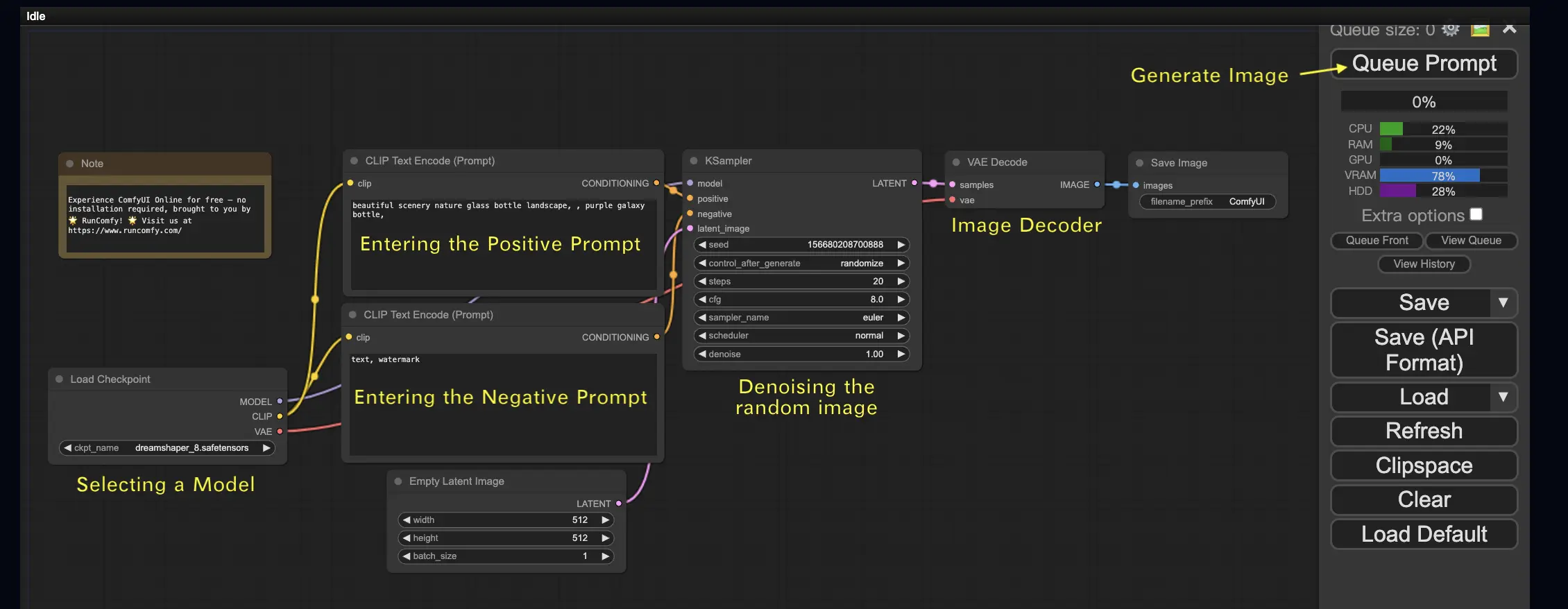
2.1. Seleccionar un modelo 🗃️#
Primero, selecciona un modelo Checkpoint de Stable Diffusion en el nodo Load Checkpoint. Haz clic en el nombre del modelo para ver los modelos disponibles. Si al hacer clic en el nombre del modelo no sucede nada, es posible que debas cargar un modelo personalizado.
2.2. Ingresar el prompt positivo y negativo 📝#
Verás dos nodos etiquetados como CLIP Text Encode (Prompt). El prompt superior está conectado a la entrada positive del nodo KSampler, mientras que el prompt inferior está conectado a la entrada negative. Así que ingresa tu prompt positivo en el superior y tu prompt negativo en el inferior.
El nodo CLIP Text Encode convierte el prompt en tokens y los codifica en embeddings usando el codificador de texto.
💡 Consejo: Usa la sintaxis (palabra clave:peso) para controlar el peso de una palabra clave, por ejemplo, (palabra clave:1.2) para aumentar su efecto o (palabra clave:0.8) para disminuirlo.
2.3. Generar una imagen 🎨#
Haz clic en Queue Prompt para ejecutar el flujo de trabajo. Después de una breve espera, ¡se generará tu primera imagen!
2.4. Explicación técnica de ComfyUI 🤓#
El poder de ComfyUI radica en su capacidad de configuración. Comprender qué hace cada nodo te permite adaptarlos a tus necesidades. Pero antes de sumergirnos en los detalles, echemos un vistazo al proceso de Stable Diffusion para entender mejor cómo funciona ComfyUI.
El proceso de Stable Diffusion se puede resumir en tres pasos principales:
- Codificación de texto: El prompt ingresado por el usuario es compilado en vectores de características de palabras individuales por un componente llamado Text Encoder. Este paso convierte el texto en un formato que el modelo puede entender y con el que puede trabajar.
- Transformación del espacio latente: Los vectores de características del Text Encoder y una imagen de ruido aleatorio se transforman en un espacio latente. En este espacio, la imagen aleatoria se somete a un proceso de eliminación de ruido basado en los vectores de características, lo que da como resultado un producto intermedio. Este paso es donde ocurre la magia, ya que el modelo aprende a asociar las características del texto con representaciones visuales.
- Decodificación de imagen: Finalmente, el producto intermedio del espacio latente es decodificado por el Image Decoder, convirtiéndolo en una imagen real que podemos ver y apreciar.
Ahora que tenemos una comprensión de alto nivel del proceso de Stable Diffusion, profundicemos en los componentes y nodos clave en ComfyUI que hacen posible este proceso.
2.4.1 Nodo Load Checkpoint 🗃️#
El nodo Load Checkpoint en ComfyUI es crucial para seleccionar un modelo de Stable Diffusion. Un modelo de Stable Diffusion consta de tres componentes principales: MODEL, CLIP y VAE. Exploremos cada componente y su relación con los nodos correspondientes en ComfyUI.
- MODEL: El componente MODEL es el modelo predictor de ruido que opera en el espacio latente. Es responsable del proceso central de generar imágenes a partir de la representación latente. En ComfyUI, la salida MODEL del nodo Load Checkpoint se conecta al nodo KSampler, donde tiene lugar el proceso de difusión inversa. El nodo KSampler utiliza el MODEL para eliminar el ruido de la representación latente de forma iterativa, refinando gradualmente la imagen hasta que coincida con el prompt deseado.
- CLIP: CLIP (Contrastive Language-Image Pre-training) es un modelo de lenguaje que procesa previamente los prompts positivos y negativos proporcionados por el usuario. Convierte los prompts de texto en un formato que el MODEL puede entender y usar para guiar el proceso de generación de imágenes. En ComfyUI, la salida CLIP del nodo Load Checkpoint se conecta al nodo CLIP Text Encode. El nodo CLIP Text Encode toma los prompts proporcionados por el usuario y los alimenta al modelo de lenguaje CLIP, transformando cada palabra en embeddings. Estos embeddings capturan el significado semántico de las palabras y permiten que el MODEL genere imágenes que se alineen con los prompts dados.
- VAE: VAE (Variational AutoEncoder) es responsable de convertir la imagen entre el espacio de píxeles y el espacio latente. Consiste en un codificador que comprime la imagen en una representación latente de menor dimensión y un decodificador que reconstruye la imagen a partir de la representación latente. En el proceso de texto a imagen, el VAE se utiliza solo en el paso final para convertir la imagen generada del espacio latente de vuelta al espacio de píxeles. El nodo VAE Decode en ComfyUI toma la salida del nodo KSampler (que opera en el espacio latente) y utiliza la parte decodificadora del VAE para transformar la representación latente en la imagen final enel espacio de píxeles.
Es importante tener en cuenta que el VAE es un componente separado del modelo de lenguaje CLIP. Mientras que CLIP se enfoca en procesar los prompts de texto, el VAE se ocupa de la conversión entre los espacios de píxeles y latentes.
