
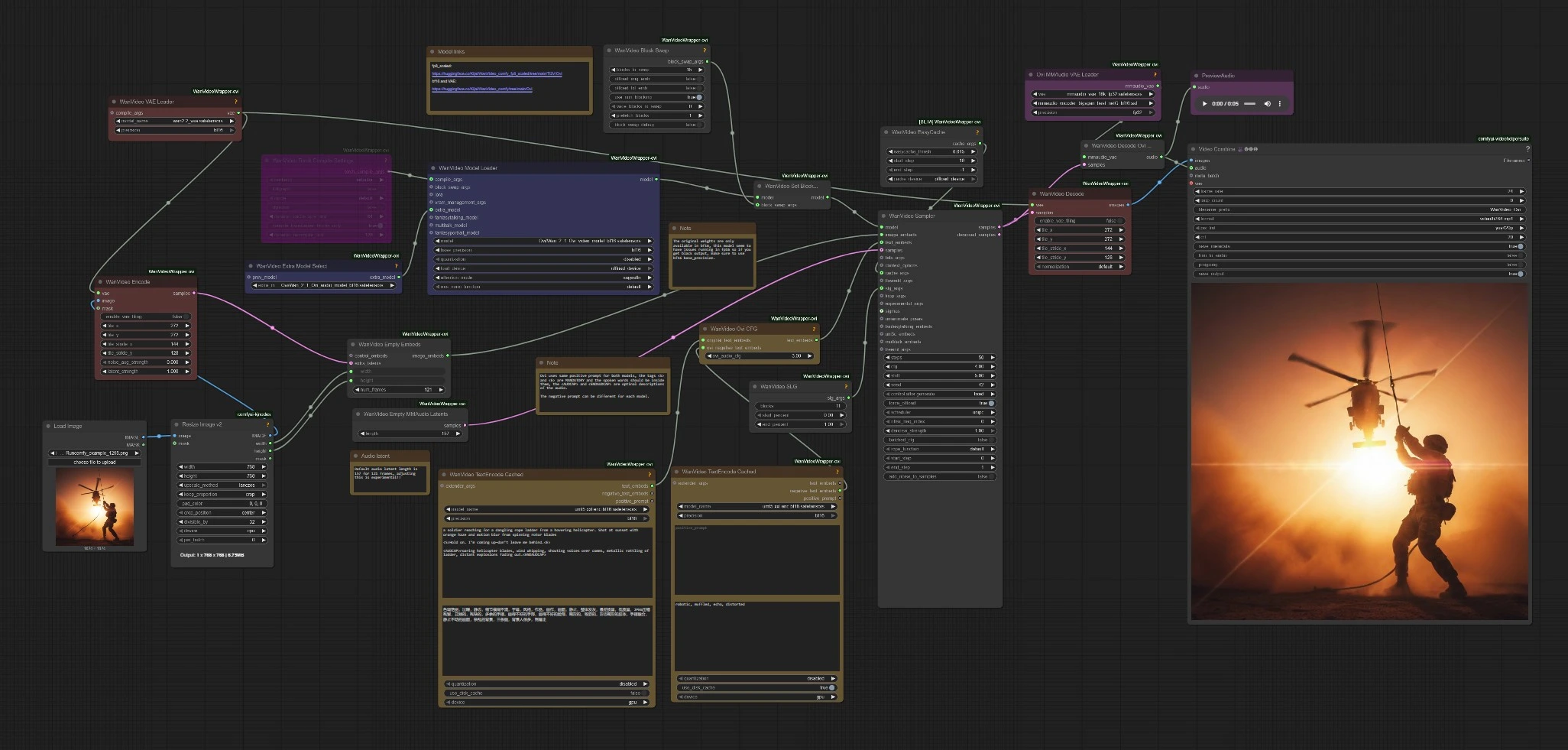
Character AI Ovi: Bild zu Video mit synchronisierter Sprache in ComfyUI#
Character AI Ovi ist ein audiovisueller Generations-Workflow, der ein einzelnes Bild in einen sprechenden, sich bewegenden Charakter mit koordiniertem Klang verwandelt. Basierend auf der Wan-Modellfamilie und integriert durch den WanVideoWrapper, generiert es Video und Audio in einem Durchgang und liefert ausdrucksstarke Animationen, verständlichen Lippen-Sync und kontextsensitives Ambiente. Wenn Sie Kurzgeschichten, virtuelle Hosts oder filmische soziale Clips erstellen, ermöglicht Ihnen Character AI Ovi, von statischer Kunst zu einer vollständigen Performance in Minuten zu gelangen.
Dieser ComfyUI-Workflow akzeptiert ein Bild plus ein Text-Prompt, das leichtes Markup für Sprache und Sounddesign enthält. Es komponiert Frames und Wellenform zusammen, sodass Mund, Kadenz und Szenenaudio natürlich ausgerichtet erscheinen. Character AI Ovi ist für Kreative konzipiert, die polierte Ergebnisse ohne das Zusammensetzen separater TTS- und Videotools wünschen.
