
大家好!你是否曾惊叹于将文本转化为视频的想法?这并不是全新的概念,但它正变得越来越有趣。今天,让我们聊聊其中一个很酷的工具,即ComfyUI环境中的AnimateDiff。无论你是数字艺术家还是仅仅喜欢探索新技术,AnimateDiff都为你提供了一种将文本创意转化为动画GIF和视频的激动人心的方式。
我们将涵盖:
- AnimateDiff如何工作?
- ComfyUI AnimateDiff工作流程 - 无需安装,完全免费
- AnimateDiff V3 vs. Animatediff SDXL vs. AnimateDiff v2
- AnimateDiff V3: Animatediff中的新运动模块
- AnimateDiff SDXL
- AnimateDiff V2
- AnimateDiff设置:如何在ComfyUI中使用AnimateDiff
- AnimateDiff模型
- AnimateDiff的检查点模型
- Beta Schedule
- Motion Scale
- 上下文批量大小决定动画长度
- 上下文长度
- Motion LoRA用于相机动态(仅AnimateDiff v2)
- AnimateDiff提示
- AnimateDiff提示Travel / 提示调度
- ComfyUI高分辨率修复 - 增强你的动画
- 即用型ComfyUI AnimateDiff工作流程:探索稳定扩散动画
1. AnimateDiff如何工作?#