2.4.2. CLIP Text Encode 📝#
El nodo CLIP Text Encode en ComfyUI es responsable de tomar los prompts proporcionados por el usuario y alimentarlos al modelo de lenguaje CLIP. CLIP es un poderoso modelo de lenguaje que comprende el significado semántico de las palabras y puede asociarlas con conceptos visuales. Cuando se ingresa un prompt en el nodo CLIP Text Encode, se somete a un proceso de transformación donde cada palabra se convierte en embeddings. Estos embeddings son vectores de alta dimensión que capturan la información semántica de las palabras. Al transformar los prompts en embeddings, CLIP permite que el MODEL genere imágenes que reflejen con precisión el significado y la intención de los prompts dados.
2.4.3. Empty Latent Image 🌌#
En el proceso de texto a imagen, la generación comienza con una imagen aleatoria en el espacio latente. Esta imagen aleatoria sirve como el estado inicial con el que trabaja el MODEL. El tamaño de la imagen latente es proporcional al tamaño real de la imagen en el espacio de píxeles. En ComfyUI, puedes ajustar la altura y el ancho de la imagen latente para controlar el tamaño de la imagen generada. Además, puedes establecer el tamaño del lote para determinar la cantidad de imágenes generadas en cada ejecución.
Los tamaños óptimos para las imágenes latentes dependen del modelo específico de Stable Diffusion que se esté utilizando. Para los modelos SD v1.5, los tamaños recomendados son 512x512 o 768x768, mientras que para los modelos SDXL, el tamaño óptimo es 1024x1024. ComfyUI proporciona una variedad de relaciones de aspecto comunes para elegir, como 1:1 (cuadrado), 3:2 (paisaje), 2:3 (retrato), 4:3 (paisaje), 3:4 (retrato), 16:9 (pantalla ancha) y 9:16 (vertical). Es importante tener en cuenta que el ancho y la altura de la imagen latente deben ser divisibles por 8 para garantizar la compatibilidad con la arquitectura del modelo.
2.4.4. VAE 🔍#
El VAE (Variational AutoEncoder) es un componente crucial en el modelo de Stable Diffusion que maneja la conversión de imágenes entre el espacio de píxeles y el espacio latente. Consta de dos partes principales: un Image Encoder y un Image Decoder.
El Image Encoder toma una imagen en el espacio de píxeles y la comprime en una representación latente de menor dimensión. Este proceso de compresión reduce significativamente el tamaño de los datos, lo que permite un procesamiento y almacenamiento más eficientes. Por ejemplo, una imagen de tamaño 512x512 píxeles se puede comprimir a una representación latente de tamaño 64x64.
Por otro lado, el Image Decoder, también conocido como VAE Decoder, es responsable de reconstruir la imagen a partir de la representación latente de vuelta al espacio de píxeles. Toma la representación latente comprimida y la expande para generar la imagen final.
El uso de un VAE ofrece varias ventajas:
- Eficiencia: Al comprimir la imagen en un espacio latente de menor dimensión, el VAE permite una generación más rápida y tiempos de entrenamiento más cortos. El tamaño reducido de los datos permite un procesamiento y uso de memoria más eficientes.
- Manipulación del espacio latente: El espacio latente proporciona una representación más compacta y significativa de la imagen. Esto permite un control y edición más precisos de los detalles y el estilo de la imagen. Al manipular la representación latente, se vuelve posible modificar aspectos específicos de la imagen generada.
Sin embargo, también hay algunas desventajas a considerar:
- Pérdida de datos: Durante el proceso de codificación y decodificación, algunos detalles de la imagen original pueden perderse. Los pasos de compresión y reconstrucción pueden introducir artefactos o ligeras variaciones en la imagen final en comparación con la original.
- Captura limitada de los datos originales: El espacio latente de menor dimensión puede no ser capaz de capturar completamente todas las características y detalles intrincados de la imagen original. Cierta información puede perderse durante el proceso de compresión, lo que resulta en una representación ligeramente menos precisa de los datos originales.
A pesar de estas limitaciones, el VAE desempeña un papel vital en el modelo de Stable Diffusion al permitir una conversión eficiente entre el espacio de píxeles y el espacio latente, facilitando una generación más rápida y un control más preciso sobre las imágenes generadas.
2.4.5. KSampler ⚙️#
El nodo KSampler en ComfyUI es el corazón del proceso de generación de imágenes en Stable Diffusion. Es responsable de eliminar el ruido de la imagen aleatoria en el espacio latente para que coincida con el prompt proporcionado por el usuario. El KSampler emplea una técnica llamada difusión inversa, donde refina iterativamente la representación latente eliminando el ruido y agregando detalles significativos basados en la orientación de los embeddings de CLIP.
El nodo KSampler ofrece varios parámetros que permiten a los usuarios ajustar con precisión el proceso de generación de imágenes:
Seed: El valor de la semilla controla el ruido inicial y la composición de la imagen final. Al establecer una semilla específica, los usuarios pueden lograr resultados reproducibles y mantener la coherencia entre múltiples generaciones.
Control_after_generation: Este parámetro determina cómo cambia el valor de la semilla después de cada generación. Se puede configurar para aleatorizar (generar una nueva semilla aleatoria para cada ejecución), incrementar (aumentar el valor de la semilla en 1), decrementar (disminuir el valor de la semilla en 1) o fijo (mantener el valor de la semilla constante).
Step: El número de pasos de muestreo determina la intensidad del proceso de refinamiento. Los valores más altos dan como resultado menos artefactos e imágenes más detalladas, pero también aumentan el tiempo de generación.
Sampler_name: Este parámetro permite a los usuarios elegir el algoritmo de muestreo específico utilizado por el KSampler. Diferentes algoritmos de muestreo pueden producir resultados ligeramente diferentes y tener velocidades de generación variables.
Scheduler: El scheduler controla cómo cambia el nivel de ruido en cada paso del proceso de eliminación de ruido. Determina la tasa a la que se elimina el ruido de la representación latente.
Denoise: El parámetro denoise establece la cantidad de ruido inicial que debe ser borrado por el proceso de eliminación de ruido. Un valor de 1 significa que se eliminará todo el ruido, lo que dará como resultado una imagen limpia y detallada.
Al ajustar estos parámetros, puedes afinar el proceso de generación de imágenes para lograr los resultados deseados.
Ahora, ¿estás listo para embarcarte en tu viaje con ComfyUI?#
En RunComfy, hemos creado la mejor experiencia en línea de ComfyUI solo para ti. ¡Despídete de las instalaciones complicadas! 🎉 Prueba ComfyUI en línea ahora y libera tu potencial artístico como nunca antes! 🎉
3. Flujo de trabajo de ComfyUI: De imagen a imagen 🖼️#
El flujo de trabajo de imagen a imagen genera una imagen basada en un prompt y una imagen de entrada. ¡Inténtalo tú mismo!
Para usar el flujo de trabajo de imagen a imagen:
- Selecciona el modelo checkpoint.
- Carga la imagen como un prompt de imagen.
- Revisa los prompts positivos y negativos.
- Opcionalmente, ajusta el denoise (fuerza de eliminación de ruido) en el nodo KSampler.
- Presiona Queue Prompt para comenzar la generación.
