
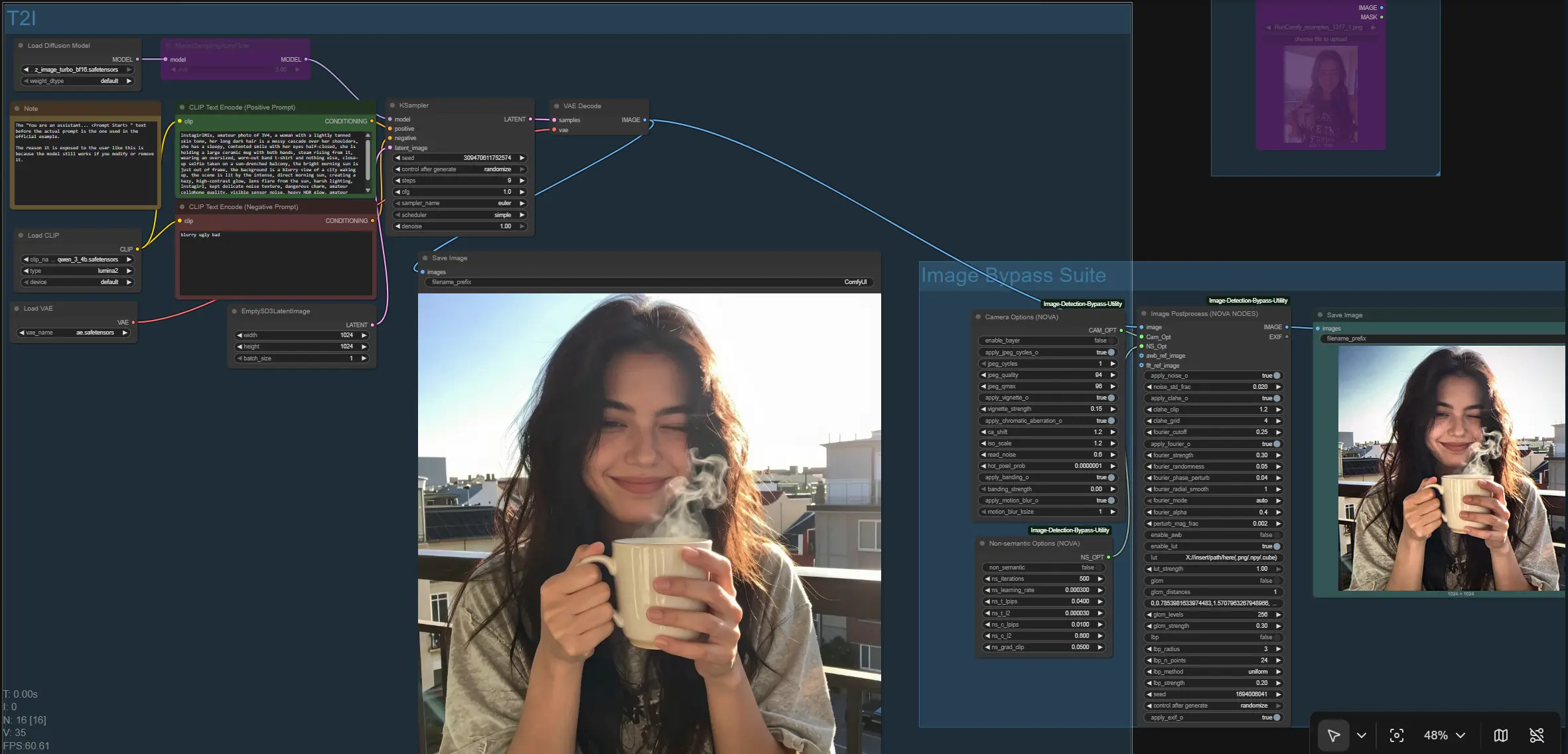







ComfyUI Image Bypass Workflow#
Dieser Workflow bietet eine modulare Image Bypass-Pipeline für ComfyUI, die nicht-semantische Normalisierung, FFT-Domänenkontrollen und Kamerapipelinesimulation kombiniert. Er ist für Kreative und Forscher konzipiert, die einen zuverlässigen Weg benötigen, um Bilder durch eine Image Bypass-Stufe zu verarbeiten, während sie die volle Kontrolle über Eingaberouting, Vorverhalten und Konsistenz der Ausgaben behalten.
Im Kern erzeugt oder erfasst der Graph ein Bild und leitet es dann durch eine Image Bypass Suite, die sensorähnliche Artefakte, Frequenzformung, Texturanpassung und einen perzeptuellen Optimierer anwenden kann. Das Ergebnis ist ein sauberer, konfigurierbarer Pfad, der Batch-Arbeit, Automatisierung und schnelle Iteration auf Consumer-GPUs unterstützt. Die Image Bypass-Logik wird durch das Open-Source-Dienstprogramm aus diesem Repository betrieben: PurinNyova/Image-Detection-Bypass-Utility.