AnimateDiff的核心是一个运动建模模块。可以将其视为操作的大脑,从各种视频片段中学习所有关于运动的知识。它就像一位掌握所有舞步的舞蹈老师。这个模块与预训练的文本到图像模型无缝集成。所以,你不再局限于静态图像 - 你的创作可以舞动、跳跃和旋转!
2. ComfyUI AnimateDiff工作流程 - 无需安装,完全免费#
请查看上面使用ComfyUI AnimateDiff工作流程制作的视频。现在,你可以直接进入这个Animatediff工作流程,无需任何安装麻烦。我们已经在基于云的ComfyUI中为你设置好了一切,包括AnimateDiff工作流程以及Animatediff V3、Animatediff SDXL和Animatediff V2的所有基本模型和自定义节点。
随意进行实验和探索。或者你可以继续阅读本教程,了解如何使用AnimateDiff,然后再尝试。
3. AnimateDiff V3 vs. Animatediff SDXL vs. AnimateDiff v2#
让我们来看看AnimateDiff的不同版本。每个版本都有自己的魅力,所以准备好来一次快速巡游吧!
3.1. AnimateDiff V3: Animatediff中的新运动模块#
AnimateDiff V3不仅仅是一个新版本,它在运动模块技术方面是一个进化,以其改进的功能脱颖而出。运动模块v3_sd15_mm.ckpt是这个版本的核心,负责细微和灵活的动画。
让我们来看看它背后的技术魔法。这里的明星角色是Domain Adapter LoRA模块,它本质上是运动模块的启动器。通过在来自视频数据集的静态帧上进行训练,这个LoRA模块使AnimateDiff更善于处理运动。很酷,对吧?