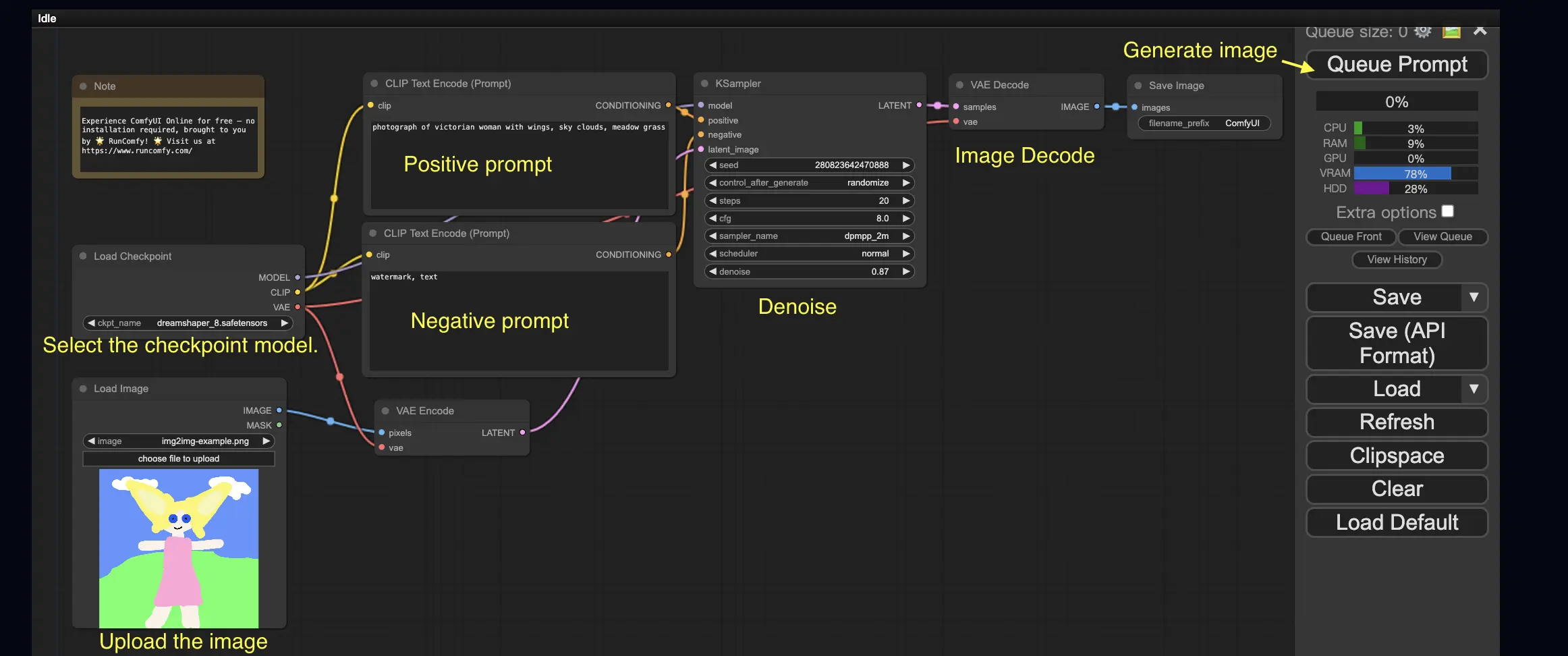
Para obtener más flujos de trabajo premium de ComfyUI, visita nuestra 🌟Lista de flujos de trabajo de ComfyUI🌟
4. ComfyUI SDXL 🚀#
Gracias a su capacidad de configuración extrema, ComfyUI es una de las primeras interfaces gráficas de usuario en admitir el modelo Stable Diffusion XL. ¡Vamos a probarlo!
Para usar el flujo de trabajo de ComfyUI SDXL:
- Revisa los prompts positivos y negativos.
- Presiona Queue Prompt para comenzar la generación.
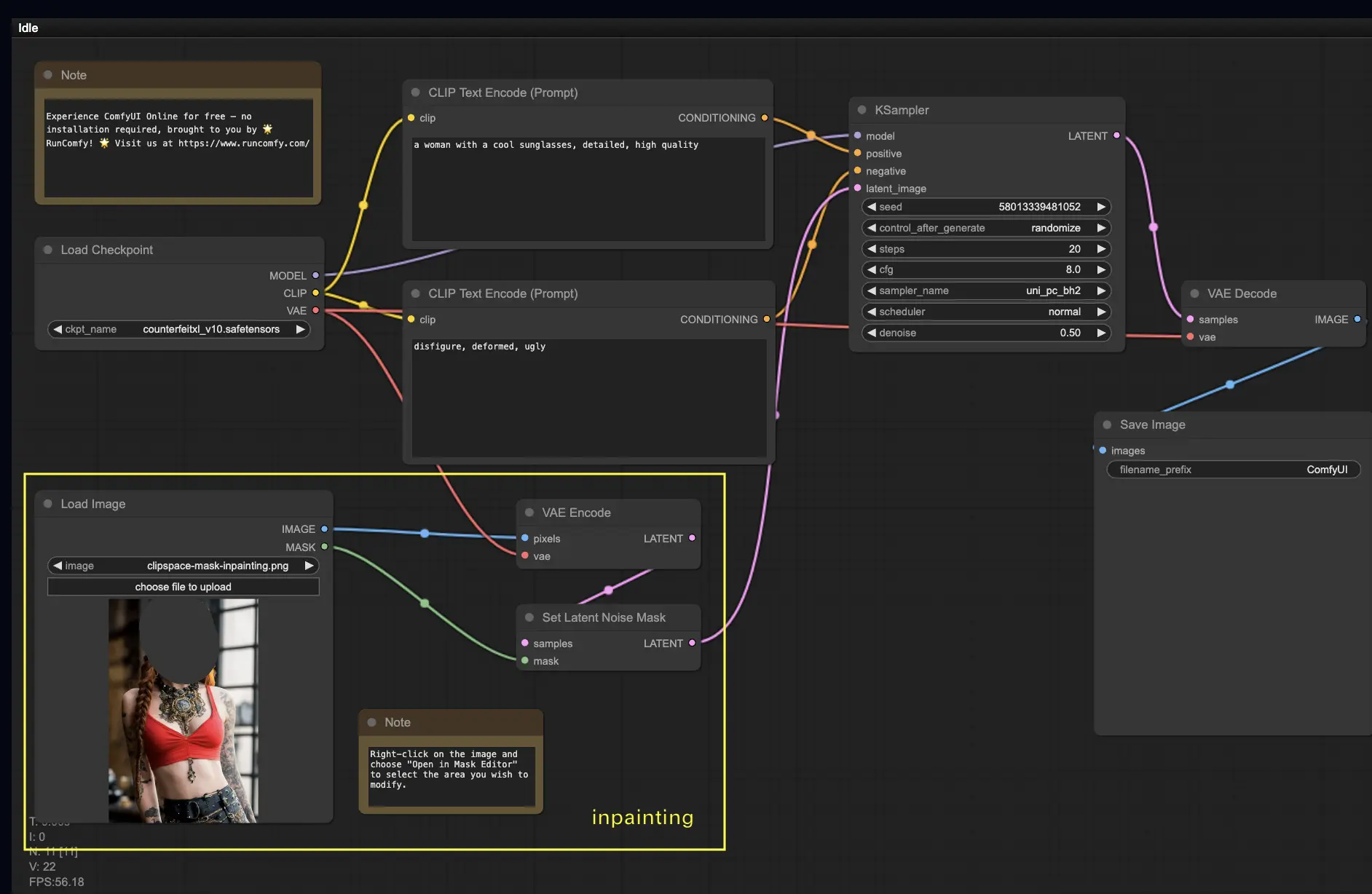
5. ComfyUI Inpainting 🎨#
¡Sumerjámonos en algo más complejo: el inpainting! Cuando tienes una gran imagen pero deseas modificar partes específicas, el inpainting es el mejor método. ¡Pruébalo aquí!
Para usar el flujo de trabajo de inpainting:
- Carga una imagen que desees modificar.
- Haz clic derecho en la imagen y selecciona "Abrir en MaskEditor". Enmascara el área a regenerar, luego haz clic en "Guardar en nodo".
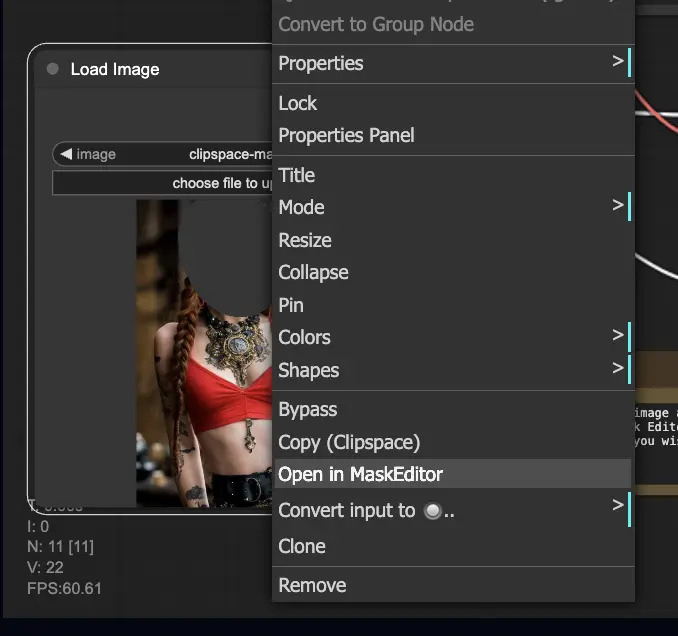
- Selecciona un modelo Checkpoint:
- Este flujo de trabajo solo funciona con un modelo estándar de Stable Diffusion, no con un modelo de Inpainting.