Wichtige Modelle im ComfyUI Character AI Ovi-Workflow#
- Ovi: Twin Backbone Cross-Modal Fusion für Audio-Video-Generierung. Das Kernmodell, das gemeinsam Video und Audio aus Text- oder Text+Bild-Prompts produziert. character-ai/Ovi
- Wan 2.2 Video-Backbone und VAE. Der Workflow nutzt Wan’s hochkomprimierende Video-VAE für effiziente 720p, 24 fps-Generierung bei gleichzeitiger Wahrung von Detail und zeitlicher Kohärenz. Wan-AI/Wan2.2-TI2V-5B-Diffusers • Wan-Video/Wan2.2
- Google UMT5-XXL Text-Encoder. Kodiert das Prompt, einschließlich Sprach-Tags, in reichhaltige mehrsprachige Embeddings, die beide Zweige antreiben. google/umt5-xxl
- MMAudio VAE mit BigVGAN Vocoder. Dekodiert die Audio-Latenten des Modells zu hochwertiger Sprache und Effekten mit natürlichem Timbre. hkchengrex/MMAudio • nvidia/bigvgan_v2_44khz_128band_512x
- ComfyUI-bereite Ovi-Gewichte von Kijai. Kuratierte Checkpoints für den Videozweig, den Audiozweig und VAE in bf16- und fp8-skalierten Varianten. Kijai/WanVideo_comfy/Ovi • Kijai/WanVideo_comfy_fp8_scaled/TI2V/Ovi
- WanVideoWrapper-Knoten für ComfyUI. Wrapper, der Wan- und Ovi-Funktionen als komponierbare Knoten freilegt. kijai/ComfyUI-WanVideoWrapper
So verwenden Sie den ComfyUI Character AI Ovi-Workflow#
Dieser Workflow folgt einem einfachen Pfad: Kodieren Sie Ihr Prompt und Bild, laden Sie die Ovi-Checkpoints, sampeln Sie gemeinsame Audio+Video-Latenten, dann dekodieren und muxen Sie zu MP4. Die Unterabschnitte unten entsprechen den sichtbaren Knotenclustern, sodass Sie wissen, wo Sie interagieren und welche Änderungen die Ergebnisse beeinflussen.
Prompt-Erstellung für Sprache und Sound#
Schreiben Sie ein positives Prompt für die Szene und die gesprochene Zeile. Verwenden Sie die Ovi-Tags genau wie gezeigt: Umschließen Sie zu sprechende Wörter mit <S> und <E>, und beschreiben Sie optional nicht-sprachliche Audios mit <AUDCAP> und <ENDAUDCAP>. Das gleiche positive Prompt bedingt sowohl den Video- als auch den Audiozweig, sodass Lippenbewegung und Timing übereinstimmen. Sie können unterschiedliche negative Prompts für Video und Audio verwenden, um Artefakte unabhängig zu unterdrücken. Character AI Ovi reagiert gut auf prägnante Regieanweisungen plus eine einzelne, klare Dialogzeile.
Bildaufnahme und Konditionierung#
Laden Sie ein einzelnes Porträt- oder Charakterbild, dann wird der Workflow es in Latenten kodieren und anpassen. Dies etabliert Identität, Pose und initiale Einrahmung für den Sampler. Breite und Höhe des Anpassungsstadiums bestimmen das Videoformat; wählen Sie quadratisch für Avatare oder vertikal für Kurzfilme. Die kodierten Latenten und Bild-abgeleiteten Embeds leiten den Sampler, sodass Bewegung an das ursprüngliche Gesicht gebunden erscheint.
Modell-Laden und Leistungshelfer#
Character AI Ovi lädt drei wesentliche Elemente: das Ovi-Videomodell, das Wan 2.2 VAE für Frames und das MMAudio VAE plus BigVGAN für Audio. Torch compile und ein leichter Cache sind enthalten, um warme Starts zu beschleunigen. Ein Block-Swap-Helfer ist eingebunden, um den VRAM-Verbrauch zu senken, indem Transformatorblöcke bei Bedarf ausgelagert werden. Wenn Sie VRAM-begrenzt sind, erhöhen Sie den Blockauslagerungsgrad im Block-Swap-Knoten und halten Sie den Cache für wiederholte Durchläufe aktiviert.
Gemeinsames Sampling mit Führung#
Der Sampler betreibt Ovis Doppelrückgrat zusammen, sodass Soundtrack und Frames gemeinsam entstehen. Ein Skip-Layer-Führungshelfer verbessert Stabilität und Detail ohne Bewegungsverlust. Der Workflow leitet Ihre ursprünglichen Text-Embeddings auch durch einen Ovi-spezifischen CFG-Mixer, sodass Sie das Gleichgewicht zwischen strikter Prompt-Einhaltung und freierer Animation neigen können. Character AI Ovi neigt dazu, die beste Lippenbewegung zu erzeugen, wenn die gesprochene Zeile kurz, wörtlich und nur von den <S> und <E>-Tags umschlossen ist.