Wichtige Modelle im Comfyui Image Bypass-Workflow#
- z_image_turbo_bf16 (UNet-Checkpoint). Ein schnelles Text-zu-Bild-Diffusions-Backbone, das im T2I-Zweig für schnelles Prototyping und Baseline-Bilderzeugung verwendet wird. Es kann durch Ihren bevorzugten Checkpoint ersetzt werden. Referenz: Comfy-Org/z_image_turbo auf Hugging Face.
- VAE (ae.safetensors). Handhabt die latente Dekodierung zurück zu Pixeln, sodass die Ausgabe der Abtastung visualisiert und weiter von der Image Bypass-Stufe verarbeitet werden kann. Jedes kompatible VAE kann ausgetauscht werden, wenn Sie ein anderes Rekonstruktionsprofil bevorzugen.
- Prompt-Encoder (geladen über CLIPLoader). Kodiert Ihre positiven und negativen Eingaben in Vektoren zur Konditionierung für den Sampler. Der Graph ist gegenüber der spezifischen Text-Encoder-Datei, die Sie laden, agnostisch, sodass Sie Modelle nach Bedarf für Ihren Basisgenerator austauschen können.
So verwenden Sie den Comfyui Image Bypass-Workflow#
Auf hoher Ebene bietet der Workflow zwei Möglichkeiten, das Bild zu erzeugen, das in die Image Bypass Suite eintritt: einen Text-zu-Bild-Zweig (T2I) und einen Bild-zu-Bild-Zweig (I2I). Beide konvergieren auf einen einzigen Verarbeitungsknoten, der die Image Bypass-Logik anwendet und das Endergebnis auf die Festplatte schreibt. Der Graph speichert auch die Vor-Bypass-Basislinie, damit Sie Ausgaben vergleichen können.
Gruppe: T2I#
Verwenden Sie diesen Pfad, wenn Sie ein neues Bild aus Eingaben synthetisieren möchten. Ihr Prompt-Encoder wird von CLIPLoader (#164) geladen und von CLIP Text Encode (Positive Prompt) (#168) und CLIP Text Encode (Negative Prompt) (#163) gelesen. Der UNet wird mit UNETLoader (#165) geladen, optional gepatcht von ModelSamplingAuraFlow (#166), um das Abtastverhalten des Modells anzupassen, und dann mit KSampler (#167) abgetastet, beginnend mit EmptySD3LatentImage (#162). Das dekodierte Bild kommt aus VAEDecode (#158) und wird als Basislinie über SaveImage (#159) gespeichert, bevor es in die Image Bypass Suite eintritt. Für diesen Zweig sind Ihre primären Eingaben die positiven/negativen Eingaben und, falls gewünscht, die Seed-Strategie in KSampler (#167).
Gruppe: I2I#
Wählen Sie diesen Pfad, wenn Sie bereits ein Bild zur Verarbeitung haben. Laden Sie es über LoadImage (#157) und leiten Sie die IMAGE-Ausgabe zum Eingang der Image Bypass Suite auf NovaNodes (#146). Dies umgeht die Textkonditionierung und Abtastung vollständig. Es ist ideal für Batch-Nachverarbeitung, Experimente mit bestehenden Datensätzen oder die Standardisierung von Ausgaben aus anderen Workflows. Sie können frei zwischen T2I und I2I wechseln, je nachdem, ob Sie generieren oder strikt transformieren möchten.
Gruppe: Image Bypass Suite#
Dies ist das Herz des Graphen. Der zentrale Prozessor NovaNodes (#146) empfängt das eingehende Bild und zwei Optionsblöcke: CameraOptionsNode (#145) und NSOptionsNode (#144). Der Knoten kann in einem optimierten Automatikmodus oder einem manuellen Modus betrieben werden, der Kontrollen für Frequenzformung (FFT-Glättung/Anpassung), Pixel- und Phasenstörungen, lokalen Kontrast und Tonbearbeitung, optionale 3D-LUTs und Texturstatistikanpassung freilegt. Zwei optionale Eingaben ermöglichen es Ihnen, einen automatischen Weißabgleichreferenz und ein FFT-/Texturreferenzbild anzuschließen, um die Normalisierung zu leiten. Das endgültige Image Bypass-Ergebnis wird von SaveImage (#147) geschrieben und gibt Ihnen sowohl die Basislinie als auch die verarbeitete Ausgabe für eine Nebeneinanderbewertung.