- Si deseas utilizar un modelo de inpainting, cambia los nodos "VAE Encode" y "Set Noise Latent Mask" al nodo "VAE Encode (Inpaint)", que está diseñado específicamente para modelos de inpainting.
- Personaliza el proceso de inpainting:
- En el nodo CLIP Text Encode (Prompt), puedes ingresar información adicional para guiar el inpainting. Por ejemplo, puedes especificar el estilo, tema o elementos que deseas incluir en el área de inpainting.
- Establece la fuerza original de eliminación de ruido (denoise), por ejemplo, 0.6.
- Presiona Queue Prompt para realizar el inpainting.
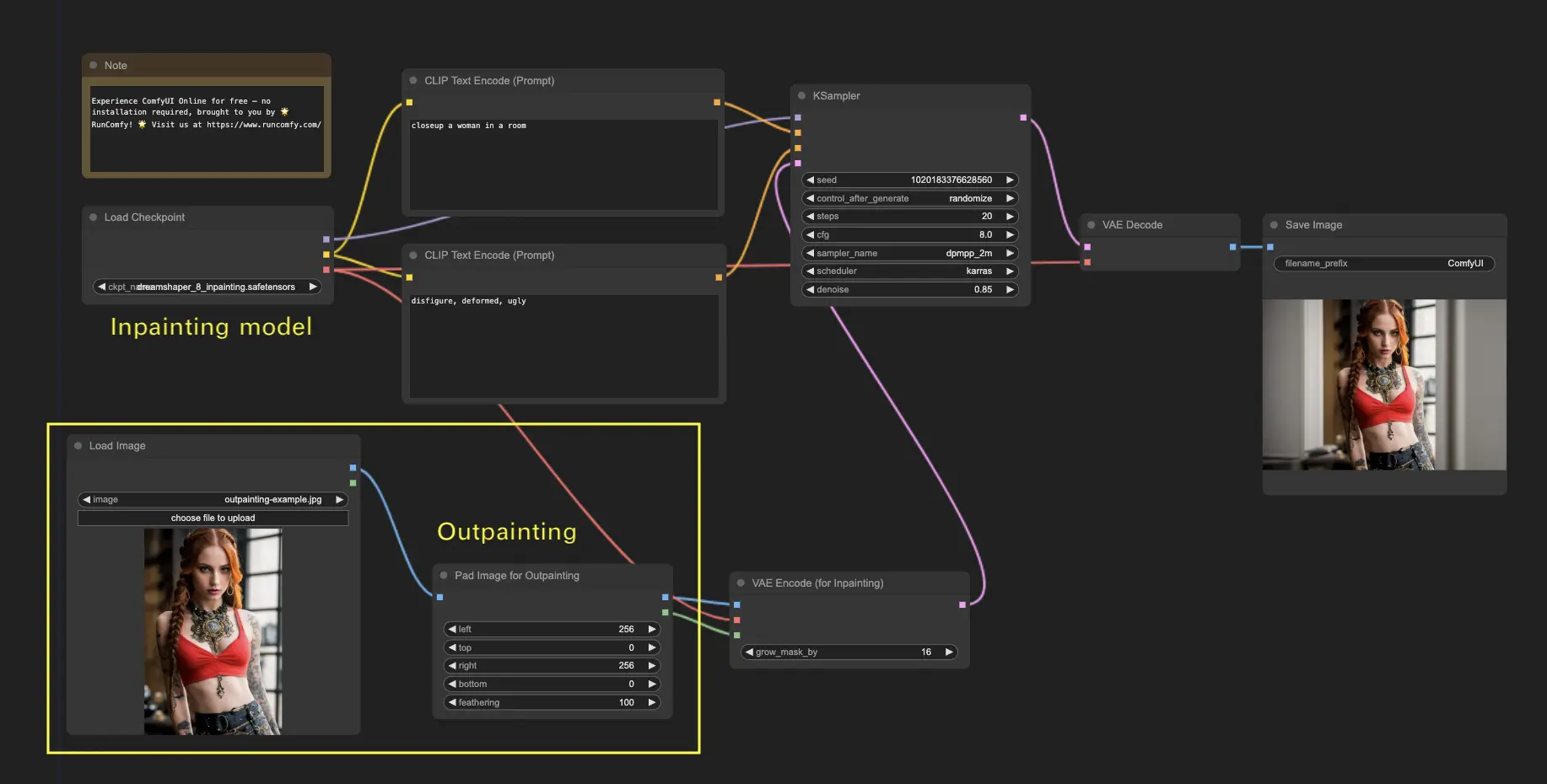
6. ComfyUI Outpainting 🖌️#
El outpainting es otra técnica emocionante que te permite expandir tus imágenes más allá de sus límites originales. 🌆 ¡Es como tener un lienzo infinito con el que trabajar!
Para usar el flujo de trabajo de outpainting de ComfyUI:
- Comienza con una imagen que desees expandir.
- Agrega el nodo Pad Image for Outpainting a tu flujo de trabajo.
- Configura los ajustes de outpainting:
- left, top, right, bottom: Especifica el número de píxeles a expandir en cada dirección.
- feathering: Ajusta la suavidad de la transición entre la imagen original y el área de outpainting. Los valores más altos crean una mezcla más gradual pero pueden introducir un efecto de difuminado.
- Personaliza el proceso de outpainting:
- En el nodo CLIP Text Encode (Prompt), puedes ingresar información adicional para guiar el outpainting. Por ejemplo, puedes especificar el estilo, tema o elementos que deseas incluir en el área expandida.
- Experimenta con diferentes prompts para lograr los resultados deseados.
- Ajusta con precisión el nodo VAE Encode (for Inpainting):
- Ajusta el parámetro grow_mask_by para controlar el tamaño de la máscara de outpainting. Se recomienda un valor mayor a 10 para obtener resultados óptimos.
- Presiona Queue Prompt para iniciar el proceso de outpainting.
Para obtener más flujos de trabajo premium de restauración/ampliación, visita nuestra 🌟Lista de flujos de trabajo de ComfyUI🌟
7. ComfyUI Upscale ⬆️#
A continuación, exploremos el upscale de ComfyUI. Introduciremos tres flujos de trabajo fundamentales para ayudarte a realizar upscale de manera eficiente.
Hay dos métodos principales para realizar upscale:
- Upscale pixel: Amplia directamente la imagen visible.
- Entrada: imagen, Salida: imagen ampliada
- Upscale latent: Amplia la imagen invisible del espacio latente.
- Entrada: latente, Salida: latente ampliado (requiere decodificación para convertirse en una imagen visible)
7.1. Upscale Pixel 🖼️#
Dos formas de lograrlo:
- Usando algoritmos: Velocidad de generación más rápida, pero resultados ligeramente inferiores en comparación con los modelos.
- Usando modelos: Mejores resultados, pero tiempo de generación más lento.
