
ComfyUI F5 TTS: texto-para-fala e clonagem de voz em uma única solução#
Este fluxo de trabalho ComfyUI F5 TTS permite gerar fala natural a partir de texto e clonar vozes diretamente no ComfyUI. Ele é alimentado pelos nós personalizados ComfyUI-F5-TTS e inclui um caminho completo para clonagem baseada em referência: forneça um WAV curto mais uma transcrição correspondente para condicionar o modelo, então sintetize novas falas que sigam o timbre e o estilo do locutor de referência. O gráfico também vem com testes prontos para várias variantes de modelos, idiomas e vocoders, para que você possa comparar saídas rapidamente e decidir o que melhor se adapta a narrações, locuções, diálogos de personagens ou demonstrações de produtos.
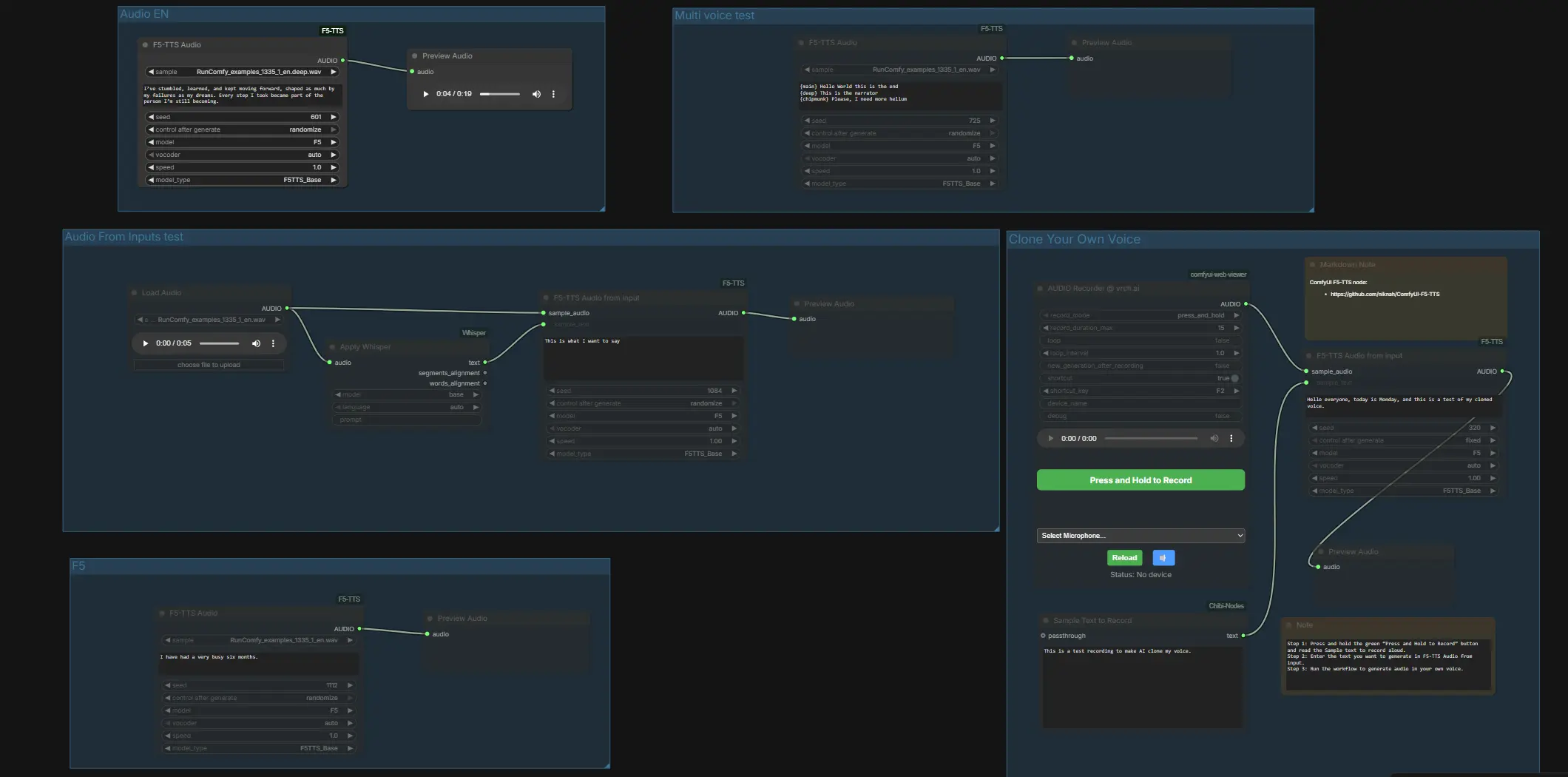
Tudo está organizado em grupos claros para que você possa usar o ComfyUI F5 TTS de duas maneiras: TTS rápido e com um clique em inglês, francês, alemão e japonês, ou clonagem de voz via um gravador embutido ou arquivos emparelhados. Um caminho de transcrição compacto do Whisper está incluído para ajudá-lo a obter uma transcrição de amostra precisa quando você já tem uma gravação limpa.
