
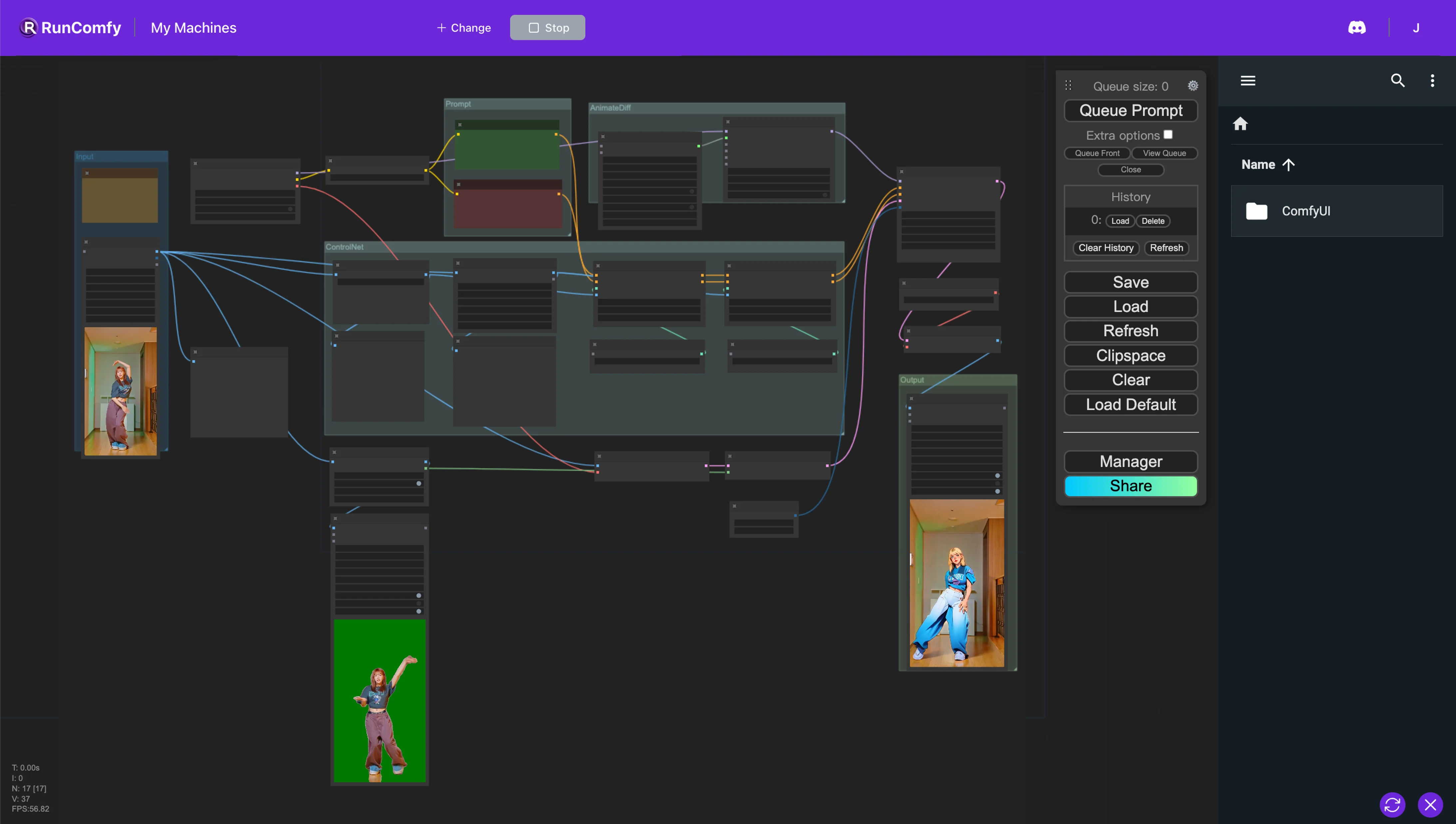
1. ComfyUI AnimateDiff, ControlNet 和 Auto Mask 工作流程#
此 ComfyUI 工作流程引入了一種強大的視頻重塑方法,專注於將角色轉換為動漫風格,同時保留原始背景。這種轉換由多個關鍵組件支持,包括 AnimateDiff、ControlNet 和 Auto Mask。
AnimateDiff 專為差分動畫技術而設計,能夠在動畫中保持一致的上下文。此組件專注於平滑過渡並增強重塑視頻內容的運動流暢性。
ControlNet 在精確的人體姿勢再現和操控中發揮關鍵作用。它利用先進的姿勢估計技術,準確捕捉和控制人體運動的細微差別,使角色轉換為動漫形式同時保留其原始姿勢。
Auto Mask 參與自動分割,擅長將角色從背景中隔離出來。此技術允許選擇性地重塑視頻元素,確保角色轉換在不改變周圍環境的情況下進行,保持原始背景的完整性。
此 ComfyUI 工作流程實現了標準視頻內容到風格化動畫的轉換,專注於效率和動漫風格角色生成的質量。
2. AnimateDiff 概述#
2.1. AnimateDiff 簡介#
AnimateDiff 作為一種 AI 工具出現,旨在將靜態圖像和文本提示動畫化為動態視頻,利用 Stable Diffusion 模型和專門的運動模塊。此技術通過預測幀之間的無縫過渡來自動化動畫過程,使其對於無需編碼技能或計算資源的用戶通過免費在線平台即可訪問。
2.2. AnimateDiff 的關鍵特性#
2.2.1. 全面模型支持:AnimateDiff 與多個版本兼容,包括 AnimateDiff v1、v2、v3 用於 Stable Diffusion V1.5,以及 AnimateDiff sdxl 用於 Stable Diffusion SDXL。它允許同時使用多個運動模型,促進創建複雜和分層的動畫。
2.2.2. 上下文批大小決定動畫長度:AnimateDiff 能夠通過調整上下文批大小創建無限長度的動畫。此功能允許用戶根據其特定需求自定義動畫的長度和過渡,提供高度可適應的動畫過程。
2.2.3. 平滑過渡的上下文長度:AnimateDiff 中的統一上下文長度旨在確保動畫不同片段之間的無縫過渡。通過調整統一上下文長度,用戶可以控制場景之間的過渡動態——較長的長度可實現更平滑、更無縫的過渡,而較短的長度則可實現更快、更明顯的變化。
2.2.4. 運動動態:在 AnimateDiff v2 中,專門的運動 LoRAs 可用於為動畫添加電影級鏡頭運動。此功能為動畫引入了一個動態層,顯著增強了其視覺吸引力。
2.2.5. 高級支持功能:AnimateDiff 設計為可與多種工具一起使用,包括 ControlNet、SparseCtrl 和 IPAdapter,為用戶擴大其項目創意可能性提供了顯著優勢。
3. ControlNet 概述#
3.1. ControlNet 簡介#
