
Hunyuan Video 是一個創新的開源影片基礎模型,提供的影片生成性能與頂級閉源模型相當甚至更好,由領先的科技公司騰訊開發。Hunyuan Video採用尖端技術進行模型學習,如數據策劃、圖像-影片聯合模型訓練,以及用於大規模模型訓練和推理的高效基礎設施。Hunyuan Video擁有超過130億參數的最大開源影片生成模型。
Hunyuan Video的主要特點包括#
- Hunyuan Video 提供了一種統一的架構來生成圖像和影片。它使用了一種稱為 "雙流到單流" 的特殊Transformer模型設計。這意味著模型首先單獨處理影片和文本信息,然後將它們結合在一起以創建最終輸出。這有助於模型更好地理解視覺和文本描述之間的關係。
- Hunyuan Video中的文本編碼器基於多模態大語言模型 (MLLM)。與其他流行的文本編碼器如CLIP和T5-XXL相比,MLLM更善於將文本與圖像對齊。它還可以提供更詳細的內容描述和推理。這幫助Hunyuan Video生成與輸入文本更準確匹配的影片。
- 為了高效處理高解析度和高幀率影片,Hunyuan Video使用了一個3D變分自編碼器 (VAE) 與CausalConv3D。這個組件將影片和圖像壓縮成一個稱為潛在空間的較小表示。在這個壓縮空間中工作,使Hunyuan Video能在不使用過多計算資源的情況下,訓練和生成其原始解析度和幀率的影片。
- Hunyuan Video包括一個提示重寫模型,可以自動調整用戶的輸入文本以更好地適應模型的偏好。有兩種模式可用:普通模式和大師模式。普通模式專注於提高模型對用戶指令的理解,而大師模式則強調創建具有更高視覺質量的影片。然而,大師模式有時可能會忽略文本中的某些細節,以便使影片看起來更好。
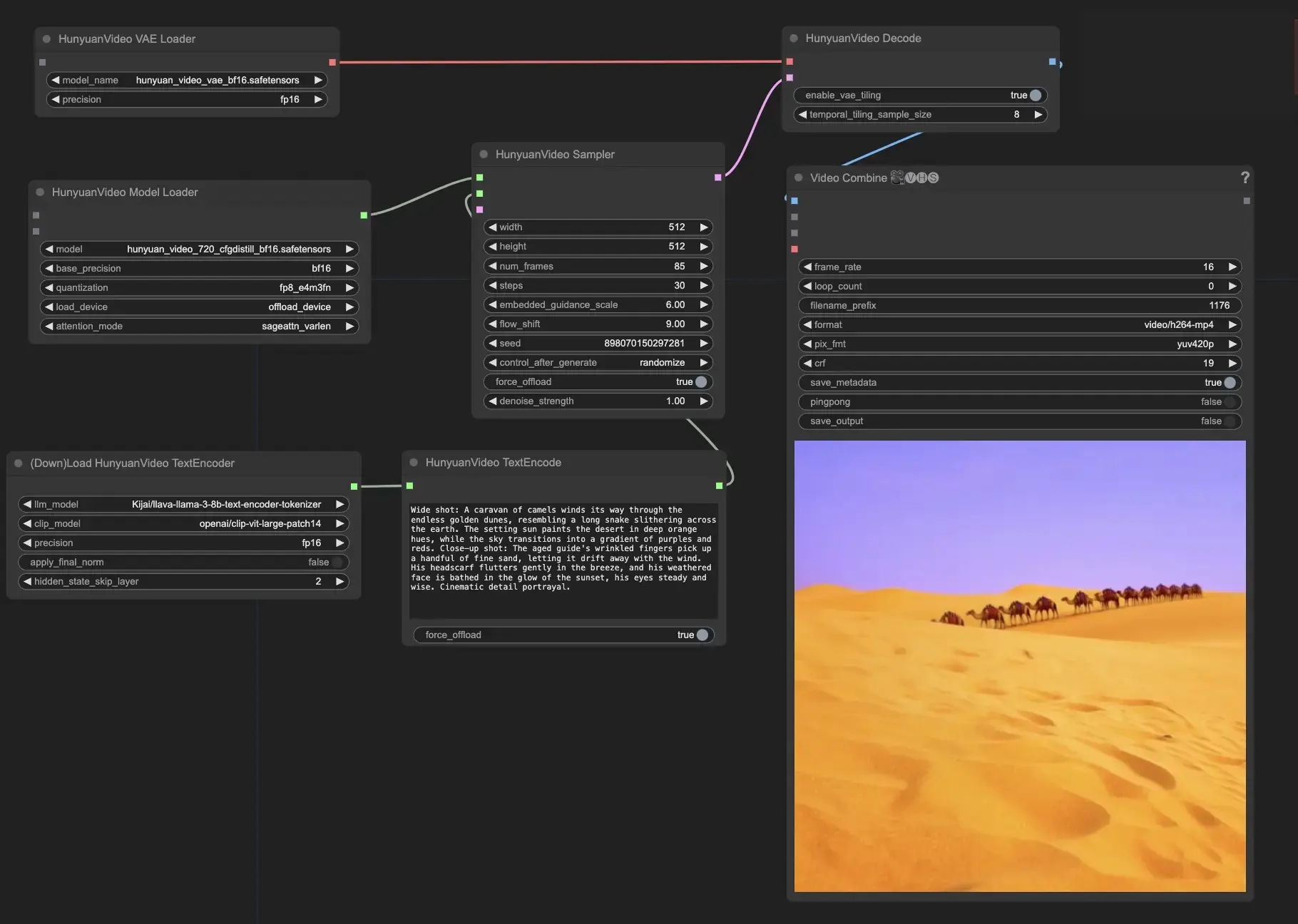
在ComfyUI中使用Hunyuan Video#
這些 ComfyUI-HunyuanVideoWrapper 節點和相關工作流程由Kijai開發。我們對Kijai的這一創新工作表示感謝。在RunComfy平台上,我們只是向社群展示他的貢獻。
- 提供您的文本提示:在HunyuanVideoTextEncode節點中,在 "prompt" 欄位輸入您想要的文本提示。這裡 有一些提示範例供您參考。
- 在HunyuanVideoSampler節點中配置輸出影片設置:
- 將 "width" 和 "height" 設置為您偏好的解析度
- 將 "num_frames" 設置為所需的影片長度(以幀為單位)
- "steps" 控制去噪/取樣步驟的數量(預設:30)
- "embedded_guidance_scale" 決定提示指導的強度(預設:6.0)
- "flow_shift" 影響影片長度(值越大,影片越短,預設:9.0)