Dekodieren, Vorschau und Export#
Nach dem Sampling dekodieren Videolatenten durch das Wan VAE, während Audiolatenten durch MMAudio mit BigVGAN dekodiert werden. Ein Videokombinator muxed Frames und Audio in eine MP4 bei 24 fps, bereit zum Teilen. Sie können auch Audio direkt vorschauen, um die Verständlichkeit der Sprache vor dem Speichern zu überprüfen. Der Standardpfad von Character AI Ovi zielt auf 5 Sekunden; erweitern Sie vorsichtig, um Lippen und Kadenz synchron zu halten.
Wichtige Knoten im ComfyUI Character AI Ovi-Workflow#
WanVideoTextEncodeCached(#85)
Kodiert das Haupt-positive Prompt und das Video-negative Prompt in Embeddings, die von beiden Zweigen verwendet werden. Halten Sie den Dialog innerhalb von <S>…<E> und platzieren Sie das Sounddesign innerhalb von <AUDCAP>…<ENDAUDCAP>. Für die beste Ausrichtung vermeiden Sie mehrere Sätze in einem Sprach-Tag und halten Sie die Zeile prägnant.
WanVideoTextEncodeCached(#96)
Bietet ein dediziertes negatives Text-Embedding für Audio. Verwenden Sie es, um Artefakte wie robotischen Ton oder starke Nachhall ohne Beeinflussung der visuellen Elemente zu unterdrücken. Beginnen Sie mit kurzen Beschreibungen und erweitern Sie nur, wenn Sie das Problem weiterhin hören.
WanVideoOviCFG(#94)
Vermischt die ursprünglichen Text-Embeddings mit den audio-spezifischen Negativen durch eine Ovi-bewusste classifier-free guidance. Erhöhen Sie es, wenn der Sprachinhalt von der geschriebenen Zeile abweicht oder die Lippenbewegungen ungenau erscheinen. Senken Sie es leicht, wenn die Bewegung steif oder übermäßig eingeschränkt wird.
WanVideoSampler(#80)
Das Herzstück von Character AI Ovi. Es konsumiert Bild-Embeds, gemeinsame Text-Embeds und optionale Führung, um ein einzelnes Latent zu sampeln, das sowohl Video als auch Audio enthält. Mehr Schritte erhöhen die Treue, aber auch die Laufzeit. Wenn Sie Speicherprobleme oder Verzögerungen bemerken, kombinieren Sie eine höhere Blockauslagerung mit aktiviertem Cache und erwägen Sie das Deaktivieren von Torch Compile für schnelle Fehlersuche.
WanVideoEmptyMMAudioLatents(#125)
Initialisiert die Audio-Latent-Zeitleiste. Die Standardlänge ist auf einen 121-Frame, 24 fps Clip abgestimmt. Das Anpassen dieser Länge zur Änderung der Dauer ist experimentell; ändern Sie es nur, wenn Sie verstehen, wie es die Frame-Anzahl nachverfolgen muss.
VHS_VideoCombine(#88)
Muxed dekodierte Frames und Audio zu MP4. Stellen Sie die Bildrate ein, um Ihr Samplingziel zu erreichen, und aktivieren Sie "trim-to-audio", wenn Sie möchten, dass der endgültige Schnitt der generierten Wellenform folgt. Verwenden Sie die CRF-Steuerung, um Dateigröße und Qualität auszugleichen.
Optionale Extras#
- Verwenden Sie bf16 für Ovi-Video und Wan 2.2 VAE. Wenn Sie schwarze Frames sehen, wechseln Sie die Basispräzision zu
bf16für die Modelllader und den Text-Encoder. - Halten Sie Reden kurz. Character AI Ovi synchronisiert Lippen am zuverlässigsten mit kurzen, einzeiligen Dialogen innerhalb von
<S>und<E>. - Separate Negative. Platzieren Sie visuelle Artefakte im Video-negativen Prompt und tonale Artefakte im Audio-negativen Prompt, um unbeabsichtigte Kompromisse zu vermeiden.
- Vorschau zuerst. Verwenden Sie die Audiovorschau, um Klarheit und Timing zu bestätigen, bevor Sie das endgültige MP4 exportieren.
- Holen Sie sich die genauen verwendeten Gewichte. Der Workflow erwartet Ovi-Video- und Audio-Checkpoints plus das Wan 2.2 VAE von Kijai’s Modellspiegeln. WanVideo_comfy/Ovi • WanVideo_comfy_fp8_scaled/TI2V/Ovi
Mit diesen Elementen wird Character AI Ovi zu einem kompakten, benutzerfreundlichen Pipeline für ausdrucksstarke sprechende Avatare und narrative Szenen, die ebenso gut klingen wie sie aussehen.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken kijai und Character AI für Ovi für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die ursprüngliche Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- Character AI Ovi Quelle
- Workflow: wanvideo_2_2_5B_ovi_testing @kijai
- Github: character-ai/Ovi
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Betreuer.