Modelos principais no fluxo de trabalho ComfyUI F5 TTS#
- Fish Audio F5-TTS. TTS zero-shot que aprende as características de um locutor a partir de uma referência curta e produz fala de alta qualidade em vários idiomas. Veja o projeto para detalhes do modelo e histórico de treinamento. GitHub
- OpenAI Whisper. Reconhecimento de fala usado aqui para transcrever automaticamente seu clipe de referência para que o texto de amostra corresponda exatamente, o que melhora a qualidade da clonagem. GitHub
- BigVGAN. Um vocoder neural de alta fidelidade disponível como uma opção de decodificação para uma saída mais nítida e clara. GitHub
- Vocos. Uma alternativa de vocoder neural rápida e leve focada em velocidade e baixa latência. GitHub
- Nós personalizados ComfyUI-F5-TTS. A integração ComfyUI que conecta F5-TTS e backends compatíveis em nós usados em todo este gráfico. GitHub
Como usar o fluxo de trabalho ComfyUI F5 TTS#
Em um nível alto, o fluxo de trabalho oferece grupos independentes para comparações rápidas de modelos e uma linha de clonagem dedicada. Comece testando os grupos pré-configurados para confirmar a voz e o vocoder que você prefere, então passe para a clonagem com sua própria amostra. Cada subseção abaixo explica o que o grupo faz e os poucos inputs que importam.
Teste de Áudio de Entradas#
Esta linha demonstra a transcrição de referência mais o condicionamento. LoadAudio (#4) traz um WAV, Apply Whisper (#13) o transcreve, e F5TTSAudioInputs (#26) usa tanto o áudio de amostra quanto o texto do Whisper para condicionar a voz antes da pré-visualização. Forneça uma amostra falada limpa e deixe o Whisper preencher a porta de transcrição para que o par corresponda exatamente. Se você quiser fornecer arquivos diretamente, coloque um .wav e um .txt emparelhados com o mesmo nome de arquivo em ComfyUI/input, então reinicie o ComfyUI para que o gráfico possa vê-los.
Teste de múltiplas vozes#
Este grupo mostra a troca de estilo dentro de uma linha usando um único nó de síntese. F5TTSAudio (#17) lê um roteiro com segmentos rotulados, para que você possa testar vários estilos de personagens ou mudanças de ênfase em uma única passagem. É uma maneira rápida de ouvir como o ComfyUI F5 TTS lida com timbres contrastantes ou ritmo de narrador versus personagem.
Áudio EN#
Use F5TTSAudio (#15) para TTS em inglês simples. Insira seu roteiro e pré-visualize para avaliar a pronúncia e o ritmo básicos com o preset padrão do F5. Esta linha é ideal para iteração rápida antes de você se comprometer com a clonagem ou mistura de múltiplas vozes.
F5v1#
Este caminho executa o nó F5TTSAudio (#33) contra a variante F5 v1 para que você possa comparar tom e prosódia com o preset principal do F5. Use o mesmo texto que a linha EN para facilitar o julgamento das diferenças. É útil ao escolher um modelo padrão para um projeto mais longo.
Áudio FR#
Esta linha tem como alvo a síntese em francês com F5TTSAudio (#27) configurado para um preset francês. Forneça um roteiro em francês e pré-visualize a saída para verificar vogais nasais e manejo de ligação. Alterne com a linha EN para comparar clareza e velocidade.
Áudio DE bigvgan#
Aqui, F5TTSAudio (#30) usa um preset alemão e o vocoder BigVGAN para uma decodificação mais brilhante e nítida. Use esta linha quando quiser mais presença ou um brilho tipo estúdio. Se preferir uma renderização mais suave, compare com uma linha Vocos.
Áudio JP#
Este caminho usa F5TTSAudio (#25) com um preset japonês. Cole um roteiro japonês para avaliar o acento de pitch e o tempo de mora. É um bom ponto de partida para leituras no estilo anime ou linhas de produtos destinadas a públicos japoneses.