使用AnimateDiff V3时,你会注意到它不一定在各个方面都胜过Animatediff V2。相反,它提供了不同类型的运动,为你的创作武器库添加了更多工具。
正面提示:杰作,最佳质量,彩虹头发女孩,非常狂野的头发,鬃毛
负面提示: (低质量,NSFW,最差质量:1.4),(变形,扭曲,毁容:1.3),easynegative,手,bad-hands-5,模糊,丑陋,文字,embedding:easynegative
检查点:
toonyou_beta6
3.2. AnimateDiff SDXL#
如果你喜欢高分辨率视频,AnimateDiff SDXL可能是一个选择。它运行在 mm_sdxl_v10_beta.ckpt 运动模块上,旨在制作1024x1024分辨率的16帧动画。不过提醒一下,它还处于Beta阶段,所以可能明智的做法是等待一段时间再尝试。
使用与AnimateDiff V3相同的正面提示和负面提示
检查点:
dreamshaperXL10_alpha2Xl10
3.3. AnimateDiff V2#
AnimateDiff V2是经典版本!使用 mm_sd_v15_v2.ckpt ,这个版本为八个基本相机运动提供MotionLoRA:放大/缩小、左/右平移、上/下倾斜和顺时针/逆时针滚动。如果你想为动画增添戏剧性的相机运动,Animatediff V2非常完美。
使用与AnimateDiff V3相同的正面提示和负面提示
检查点:
toonyou_beta6
4. AnimateDiff设置:如何在ComfyUI中使用AnimateDiff#
