
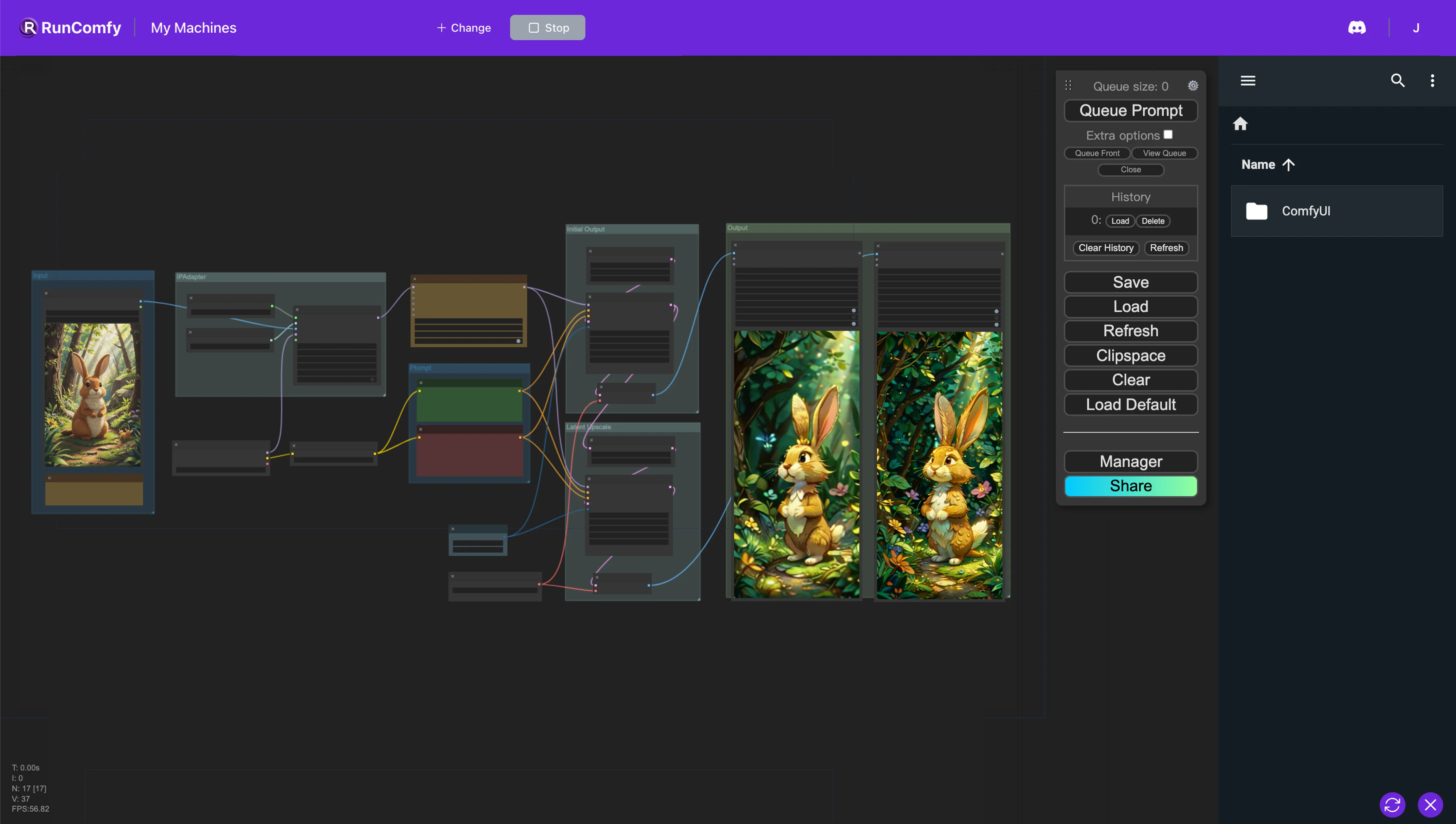
1. ComfyUI 工作流程:AnimateDiff + IPAdapter | 图像到视频#
该 ComfyUI 工作流程专为使用 AnimateDiff 和 IP-Adapter 从参考图像创建动画而设计。AnimateDiff 节点集成了模型和上下文选项,用于调整动画动态。相反,IP-Adapter 节点有助于以可以模仿参考图像的风格、构图或面部特征的方式使用图像作为提示,显著增强了生成动画或图像的自定义和质量。
2. AnimateDiff 概述#
请查看有关如何在 ComfyUI 中使用 AnimateDiff 的详细信息
3. IP-Adapter 概述#
3.1. IP-Adapter 简介#
IP-Adapter 代表 "图像提示适配器",是一种用于增强文本到图像扩散模型的新方法,能够在图像生成任务中使用图像提示。IP-Adapter 旨在解决文本提示的不足之处,文本提示通常需要复杂的提示工程来生成所需的图像。除文本外,引入图像提示可以提供更直观有效的方式来指导图像合成过程。
IP-Adapter 的不同模型
IP-Adapter 套件包括各种模型,每种模型都针对特定用例和图像合成复杂程度量身定制。以下是可用模型的概述:
3.1.1. v1.5 模型
ip-adapter_sd15:1.5 版本的标准模型,利用 IP-Adapter 的能力进行图像到图像的调节和文本提示增强。ip-adapter_sd15_light:标准模型的轻量版,针对资源密集度较低的应用进行了优化,同时仍然利用 IP-Adapter 技术。ip-adapter-plus_sd15:增强型模型,生成与原始参考更紧密对齐的图像,改进了细节。ip-adapter-plus-face_sd15:与 IP-Adapter Plus 类似,重点是在生成的图像中更准确地复制面部特征。ip-adapter-full-face_sd15:强调全脸细节的模型,可能提供高保真度的 "换脸" 效果。ip-adapter_sd15_vit-G:使用视觉转换器(ViT)BigG 图像编码器进行更详细的图像特征提取的标准模型变体。
3.1.2. SDXL 模型
ip-adapter_sdxl:SDXL 的基础模型,旨在处理更大、更复杂的图像提示。ip-adapter_sdxl_vit-h:与 ViT H 图像编码器配对的 SDXL 模型,在性能和计算效率之间取得平衡。ip-adapter-plus_sdxl_vit-h:增强图像提示细节和质量的高级版本的 SDXL 模型。ip-adapter-plus-face_sdxl_vit-h:专注于面部细节的 SDXL 变体,非常适合面部准确性至关重要的项目。