Teste E2#
Este grupo exercita F5TTSAudio (#29) com um preset compatível com E2 e o vocoder Vocos para testar um backend alternativo. Use-o para comparar latência e características de timbre com suas execuções F5.
Clone Sua Própria Voz#
Grave, emparelhe e clone diretamente no ComfyUI. Pressione o microfone em VrchAudioRecorderNode (#43) e leia o prompt exibido na caixa “Texto de Amostra para Gravar” Textbox (#42). O gravador direciona seu WAV para F5TTSAudioInputs (#44) junto com o texto exato que você falou, o que condiciona o modelo em seu timbre e estilo antes da pré-visualização em PreviewAudio (#45). Para melhores resultados, fale em um ambiente silencioso e certifique-se de que o texto de referência corresponda exatamente ao que você disse; então digite quaisquer novas linhas que você deseja que a voz clonada diga e execute o gráfico.
Nós principais no fluxo de trabalho ComfyUI F5 TTS#
F5TTSAudio (#15)#
O nó central de TTS de passagem única usado nos grupos EN, FR, DE, JP, F5v1 e E2. Forneça seu roteiro e escolha o preset de modelo e vocoder que se adequam ao seu idioma e entrega. Se você quiser tomadas reprodutíveis, mantenha a semente fixa; se quiser variedade, randomize entre as execuções. A implementação é fornecida pela extensão ComfyUI-F5-TTS. GitHub GitHub - FishAudio/F5-TTS
F5TTSAudioInputs (#44)#
O ponto de entrada de clonagem que consome um WAV de referência e sua transcrição correspondente para construir uma representação do locutor, então sintetiza novas falas nessa voz. Use uma amostra limpa com volume consistente e certifique-se de que a transcrição é exata para maximizar a similaridade e reduzir artefatos. Mude presets de modelo ou vocoders aqui se você precisar de uma decodificação mais brilhante ou mais neutra. GitHub - FishAudio/F5-TTS
Apply Whisper (#13)#
Transcrição automática para sua amostra de referência. Escolha um tamanho de Whisper que equilibre velocidade e precisão para seu hardware e idioma, então alimente o texto de saída no nó de clonagem para que o áudio e o texto estejam perfeitamente alinhados. Isso evita erros de condicionamento que podem acontecer quando o texto de amostra difere do que foi realmente falado. GitHub
VrchAudioRecorderNode (#43)#
Um gravador gráfico que captura um prompt falado curto para clonagem, removendo a necessidade de ferramentas externas. Segure para gravar, solte para parar e ouça imediatamente como o ComfyUI F5 TTS soa em sua própria voz. Mantenha o microfone perto e reduza o ruído ambiente para o resultado mais limpo.
Extras opcionais#
- Use de 5 a 15 segundos de fala limpa para a referência, sem música ou efeitos.
- Certifique-se de que a transcrição da amostra corresponda exatamente à gravação; mesmo pequenas incompatibilidades podem reduzir a fidelidade da clonagem.
- Compare Vocos e BigVGAN na mesma linha para decidir entre velocidade e detalhe.
- Mantenha uma semente fixa quando precisar de retomas consistentes; randomize ao explorar estilo.
- Para projetos multilíngues, teste primeiro as linhas EN, FR, DE e JP, depois finalize a clonagem quando estiver satisfeito com a pronúncia e o ritmo.
Agradecimentos#
Este fluxo de trabalho implementa e baseia-se nos seguintes trabalhos e recursos. Agradecemos a niknah pelo nó ComfyUI-F5-TTS, niknah pelo exemplo de fluxo de trabalho F5TTS-test-all.json, e a comunidade r/StableDiffusion pelo guia “Clonagem de Voz com F5-TTS no ComfyUI” por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- niknah/ComfyUI-F5-TTS
- GitHub: niknah/ComfyUI-F5-TTS
- niknah/ComfyUI-F5-TTS (Exemplo de Fluxo de Trabalho: F5TTS-test-all.json)
- r/StableDiffusion/Guia da Comunidade (Clonagem de Voz com F5-TTS no ComfyUI)
- GitHub: example_web_viewer_005_audio_web_viewer_f5_tts.json
- Documentação / Notas de Lançamento: Clone Sua Própria Voz Facilmente usando ComfyUI e Quase em Tempo Real! (Tutorial Passo a Passo & Fluxo de Trabalho Incluído)
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às licenças e termos respectivos fornecidos por seus autores e mantenedores.