一旦进入ComfyUI内的AnimateDiff工作流程,你会看到一组标记为"AnimateDiff Options"的选项,如下图所示。这个区域包含了你在使用AnimateDiff时可能会用到的设置和功能。
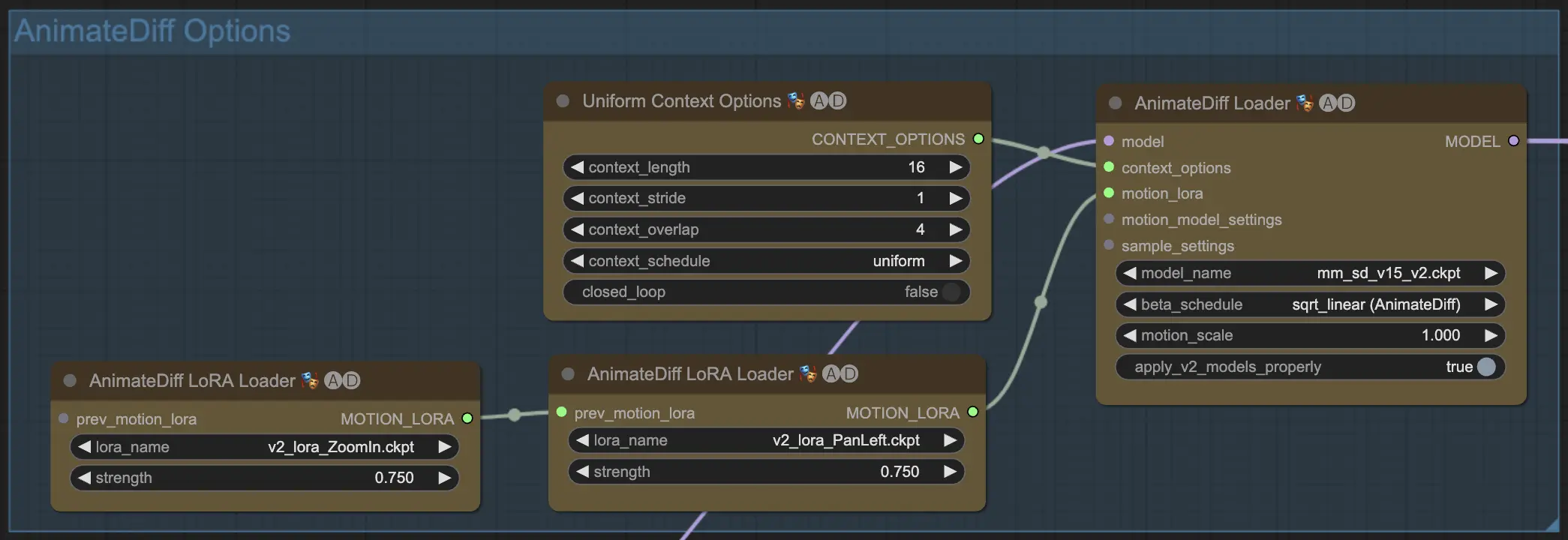
4.1. AnimateDiff模型#
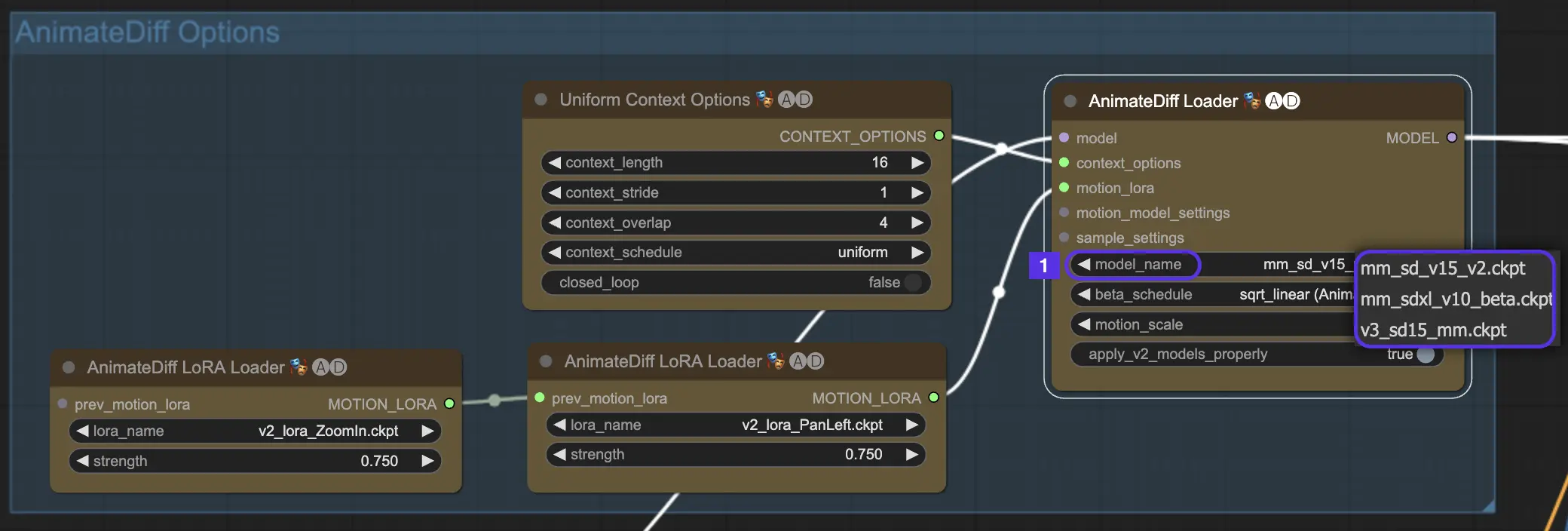
首先,在model_name下拉菜单中选择你想尝试的AnimateDiff运动模块:
- AnimateDiff V3使用
v3_sd15_mm.ckpt - AnimateDiff SDXL使用
mm_sdxl_v10_beta.ckpt - AnimateDiff V2使用
mm_sd_v15_v2.ckpt
4.2. AnimateDiff的检查点模型#
AnimateDiff需要一个稳定扩散检查点模型。
对于AnimateDiff V2和V3,你必须使用SD v1.5模型。realisticVisionV60B1_V51VAE、toonyou_beta6和cardos_Animev2.0等模型是首选。
如果你倾向于AnimateDiff SDXL,则瞄准SDXL模型,如sd_xl_base_1.0或dreamshaperXL10_alpha2Xl10。
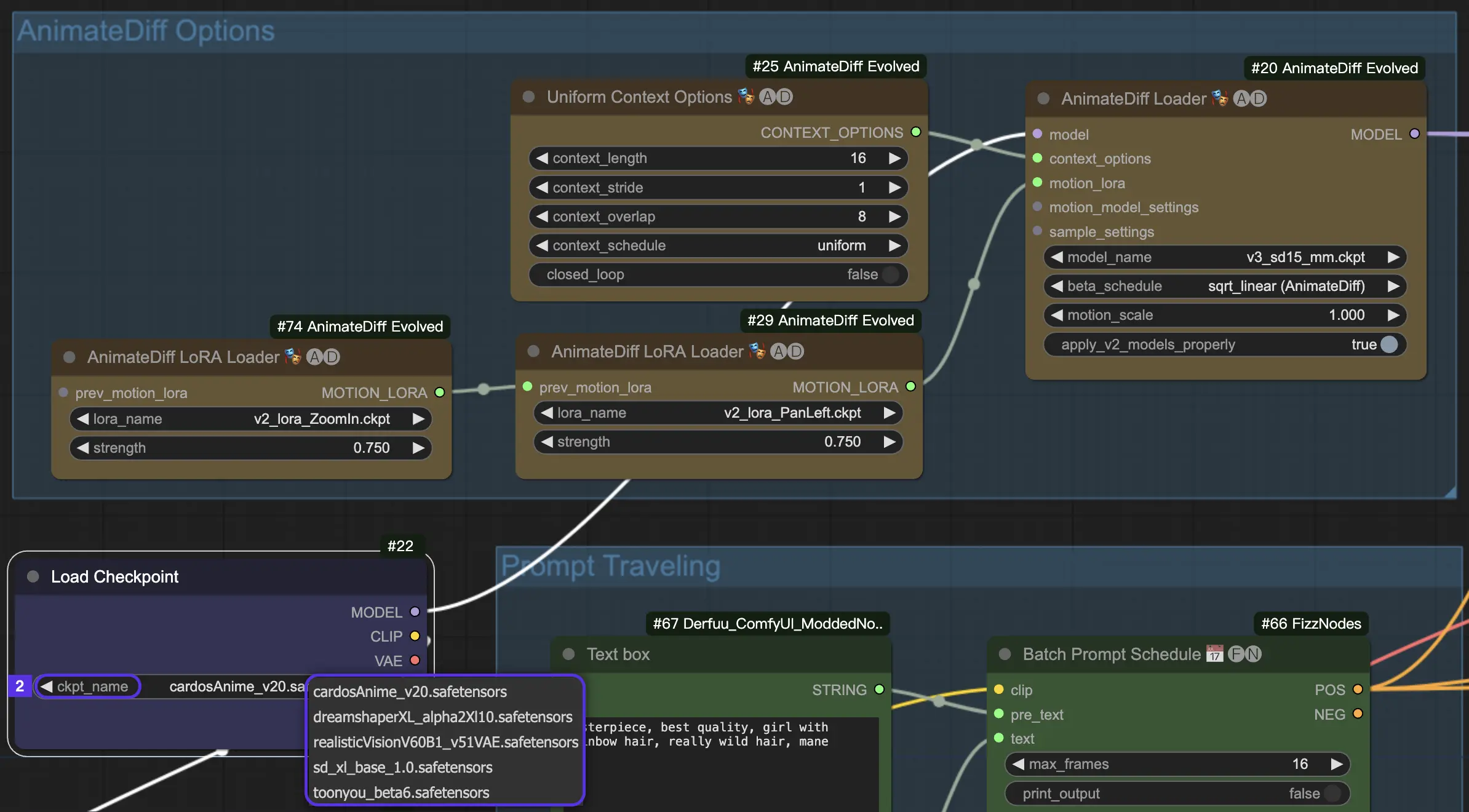
在RunComfy云环境中,为方便起见,所有运动模块和检查点模型都已预装。
4.3. Beta Schedule#
AnimateDiff中的Beta Schedule决定了动画生成过程中噪声减少的行为。