3.1.3. FaceID 模型
FaceID:使用 InsightFace 提取面部 ID 嵌入的模型,为面部相关的图像生成提供独特的方法。FaceID Plus:FaceID 模型的改进版本,结合 InsightFace 用于面部特征和 CLIP 图像编码用于全局面部特征。FaceID Plus v2:FaceID Plus 的迭代,具有改进的模型检查点和在 CLIP 图像嵌入上设置权重的能力。FaceID Portrait:与 FaceID 类似的模型,但设计用于接受多个裁剪面部图像,以实现更多样化的面部调节。
3.1.4. SDXL FaceID 模型
FaceID SDXL:FaceID 的 SDXL 版本,保留与 v1.5 相同的 InsightFace 模型,但针对 SDXL 应用进行了扩展。FaceID Plus v2 SDXL:FaceID Plus v2 的 SDXL 改编版,用于具有增强保真度的高清图像生成。
3.2. IP-Adapter 的关键特性#
3.2.1. 文本和图像提示集成:IP-Adapter 同时使用文本和图像提示的独特功能实现了多模态图像生成,为控制扩散模型输出提供了一个多功能、强大的工具。
3.2.2. 解耦交叉注意力机制:IP-Adapter 采用解耦交叉注意力策略,通过分离文本和图像特征,提高了模型处理不同模态的效率。
3.2.3. 轻量级模型:尽管具有全面的功能,但 IP-Adapter 保持相对较低的参数计数(22M),提供与微调图像提示模型相媲美或超越的性能。
3.2.4. 兼容性和泛化:IP-Adapter 设计具有与现有可控工具的广泛兼容性,并且可以应用于从同一基础模型派生的自定义模型,以增强泛化能力。
3.2.5. 结构控制:IP-Adapter 支持详细的结构控制,使创作者能够以更高的精度指导图像生成过程。
3.2.6. 图像到图像和修复功能:通过支持图像引导的图像到图像转换和修复,IP-Adapter 拓宽了可能的应用范围,在各种图像合成任务中实现创造性和实际用途。
3.2.7. 使用不同编码器进行定制:IP-Adapter 允许使用各种编码器,如 OpenClip ViT H 14 和 ViT BigG 14,来处理参考图像。这种灵活性有助于处理不同的图像分辨率和复杂性,使其成为寻求根据特定需求或预期结果定制图像生成过程的创作者的通用工具。
在图像生成项目中引入 IP-Adapter 技术不仅简化了复杂和详细图像的创建,而且显著提高了生成图像与原始提示的质量和保真度。通过弥合文本和图像提示之间的差距,IP-Adapter 提供了一种强大、直观和高效的方法来控制图像合成的细微差别,使其成为在 ComfyUI 工作流程或任何其他需要高质量、定制图像生成的环境中工作的数字艺术家、设计师和创作者不可或缺的工具。
