






Flux Kontext Zoom Out LoRA | ComfyUI 工作流程#
這個 ComfyUI 工作流程通過擴展畫布並自然地延續場景,同時保持主體的位置和外觀,創建任何輸入圖像的乾淨放大視圖。它圍繞 Flux Kontext 和專門構建的 LoRA 構建,因此您可以在不扭曲面部、紋理或透視的情況下"拉遠相機"。如果您想要一種快速可靠的方法來擴大縮略圖、產品照片、肖像或電影靜止圖像的框架,那麼這個 Flux Kontext Zoom Out LoRA 工作流程就是為您準備的。
在其核心,圖形加載 Flux Kontext UNet,應用 Flux Kontext Zoom Out LoRA,將您的圖像編碼為參考潛在變量,並通過專為放大完整性設計的提示取樣更寬的構圖。結果是無縫擴展,匹配原始光線、風格和幾何。
Comfyui Flux Kontext Zoom Out LoRA 工作流程中的關鍵模型#
- Flux 1 Kontext UNet。這裡使用的擴散骨幹是一個為 ComfyUI 準備的 Kontext 感知的 Flux 1 變體(
flux1-dev-kontext_fp8_scaled.safetensors)。它捕捉現實主義擴展所需的長距結構和場景佈局。模型包:Comfy-Org/flux1-kontext-dev_ComfyUI。 - Flux Kontext Zoom Out LoRA。一個輕量級適配器,使模型能夠在保持可見主體不變的情況下,說服性地擴展邊界。倉庫:reverentelusarca/flux-kontext-zoom-out-lora。
- Flux 的雙文本編碼器。該圖形使用調整為 Flux 的 CLIP-L 和 T5-XXL 編碼器,以高保真度解釋提示。文本編碼器:comfyanonymous/flux_text_encoders。
- AE VAE。用於編碼/解碼步驟的快速高質量自編碼器(
ae.safetensors)。來源:Comfy-Org/Lumina_Image_2.0_Repackaged。
如何使用 Comfyui Flux Kontext Zoom Out LoRA 工作流程#
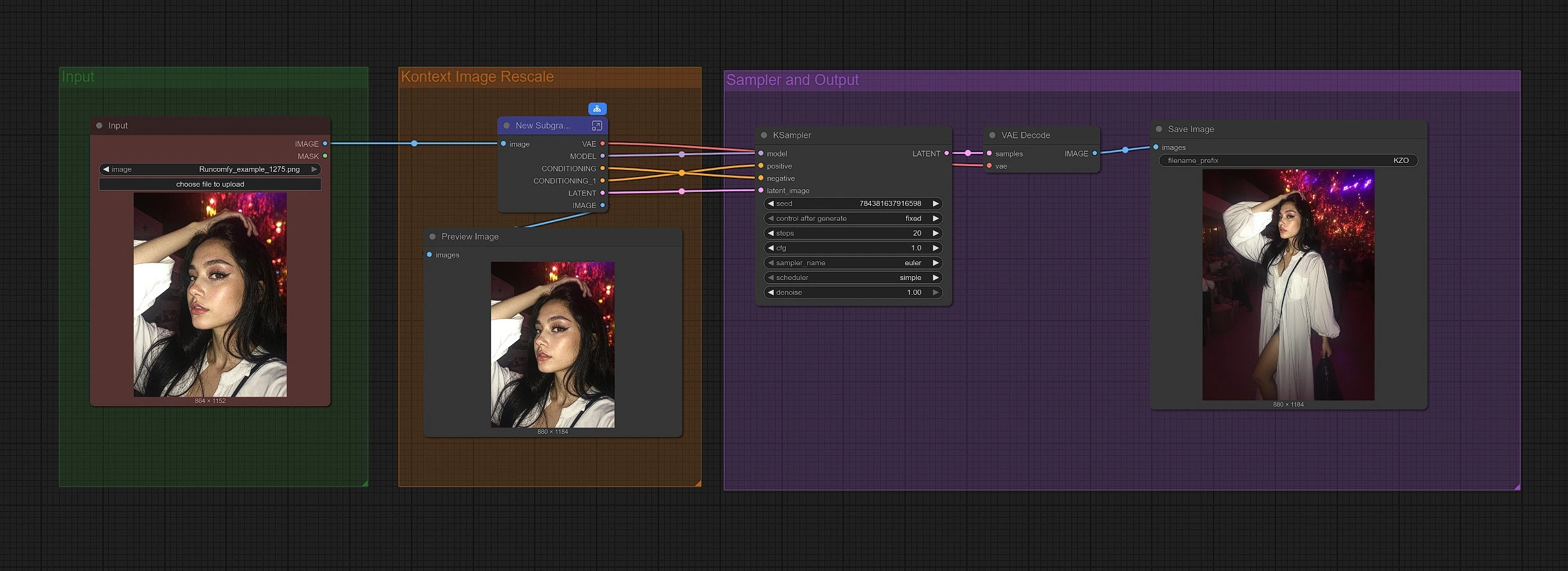
此工作流程分為三個組。首先加載您的圖像,然後圖形將其重新縮放以進行 Kontext 放大,最後取樣重建更寬的框架並保存結果。
組:輸入#
通過 LoadImage (#190) 加載您的源圖像。CLIP Text Encode (Positive Prompt) (#6) 中的默認正面提示旨在保持主體並均勻地向所有方向擴展畫布。您可以保持該提示以獲得忠實的放大效果,或輕微調整以適應您的場景風格。DualCLIPLoader (#38) 已預先連接 CLIP-L 和 T5-XXL,因此文本條件開箱即用。
組:Kontext 圖像重縮放#
FluxKontextImageScale (#42) 通過調整大小和填充準備圖像進行放大,使 Kontext 模型能夠優雅地處理。這個分級步驟幫助模型理解擴展內容的位置以及如何保持透視和光線一致。然後,縮放的圖像由 VAEEncode (#124) 編碼,以便取樣器從仍然“記得”原始框架的潛在變量中工作。