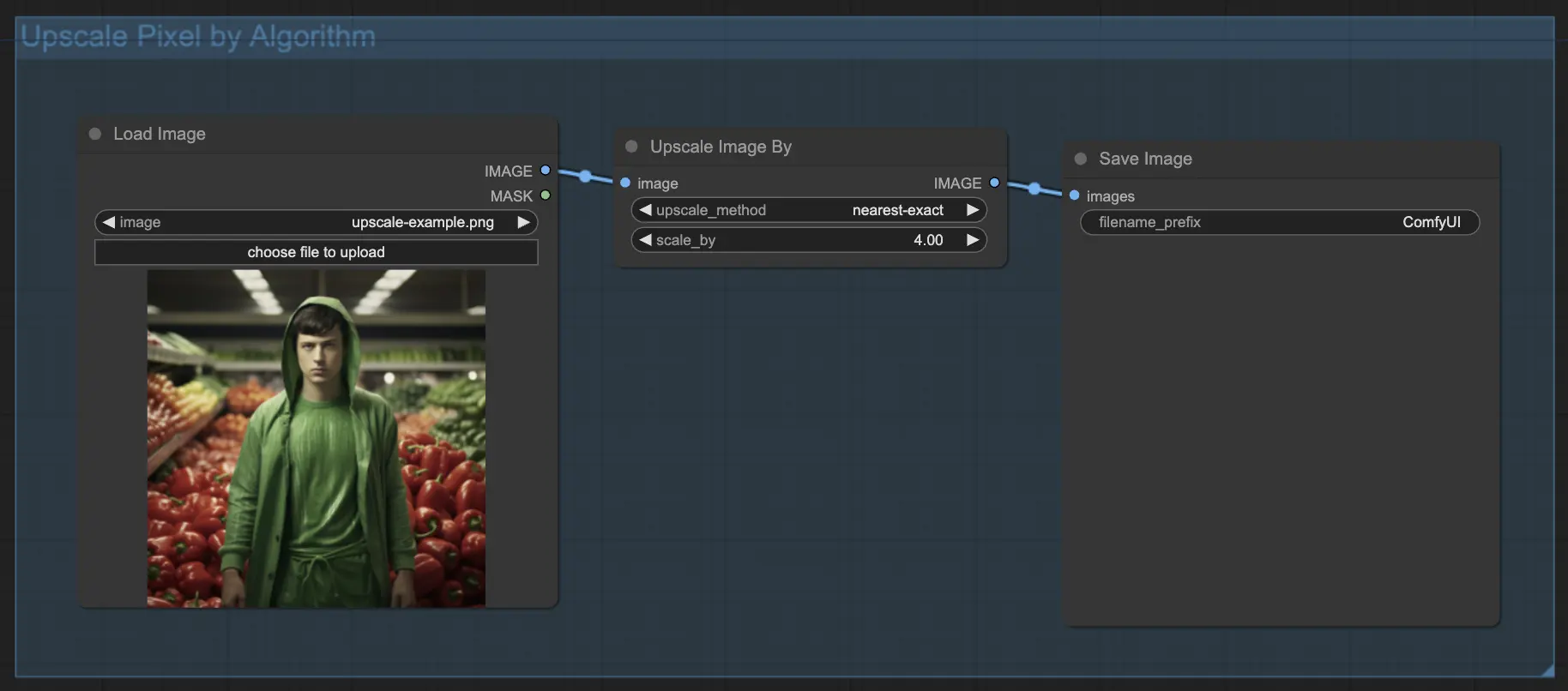
7.1.1. Upscale Pixel por algoritmo 🧮#
- Agrega el nodo Upscale Image by.
- Parámetro method: Elige el algoritmo de upscaling (bicubic, bilinear, nearest-exact).
- Parámetro Scale: Especifica el factor de ampliación (por ejemplo, 2 para 2x).
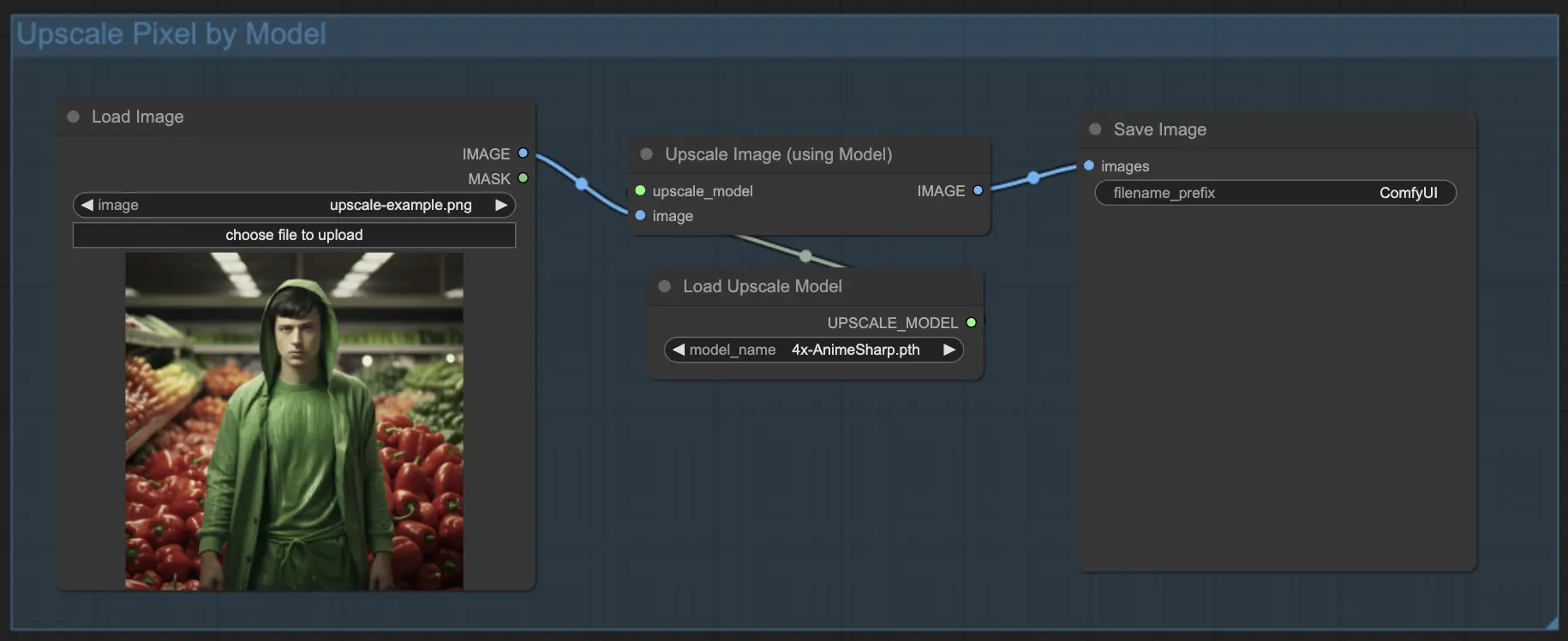
7.1.2. Upscale Pixel por modelo 🤖#
- Agrega el nodo Upscale Image (using Model).
- Agrega el nodo Load Upscale Model.
- Elige un modelo adecuado para tu tipo de imagen (por ejemplo, anime o vida real).
- Selecciona el factor de ampliación (X2 o X4).
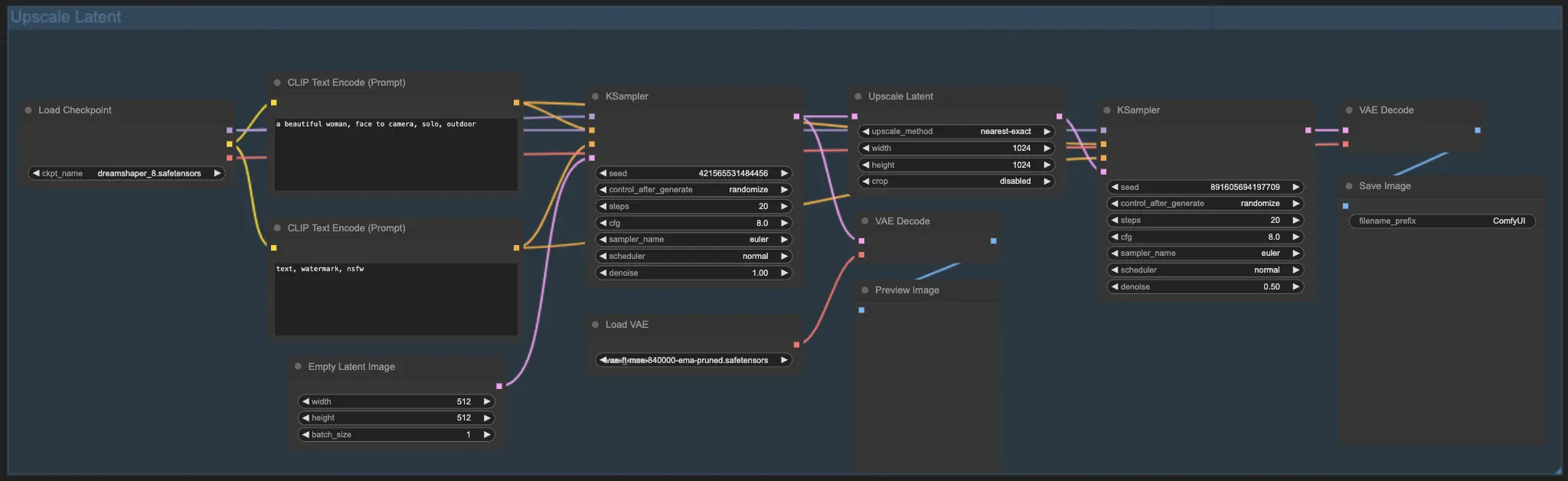
7.2. Upscale Latent ⚙️#
Otro método de upscaling es el Upscale Latent, también conocido como Hi-res Latent Fix Upscale, que amplía directamente en el espacio latente.