对于AnimateDiff V3和V2,sqrt_linear设置通常是不二之选,但不要害怕尝试linear以获得一些有趣的效果。
对于AnimateDiff XL,坚持使用linear (AnimateDiff-SDXL)。
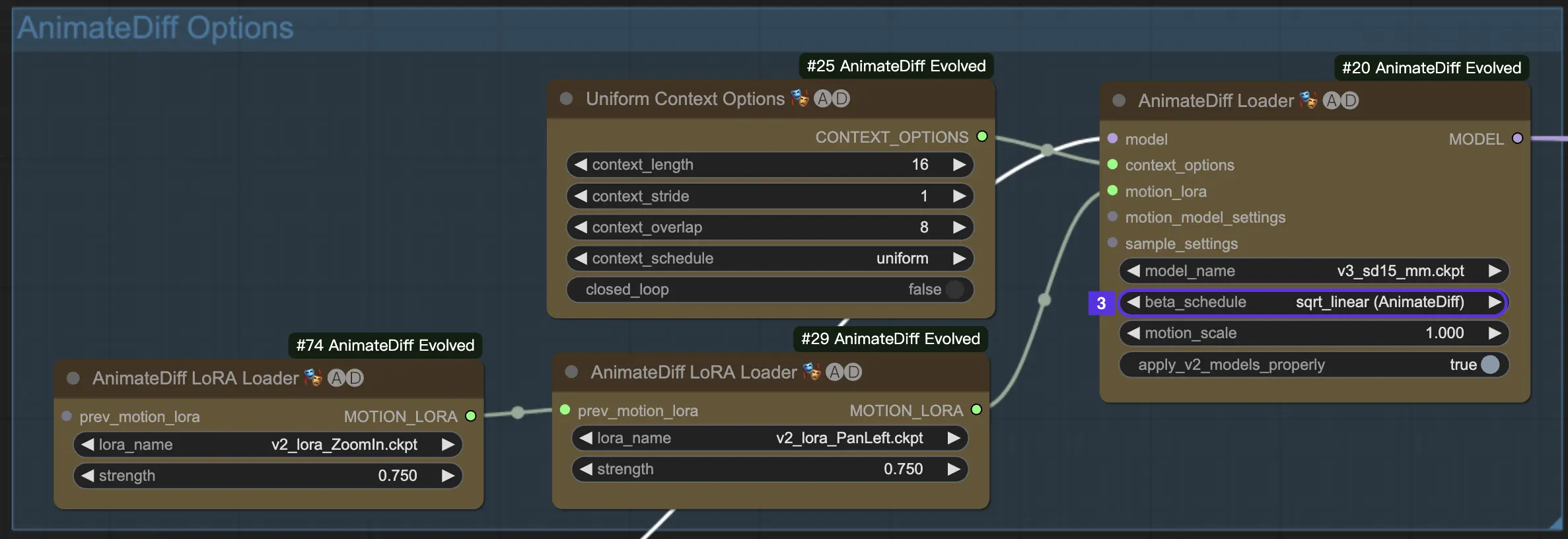
4.4. Motion Scale#
AnimateDiff中的Motion Scale可以控制运动强度。小于1意味着更微妙的运动;大于1意味着更明显的运动。
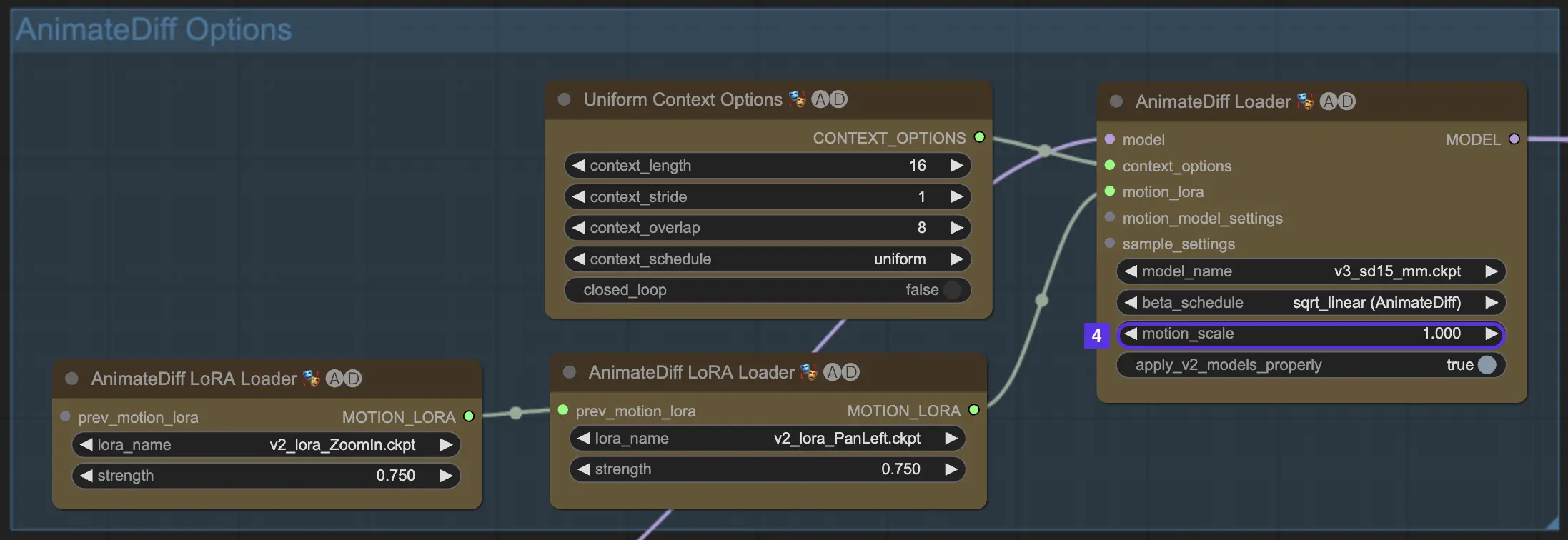
4.5. 上下文批量大小决定动画长度#
AnimateDiff中的批量大小代表了动画的构建块。它是影响动画长度的基本因素。它决定了动画将由多少个"场景"或片段组成。
更大的批量大小会导致动画中有更多场景,允许更长、更精细的叙事体验。批量大小没有上限,所以你可以自由创作任意长度的动画。默认批量大小为16。
- 16批量大小 = 一个快速的2秒视频
- 32批量大小 = 一个简短的4秒片段
- 64批量大小 = 一个更长的8秒特色
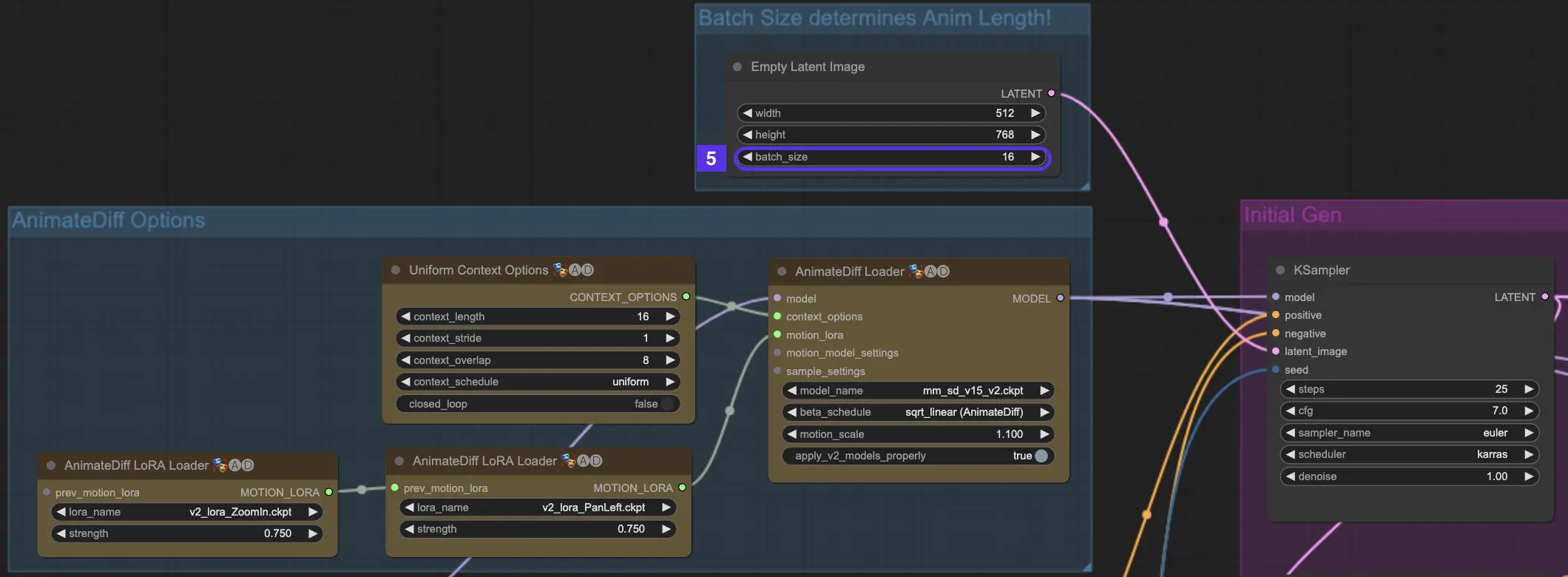
4.6. 上下文长度#
AnimateDiff中的Uniform Context Length在确保批量大小设置的场景之间平滑过渡方面发挥着关键作用。它就像一位熟练的剪辑师,确切知道如何将场景拼接在一起,以获得最自然的流畅度。