Wichtige Knoten im Comfyui Image Bypass-Workflow#
NovaNodes (#146)#
Der Kernprozessor des Image Bypass. Er orchestriert Frequenzdomänenformung, räumliche Störungen, lokale Tonsteuerung, LUT-Anwendung und optionale Texturanpassung. Wenn Sie ein awb_ref_image oder fft_ref_image bereitstellen, wird er diese Referenzen frühzeitig in der Pipeline verwenden, um Farb- und Spektralanpassung zu leiten. Beginnen Sie im Automatikmodus, um eine sinnvolle Basislinie zu erhalten, und wechseln Sie dann manuell, um die Effektstärke fein abzustimmen und für Ihre Inhalte und nachgelagerten Aufgaben zu mischen. Für konsistente Vergleiche setzen und wiederverwenden Sie einen Seed; für Erkundungen randomisieren Sie, um Mikrovariationen zu diversifizieren.
NSOptionsNode (#144)#
Steuert den nicht-semantischen Optimierer, der Pixel verschiebt, während er die perzeptuelle Ähnlichkeit bewahrt. Er legt Iterationsanzahl, Lernrate und perzeptuelle/Regulierungsgewichte (LPIPS und L2) zusammen mit dem Gradienten-Clipping offen. Verwenden Sie ihn, wenn Sie subtile Verteilungsshifts mit minimal sichtbaren Artefakten benötigen; halten Sie Änderungen konservativ, um natürliche Texturen und Kanten zu bewahren. Deaktivieren Sie ihn vollständig, um zu messen, wie viel die Image Bypass-Pipeline ohne Optimierer hilft.
CameraOptionsNode (#145)#
Simuliert Sensor- und Linseneigenschaften wie Demosaic- und JPEG-Zyklen, Vignettierung, chromatische Aberration, Bewegungsunschärfe, Banding und Ausleserauschen. Behandeln Sie es als eine Realismusschicht, die plausible Erfassungsartefakte zu Ihren Bildern hinzufügen kann. Aktivieren Sie nur die Komponenten, die Ihren Zielaufnahmebedingungen entsprechen; das Stapeln zu vieler kann das Aussehen übermäßig einschränken. Für reproduzierbare Ausgaben halten Sie die gleichen Kameraoptionen bei, während Sie andere Parameter variieren.
ModelSamplingAuraFlow (#166)#
Patcht das Abtastverhalten des geladenen Modells, bevor es KSampler (#167) erreicht. Dies ist nützlich, wenn Ihr gewähltes Backbone von einer alternativen Schrittbahn profitiert. Passen Sie es an, wenn Sie eine Diskrepanz zwischen Eingabeabsicht und Probenstruktur bemerken, und behandeln Sie es in Verbindung mit Ihren Sampler- und Scheduler-Wahlen.
KSampler (#167)#
Führt Diffusionsabtastung durch, gegeben das Modell, positive und negative Konditionierung und das Startlatente. Die Schlüsselhebel sind Seed-Strategie, Schritte, Samplertyp und die Gesamtentstärkungsstärke. Niedrigere Schritte helfen bei der Geschwindigkeit, während höhere Schritte die Struktur stabilisieren können, wenn Ihr Basismodell dies erfordert. Halten Sie das Verhalten dieses Knotens stabil, während Sie an den Image Bypass-Einstellungen iterieren, damit Sie Änderungen dem Nachbearbeitungsprozess und nicht dem Generator zuschreiben können.
Optionale Extras#
- Modelle frei austauschen. Die Image Bypass Suite ist modellagnostisch; Sie können
z_image_turbo_bf16ersetzen und trotzdem Ergebnisse durch denselben Verarbeitungsstapel leiten. - Nutzen Sie Referenzen bedacht. Stellen Sie
awb_ref_imageundfft_ref_imagebereit, die Beleuchtungs- und Inhaltsmerkmale mit Ihrer Zieldomäne teilen; nicht übereinstimmende Referenzen können den Realismus verringern. - Fair vergleichen. Halten Sie
SaveImage(#159) als Basislinie undSaveImage(#147) als Image Bypass-Ausgabe, damit Sie Einstellungen A/B-testen und Verbesserungen verfolgen können. - Batch mit Bedacht. Erhöhen Sie die Batchgröße von
EmptySD3LatentImage(#162) nur, soweit es der VRAM erlaubt, und bevorzugen Sie feste Seeds, wenn Sie kleine Parameteränderungen messen. - Lernen Sie das Dienstprogramm. Für Funktionsdetails und laufende Updates zu den Image Bypass-Komponenten siehe das Upstream-Projekt: PurinNyova/Image-Detection-Bypass-Utility.
Credits#
- ComfyUI, die Graph-Engine, die von diesem Workflow verwendet wird: comfyanonymous/ComfyUI.
- Beispiel-Basis-Checkpoint: Comfy-Org/z_image_turbo.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken PurinNyova für Image-Detection-Bypass-Utility für ihre Beiträge und Wartung. Für autoritative Details verweisen Sie bitte auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- PurinNyova/Image-Detection-Bypass-Utility
- GitHub: PurinNyova/Image-Detection-Bypass-Utility
- Docs / Release Notes: Repository (tree/main)
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreibern bereitgestellt werden.