7.3. Upscale Pixel vs. Upscale Latent 🆚#
- Upscale Pixel: Solo agranda la imagen sin agregar nueva información. Generación más rápida, pero puede tener un efecto de difuminado y falta de detalles.
- Upscale Latent: Además de agrandar, cambia parte de la información original de la imagen, enriqueciendo los detalles. Puede desviarse de la imagen original y tiene una velocidad de generación más lenta.
Para obtener más flujos de trabajo premium de restauración/ampliación, visita nuestra 🌟Lista de flujos de trabajo de ComfyUI🌟
8. ComfyUI ControlNet 🎮#
¡Prepárate para llevar tu arte de IA al siguiente nivel con ControlNet, una tecnología revolucionaria que transforma la generación de imágenes!
ControlNet es como una varita mágica 🪄 que te otorga un control sin precedentes sobre tus imágenes generadas por IA. ¡Trabaja de la mano con potentes modelos como Stable Diffusion, mejorando sus capacidades y permitiéndote guiar el proceso de creación de imágenes como nunca antes!
Imagina poder especificar los bordes, las poses humanas, la profundidad o incluso los mapas de segmentación de la imagen deseada. 🌠 ¡Con ControlNet, puedes hacer exactamente eso!
Si estás ansioso por sumergirte más en el mundo de ControlNet y liberar todo su potencial, te tenemos cubierto. Consulta nuestro tutorial detallado sobre dominar ControlNet en ComfyUI 📚 Está repleto de guías paso a paso y ejemplos inspiradores para ayudarte a convertirte en un profesional de ControlNet. 🏆
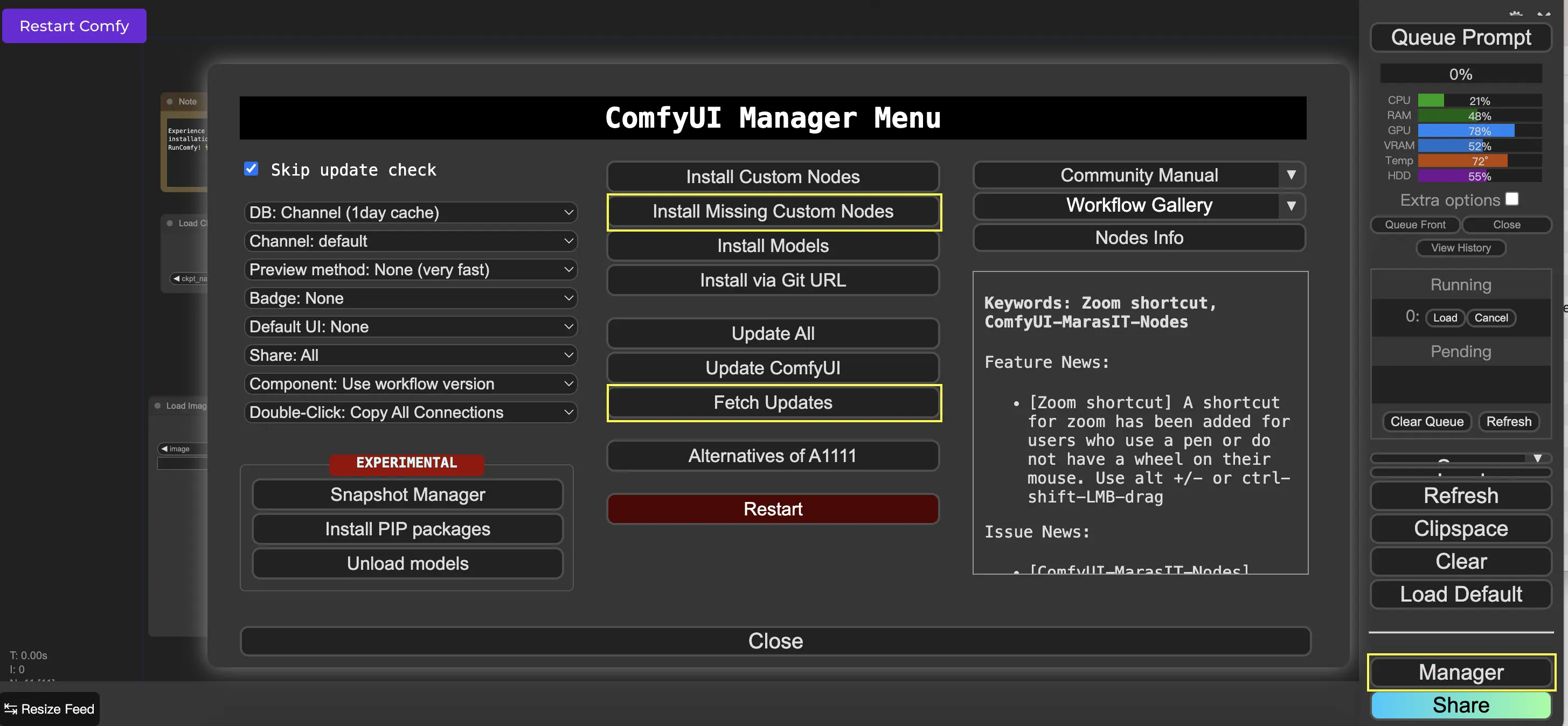
9. Administrador de ComfyUI 🛠️#
El Administrador de ComfyUI es un nodo personalizado que te permite instalar y actualizar otros nodos personalizados a través de la interfaz de ComfyUI. Encontrarás el botón Administrador en el menú Queue Prompt.
9.1. Cómo instalar nodos personalizados faltantes 📥#
Si un flujo de trabajo requiere nodos personalizados que no has instalado, sigue estos pasos:
- Haz clic en Administrador en el menú.
- Haz clic en Instalar nodos personalizados faltantes.
- Reinicia ComfyUI por completo.
- Actualiza el navegador.
9.2. Cómo actualizar nodos personalizados 🔄#
- Haz clic en Administrador en el menú.
- Haz clic en Buscar actualizaciones (puede tardar un rato).
- Haz clic en Instalar nodos personalizados.
- Si hay una actualización disponible, aparecerá un botón Actualizar junto al nodo personalizado instalado.
- Haz clic en Actualizar para actualizar el nodo.
- Reinicia ComfyUI.
- Actualiza el navegador.