你为Uniform Context设置的长度将决定场景之间过渡的性质。更长的Uniform Context Length会导致更平滑、更渐进的过渡,使从一个场景到另一个场景的转换几乎无法察觉。另一方面,更短的长度会创造更快、更明显的过渡,这可能适合某些讲故事的效果。默认的Uniform Context长度为16。
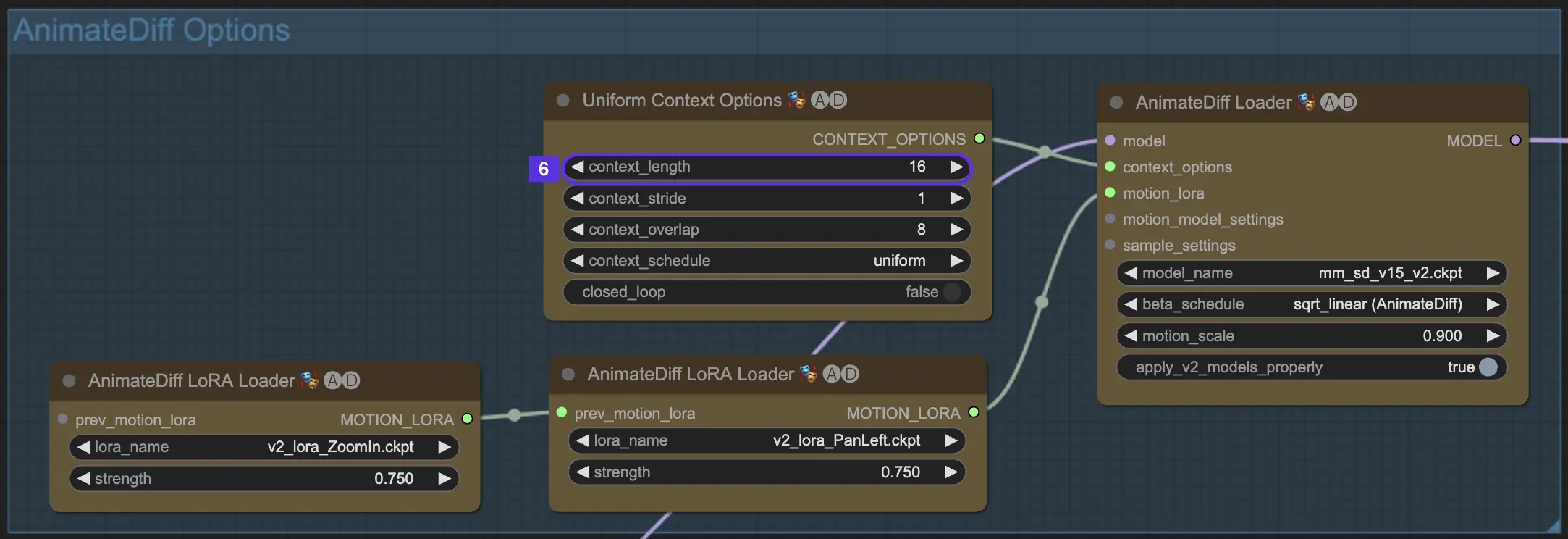
4.7. Motion LoRA用于相机动态(仅AnimateDiff v2)#
Motion LoRAs仅与AnimateDiff v2兼容。这些巧妙的补充为你的动画带来了相机运动的动态层。使用Motion LoRAs时,关键是要在LoRA权重上取得恰当平衡。将其设置在0.75左右往往能达到最佳效果,给你平滑的相机运动而没有任何讨厌的背景伪影。
更重要的是,你有创意自由去链接多个Motion LoRAs。通过战略性地结合不同的Motion LoRA模型,你可以编排复杂的相机运动,进行实验,找到完美融合运动的独特动画愿景,从而将你的动画提升为电影杰作。
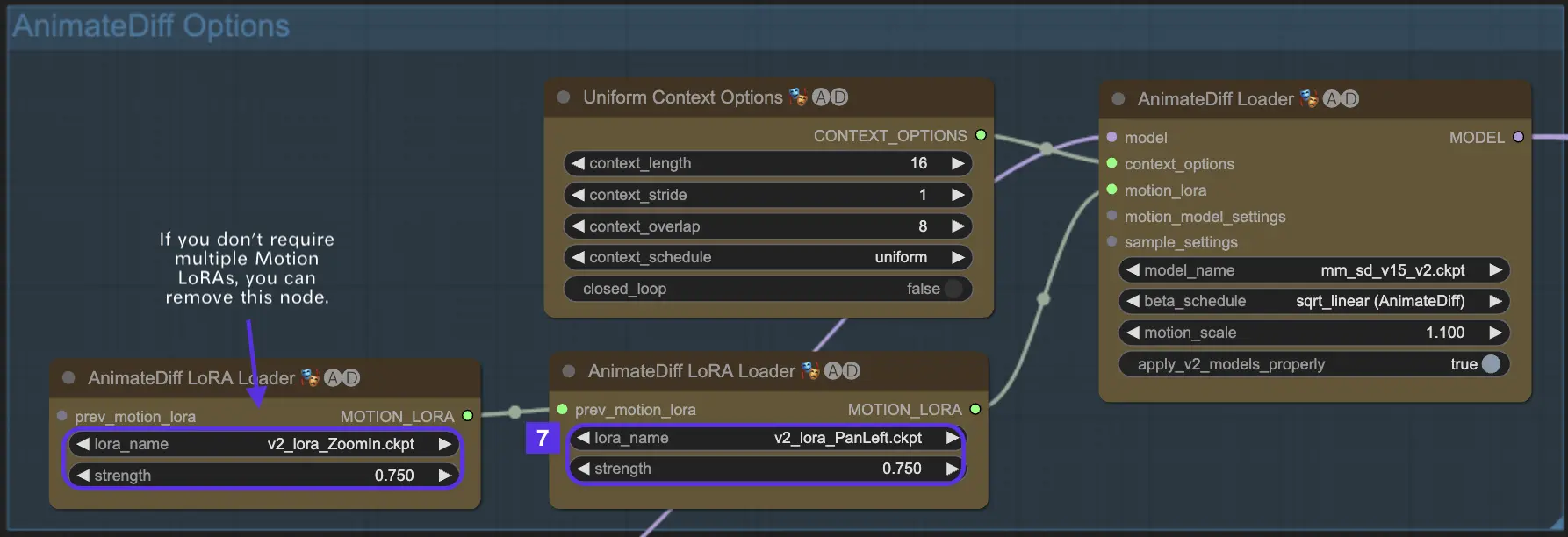
这里是一个同时使用Motion LoRa的"左平移"和"放大"功能的例子。
5. AnimateDiff提示#
好了,现在你已经调整好模型和AnimateDiff设置,是时候大显身手了!这就是你将文本转化为视频动画的地方。
这里是一个正面提示和负面提示的例子:
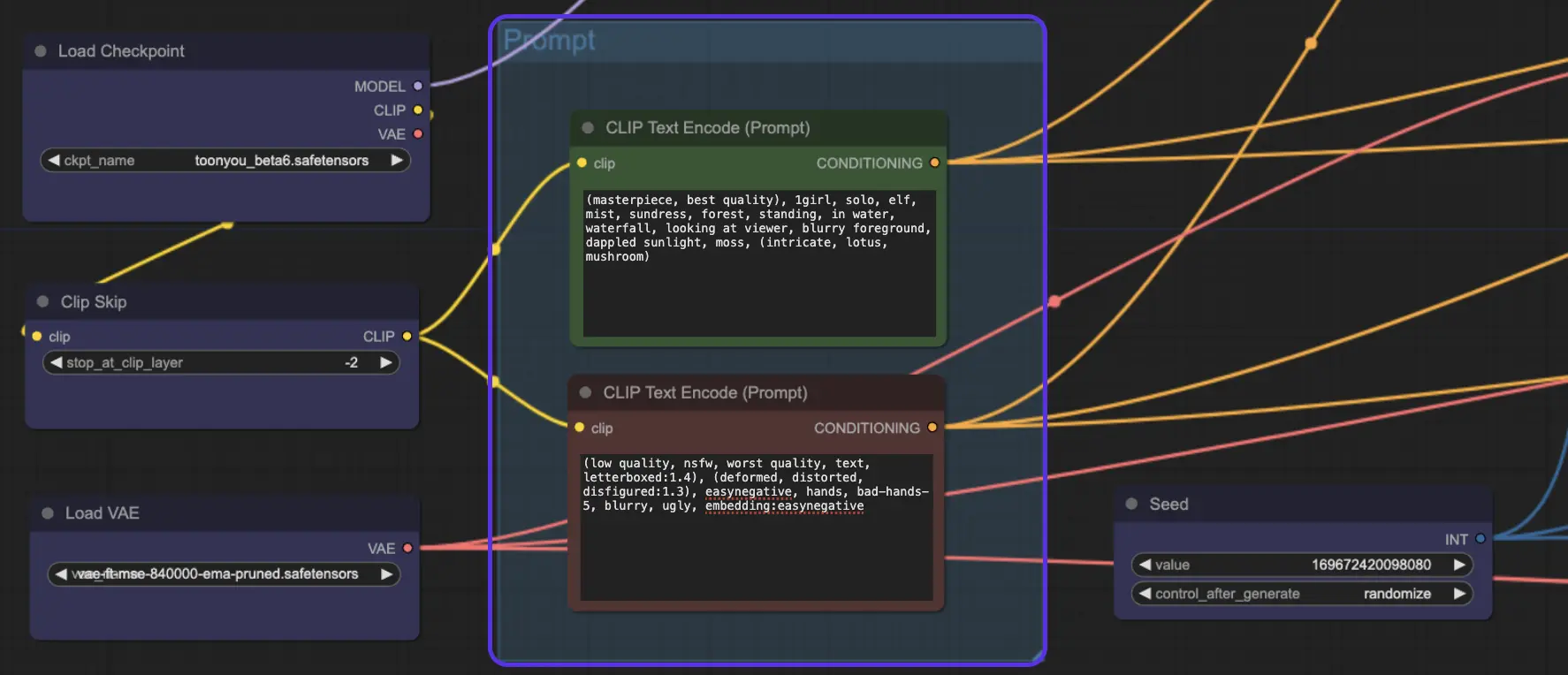
正面提示: (杰作,最佳质量),1个女孩,独自,精灵,薄雾,连衣裙,森林,站在水中,瀑布,看着观众,模糊的前景,斑驳的阳光,苔藓,(复杂的,荷花,蘑菇)