組:取樣器和輸出#
模型堆棧由 UNETLoader (#37) 和 LoraLoaderModelOnly (#191) 組裝,將 Flux Kontext Zoom Out LoRA 應用於基礎模型。ReferenceLatent (#177) 使用您的編碼圖像作為結構錨點,以便在邊界增長時主體保持不變。FluxGuidance (#35) 形塑參考對生成的影響程度;更高的值提高忠實度,而較低的值允許稍微新穎的填充。KSampler (#31) 執行實際擴散通過,VAEDecode (#8)、PreviewImage (#173) 和 SaveImage (#136) 顯示並保存最終放大圖像。
Comfyui Flux Kontext Zoom Out LoRA 工作流程中的關鍵節點#
FluxKontextImageScale (#42)#
通過縮放和構圖準備輸入以進行上下文感知的擴展。將其用作更改要添加多少畫布的唯一位置。如果您需要更多的空間,增加擴展量;如果邊緣看起來太新,減少它以保留更多原始像素。
LoraLoaderModelOnly (#191)#
加載並應用 kontext/zoomout-fal-v1.safetensors 到 Flux 1 Kontext UNet。如果您的輸出看起來偏差過大或過小,請在此處調整 LoRA 強度。保持變更適中,以保留 Zoom Out LoRA 的預期行為。
ReferenceLatent (#177)#
通過將取樣器置於 VAE 編碼的原始上來鎖定構圖和身份。如果您看到主體姿勢或比例的微妙漂移,請通過提供的節點進行條件路由,避免刪除它。將其與中性或最小提示配對可以最大化保真度。
FluxGuidance (#35)#
控制參考和提示對取樣器的指導程度。當擴展區域的光線或透視不匹配時,提高指導;如果您想要稍微更多的創意背景填充,則降低它。將其視為嚴格保護和有機延續之間的平衡旋鈕。
可選額外項#
- 保持正面提示最小。包含的提示已針對此 Flux Kontext Zoom Out LoRA 進行調整,通常無需修改。
- 如果邊界顯示微小縫隙,請嘗試在
FluxKontextImageScale中使用較小的擴展量或稍高的FluxGuidance。 - 對於風格化場景,添加 1–2 個詞描述語調或媒介,而不是主體形狀,以避免改變主要人物。
- 只更改種子以保存迭代變體;這讓您可以選擇最乾淨的延續而不改變構圖。
致謝#
此工作流程實施並建立在以下作品和資源之上。我們感謝 reverentelusarca 和 Flux Kontext Zoom Out LoRA 的貢獻和維護。有關權威詳細信息,請參閱下方鏈接的原始文檔和倉庫。
資源#
- reverentelusarca/Flux Kontext Zoom Out LoRA
- Hugging Face: Flux Kontext Zoom Out LoRA
注意:參考模型、數據集和代碼的使用受其作者和維護者提供的相應許可和條款的約束。