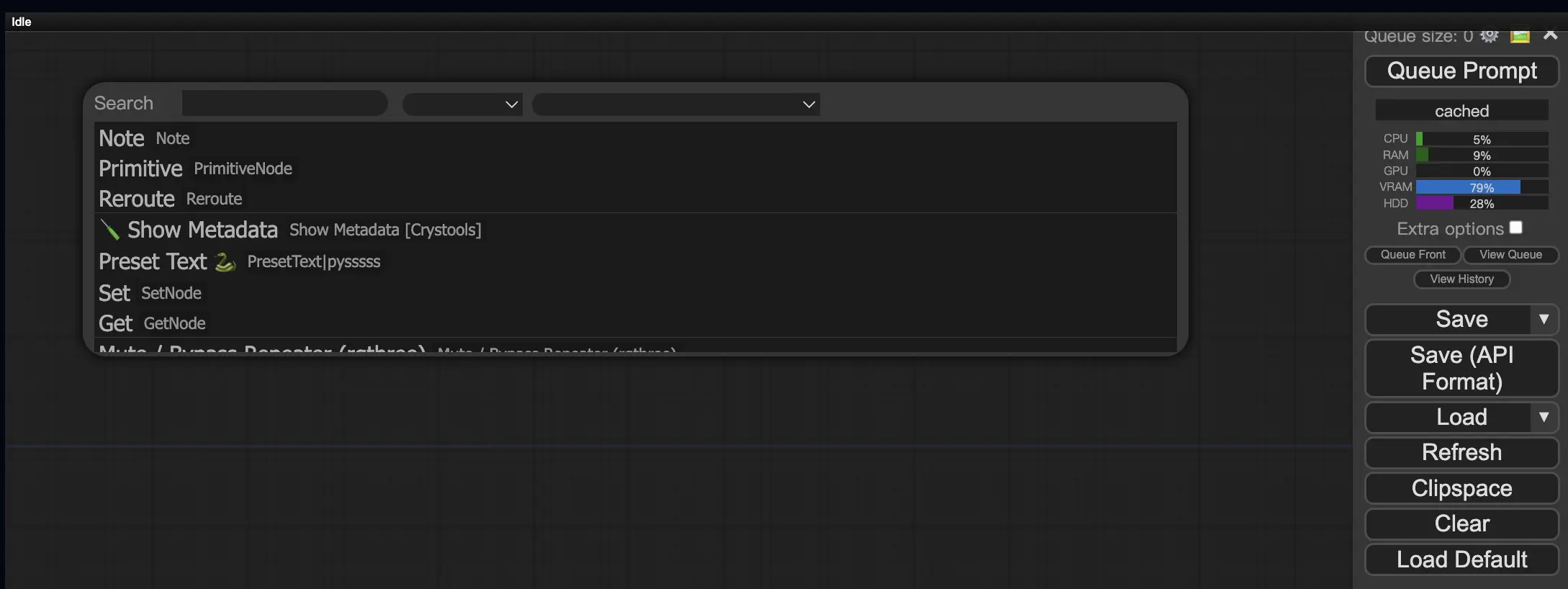
9.3. Cómo cargar nodos personalizados en tu flujo de trabajo 🔍#
Haz doble clic en cualquier área vacía para abrir un menú de búsqueda de nodos.
10. Embeddings de ComfyUI 📝#
Los embeddings, también conocidos como inversión textual, son una poderosa característica de ComfyUI que te permite inyectar conceptos o estilos personalizados en tus imágenes generadas por IA. 💡 Es como enseñarle a la IA una nueva palabra o frase y asociarla con características visuales específicas.
Para usar embeddings en ComfyUI, simplemente escribe "embedding:" seguido del nombre de tu embedding en el cuadro de prompt positivo o negativo. Por ejemplo:
embedding: BadDream
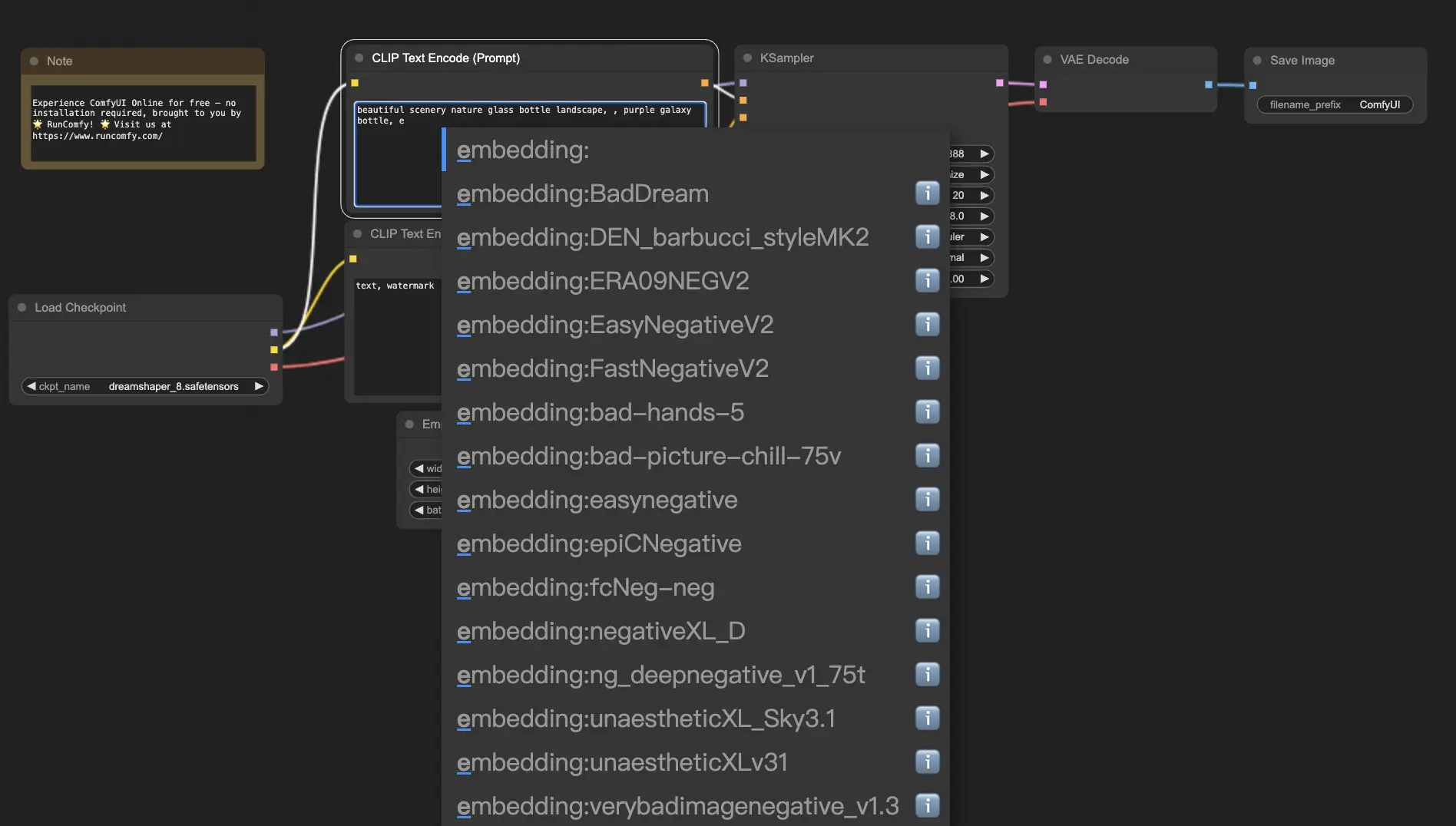
Cuando uses este prompt, ComfyUI buscará un archivo de embedding llamado "BadDream" en la carpeta ComfyUI > models > embeddings. 📂 Si encuentra una coincidencia, aplicará las características visuales correspondientes a tu imagen generada.
Los embeddings son una excelente manera de personalizar tu arte de IA y lograr estilos o estéticas específicas. 🎨 Puedes crear tus propios embeddings entrenándolos en un conjunto de imágenes que representen el concepto o estilo deseado.
10.1. Embedding con autocompletar 🔠#
Recordar los nombres exactos de tus embeddings puede ser una molestia, especialmente si tienes una gran colección. 😅 ¡Ahí es donde el nodo personalizado ComfyUI-Custom-Scripts viene al rescate!
Para habilitar el autocompletado de nombres de embedding:
- Abre el Administrador de ComfyUI haciendo clic en "Administrador" en el menú superior.
- Ve a "Instalar nodos personalizados" y busca "ComfyUI-Custom-Scripts".
- Haz clic en "Instalar" para agregar el nodo personalizado a tu configuración de ComfyUI.
- Reinicia ComfyUI para aplicar los cambios.