负面提示: (低质量,NSFW,最差质量,文字,加黑边:1.4),(变形,扭曲,毁容:1.3),easynegative,手,bad-hands-5,模糊,丑陋,embedding:easynegative
6. AnimateDiff提示Travel / 提示调度#
但等等,还有更多!你试过提示Travel / 提示调度吗?可以把它想象成踏入电影导演的鞋子。你掌控全局,一个场景接一个场景地制作你的故事。就像拼凑一个拼图,每一块都是你故事中的一个时刻。
提示Travel如何工作?#
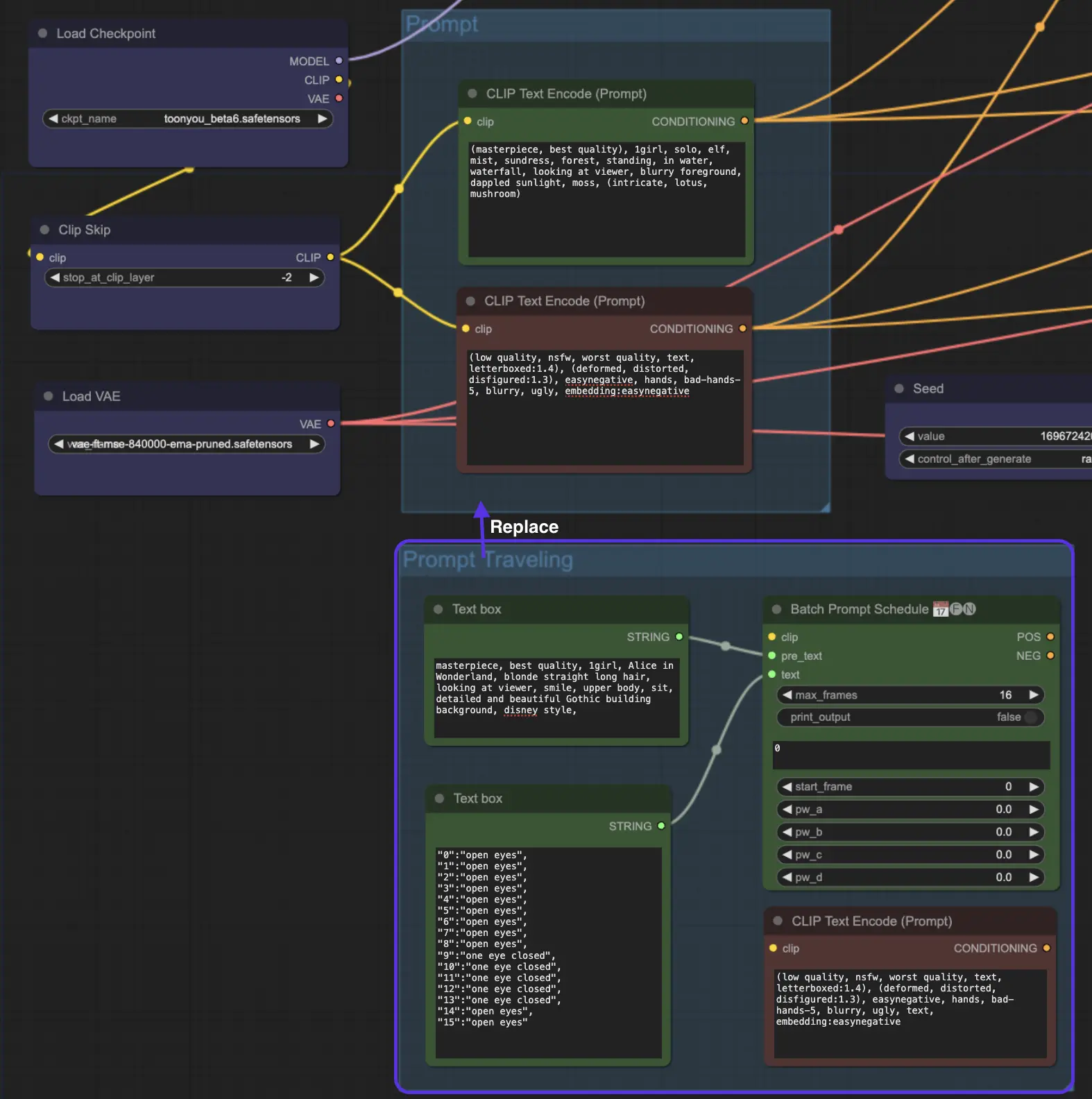
想象你正在创作一部迷你电影。你在第1帧设置提示1,在第8帧设置提示2,以此类推。AnimateDiff将无缝融合这些提示,从第1帧到第8帧创建平滑过渡。
提示: 虽然提示Travel可能很有趣,但重要的是要注意,它并不总是一个确定无疑的成功。提示Travel的有效性也取决于你选择的检查点模型。例如,cardos_Animev2.0模型与提示Travel兼容,但并非所有模型都是如此。此外,结果可能是不可预测的 - 某些提示可能无法很好地融合,导致过渡效果不理想。这使得提示Travel更像是一个实验性功能,而不是创建无缝动画的保证工具。
我们在AnimateDiff ComfyUI工作流程的末尾放置了"Prompt Travel / Prompt Scheduling"节点。如果你好奇想要尝试,你需要使用"Prompt Travel"代替常规的"Prompt"选项。