ControlNet 引入了一個增強圖像擴散模型的框架,通過條件輸入來精緻和引導圖像合成過程。它通過將給定擴散模型中的神經網絡塊複製為兩組來實現此目的:一組保持 "鎖定" 以保留原始功能,另一組則 "可訓練",適應提供的特定條件。此雙重結構允許開發人員通過使用 OpenPose、Tile、IP-Adapter、Canny、Depth、LineArt、MLSD、Normal Map、Scribbles、Segmentation、Shuffle 和 T2I Adapter 等模型來合併各種條件輸入,從而直接影響生成的輸出。通過此機制,ControlNet 為開發人員提供了一個強大的工具來控制和操縱圖像生成過程,增強擴散模型的靈活性及其在多樣化創意任務中的適用性。
預處理器和模型集成
3.1.1. 預處理配置:啟動 ControlNet 涉及選擇合適的預處理器。建議啟用預覽選項,以便可視化了解預處理的影響。預處理後,工作流程將過渡到利用預處理圖像進行進一步的處理步驟。
3.1.2. 模型匹配:簡化模型選擇過程,ControlNet 通過根據共享關鍵詞將模型與相應的預處理器對齊,促進無縫的集成過程。
3.2. ControlNet 的關鍵特性#
深入探討 ControlNet 模型
3.2.1. OpenPose 套件:專為精確人體姿勢檢測而設計,OpenPose 套件包括用於檢測身體姿勢、面部表情和手部動作的模型,具有卓越的準確性。各種 OpenPose 預處理器針對特定檢測需求,從基本姿勢分析到面部和手部細節的詳細捕捉。
3.2.2. 瓦片重採樣模型:通過一個升級工具,瓦片重採樣模型可增強圖像分辨率和細節,旨在豐富圖像質量而不損害視覺完整性。
3.2.3. IP-Adapter 模型:促進創新地使用圖像作為提示,IP-Adapter 將參考圖像中的視覺元素整合到生成的輸出中,融合文本到圖像擴散功能以豐富視覺內容。
3.2.4. Canny 邊緣檢測器:因其邊緣檢測能力而受到推崇,Canny 模型強調圖像的結構本質,允許創意地重新詮釋視覺效果,同時保持核心構圖。
3.2.5. 深度感知模型:通過各種深度預處理器,ControlNet 能夠從圖像中推導和應用深度提示,提供生成視覺的分層深度視角。
3.2.6. 線條藝術模型:使用 LineArt 預處理器將圖像轉換為藝術線條圖,滿足從動漫到現實素描的多樣藝術偏好,ControlNet 能夠適應一系列風格需求。
3.2.7. 塗鴉處理:使用如 Scribble HED、Pidinet 和 xDoG 等預處理器,ControlNet 將圖像轉換為獨特的塗鴉藝術,提供多樣的風格進行邊緣檢測和藝術再詮釋。
3.2.8. 分割技術:ControlNet 的分割能力能夠準確分類圖像元素,根據物體分類進行精確的操作,理想用於複雜場景構建。
3.2.9. 隨機模型:引入一種顏色方案創新的方法,隨機模型將輸入圖像隨機化以生成新的顏色模式,創意地改變原始圖像,同時保留其本質。
3.2.10. T2I Adapter 創新:T2I Adapter 模型,包括 Color Grid 和 CLIP Vision Style,將 ControlNet 推向新的創意領域,融合和調整顏色和風格,以產生視覺上引人注目的輸出,並尊重原始的顏色方案或風格屬性。
3.2.11. MLSD(移動線段檢測):專注於直線檢測,MLSD 對於專注於建築和室內設計的項目來說是無價的,優先考慮結構清晰度和精確性。
3.2.12. 法線貼圖處理:利用表面方向數據,法線貼圖預處理器複製參考圖像的 3D 結構,通過詳細的表面分析增強生成內容的現實感。