Una vez que tengas el nodo ComfyUI-Custom-Scripts instalado, experimentarás una forma más fácil de usar embeddings. 😊 Simplemente comienza a escribir "embedding:" en un cuadro de prompt y aparecerá una lista de embeddings disponibles. Luego puedes seleccionar el embedding deseado de la lista, ¡ahorrándote tiempo y esfuerzo!
10.2. Peso de embedding ⚖️#
¿Sabías que puedes controlar la fuerza de tus embeddings? 💪 Como los embeddings son esencialmente palabras clave, puedes aplicarles pesos como lo harías con palabras clave regulares en tus prompts.
Para ajustar el peso de un embedding, usa la siguiente sintaxis:
(embedding: BadDream:1.2)
En este ejemplo, el peso del embedding "BadDream" se aumenta en un 20%. Entonces, los pesos más altos (por ejemplo, 1.2) harán que el embedding sea más prominente, mientras que los pesos más bajos (por ejemplo, 0.8) reducirán su influencia. 🎚️ ¡Esto te da aún más control sobre el resultado final!
11. ComfyUI LoRA 🧩#
LoRA, abreviatura de Low-rank Adaptation, es otra característica emocionante de ComfyUI que te permite modificar y ajustar tus modelos checkpoint. 🎨 Es como agregar un modelo pequeño y especializado sobre tu modelo base para lograr estilos específicos o incorporar elementos personalizados.
Los modelos LoRA son compactos y eficientes, lo que los hace fáciles de usar y compartir. Se utilizan comúnmente para tareas como modificar el estilo artístico de una imagen o inyectar una persona u objeto específico en el resultado generado.
Cuando aplicas un modelo LoRA a un modelo checkpoint, modifica los componentes MODEL y CLIP mientras deja intacto el VAE (Variational Autoencoder). Esto significa que el LoRA se enfoca en ajustar el contenido y el estilo de la imagen sin alterar su estructura general.
11.1. Cómo usar LoRA 🔧#
Usar LoRA en ComfyUI es sencillo. Echemos un vistazo al método más simple:
- Selecciona un modelo checkpoint que sirva como base para la generación de tu imagen.
- Elige un modelo LoRA que desees aplicar para modificar el estilo o inyectar elementos específicos.
- Revisa los prompts positivos y negativos para guiar el proceso de generación de imágenes.
- Haz clic en "Queue Prompt" para comenzar a generar la imagen con el LoRA aplicado. ▶
ComfyUI combinará el modelo checkpoint y el modelo LoRA para crear una imagen que refleje los prompts especificados e incorpore las modificaciones introducidas por el LoRA.
11.2. Múltiples LoRAs 🧩🧩#
Pero, ¿qué sucede si deseas aplicar múltiples LoRAs a una sola imagen? ¡No hay problema! ComfyUI te permite usar dos o más LoRAs en el mismo flujo de trabajo de texto a imagen.
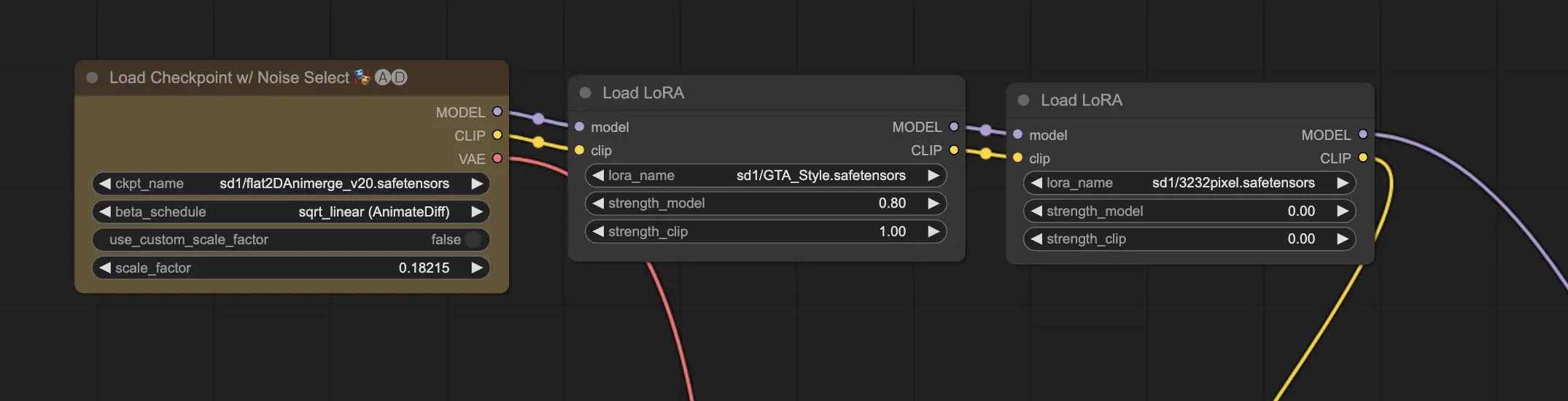
El proceso es similar a usar un solo LoRA, pero deberás seleccionar múltiples modelos LoRA en lugar de solo uno. ComfyUI aplicará los LoRAs secuencialmente, lo que significa que cada LoRA se basará en las modificaciones introducidas por el anterior.
Esto abre un mundo de posibilidades para combinar diferentes estilos, elementos y modificaciones en tus imágenes generadas por IA. 🌍💡 ¡Experimenta con diferentes combinaciones de LoRA para lograr resultados únicos y creativos!
12. Atajos y trucos para ComfyUI ⌨️🖱️#
12.1. Copiar y pegar 📋#
- Selecciona un nodo y presiona Ctrl+C para copiar.
- Presiona Ctrl+V para pegar.
- Presiona Ctrl+Shift+V para pegar con las conexiones de entrada intactas.
12.2. Mover múltiples nodos 🖱️#
- Crea un grupo para mover un conjunto de nodos juntos.
- Alternativamente, mantén presionado Ctrl y arrastra para crear un cuadro para seleccionar varios nodos o mantén presionado Ctrl para seleccionar varios nodos individualmente.
- Para mover los nodos seleccionados, mantén presionado Shift y mueve el mouse.
12.3. Omitir un nodo 🔇#
- Deshabilita temporalmente un nodo silenciándolo. Selecciona un nodo y presiona Ctrl+M.
- No hay un atajo de teclado para silenciar un grupo. Selecciona Bypass Group Node en el menú del botón derecho o silencia el primer nodo del grupo para deshabilitarlo.
12.4. Minimizar un nodo 🔍#
- Haz clic en el punto de la esquina superior izquierda del nodo para minimizarlo.
12.5. Generar imagen ▶️#
- Presiona Ctrl+Enter para poner el flujo de trabajo en la cola y generar imágenes.
12.6. Flujo de trabajo incrustado 🖼️#
- ComfyUI guarda el flujo de trabajo completo en los metadatos del archivo PNG que genera. Para cargar el flujo de trabajo, arrastra y suelta la imagen en ComfyUI.
12.7. Fijar semillas para ahorrar tiempo ⏰#
- ComfyUI solo vuelve a ejecutar un nodo si la entrada cambia. Al trabajar en una larga cadena de nodos, ahorra tiempo fijando la semilla para evitar regenerar resultados anteriores.
13. ComfyUI en línea 🚀#
¡Felicidades por completar esta guía para principiantes de ComfyUI! 🙌 Ahora estás listo para sumergirte en el emocionante mundo de la creación de arte con IA. Pero, ¿por qué molestarse con la instalación cuando puedes comenzar a crear de inmediato? 🤔
En RunComfy, hemos hecho que sea simple para ti usar ComfyUI en línea sin ninguna configuración. Nuestro servicio ComfyUI Online viene precargado con más de 200 nodos y modelos populares, junto con más de 50 flujos de trabajo impresionantes para inspirar tus creaciones.
🌟 Ya seas un principiante o un artista de IA experimentado, RunComfy tiene todo lo que necesitas para dar vida a tus visiones artísticas. 💡 No esperes más: prueba ComfyUI Online ahora y experimenta el poder de la creación de arte con IA al alcance de tus manos! 🚀