7. ComfyUI高分辨率修复 - 增强你的动画#
通过将AnimateDiff与高分辨率修复结合使用,你可以提高图像的分辨率。这个过程将略微模糊的图像转化为清晰的杰作。在本节中,我们将介绍两种方法。
7.1. 潜在上采样#
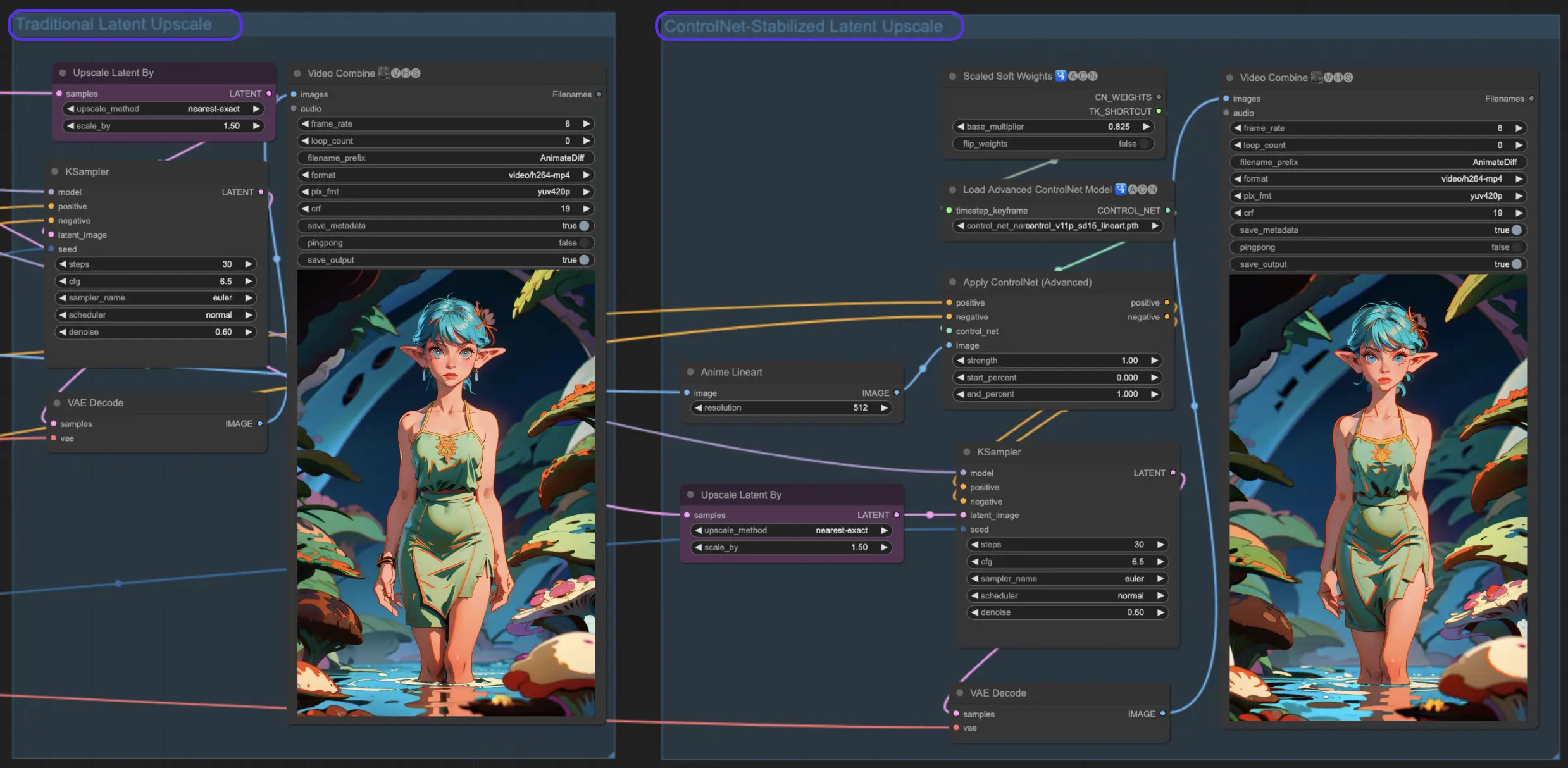
ComfyUI中的传统潜在上采样。通过应用0.6去噪强度等设置并选择1.5倍上采样,你会看到你的动画转变得更加丰富细节和清晰锐利。就像戴上眼镜,突然看到高清的世界!
7.2. ControlNet上采样#
传统的潜在上采样很酷,但让我们通过ControlNet辅助潜在上采样更上一层楼。它使用ControlNets进行更精确的上采样,确保你的动画保持其完整性。通过添加线稿预处理器和正确的controlnet模型,你将增强你的艺术作品,同时保持其灵魂不变。
8. 即用型ComfyUI AnimateDiff工作流程:探索稳定扩散动画#
我们已经深入探讨了ComfyUI中AnimateDiff的精彩世界。对于那些渴望尝试我们强调的ComfyUI AnimateDiff工作流程的人来说,一定要试试RunComfy,这是一个配备强大GPU的云环境,完全准备就绪,包括从基本模型到自定义节点的一切。无需手动设置!只是一个释放你创造力的游乐场。🌟
作者: RunComfy编辑
我们的编辑团队使用人工智能已有15年以上的经验,从RNN/CNN时代的NLP/Vision开始。我们积累了大量关于AI聊天机器人/艺术/动画的经验,如BERT/GAN/Transformer等。如果你在AI艺术、动画和视频方面需要帮助,请与我们联系。