
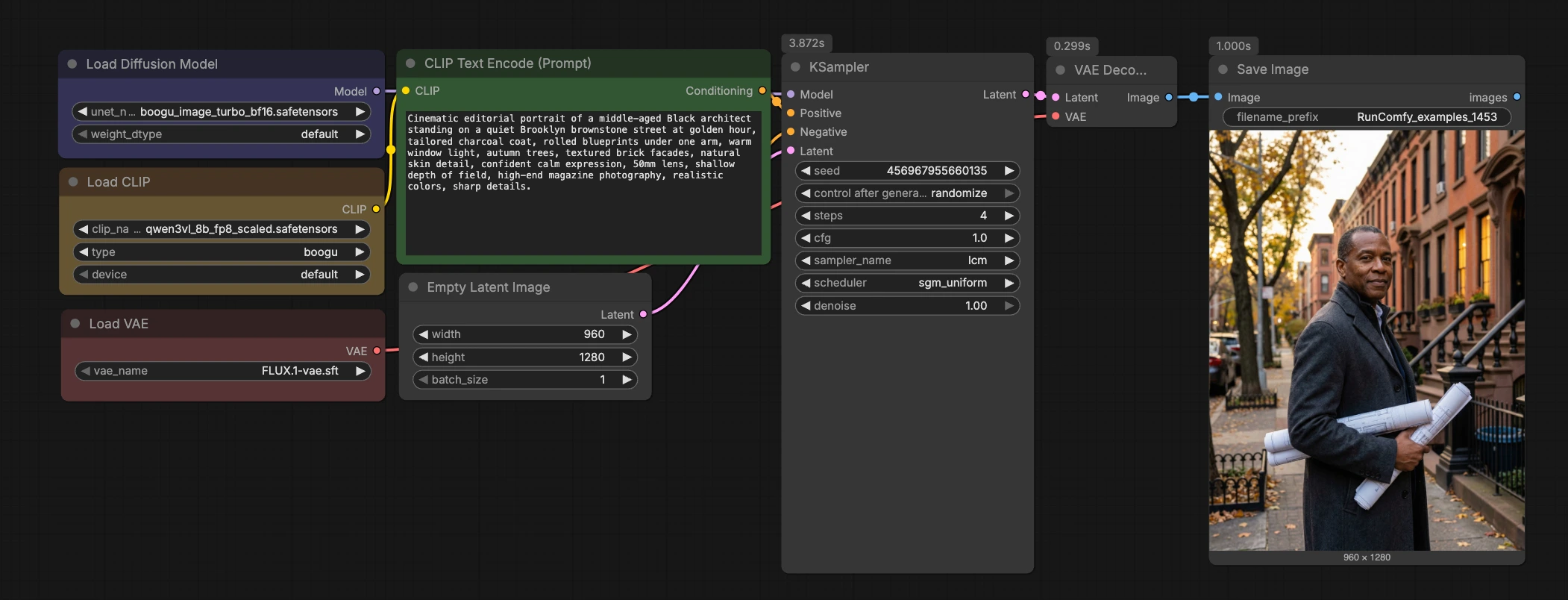






Boogu Turbo text-to-image ComfyUI workflow#
Este fluxo de trabalho Boogu Turbo text-to-image ComfyUI é um caminho limpo e rápido do prompt para a imagem usando o checkpoint Boogu-Image-0.1-Turbo com amostragem LCM de quatro etapas. Ele emparelha o codificador de texto Qwen3-VL com o FLUX.1 VAE para que você possa iterar rapidamente, mantendo o gráfico mínimo e fácil de reutilizar em projetos.
Projetado para exploração visual rápida, o fluxo de trabalho se destaca em ambientes cinematográficos, fundos no estilo anime, paisagens atmosféricas, máquinas de produtos imaginativas e cenas arquitetônicas. Se você deseja um fluxo de trabalho leve Boogu Turbo text-to-image ComfyUI que esteja pronto para RunComfy e seja simples de inspecionar, este modelo é um ponto de partida forte.
Modelos-chave no fluxo de trabalho Comfyui Boogu Turbo text-to-image ComfyUI#
- Boogu-Image-0.1-Turbo. A variante Turbo destilada é construída para texto-para-imagem fotorealista e rápida com inferência típica de 3–4 etapas e escala de orientação próxima a 1.0. Pesos de modelo oficiais e instruções estão disponíveis no Hugging Face, com arquivos reembalados prontos para ComfyUI fornecidos por Comfy-Org. Veja Boogu/Boogu-Image-0.1-Turbo-fp8 e o pacote ComfyUI curado em Comfy-Org/Boogu-Image.
- Codificador de texto Qwen3-VL 8B. Este backbone moderno de visão-linguagem é usado aqui puramente como um codificador de texto para produzir fortes embeddings de prompt para o modelo de difusão. Os codificadores empacotados para ComfyUI estão hospedados em Comfy-Org/Qwen3-VL e o repositório oficial é QwenLM/Qwen3-VL.
- FLUX.1 VAE. O autoencoder do Black Forest Labs codifica e decodifica imagens entre espaço de pixel e latente, ajudando a preservar a fidelidade de cor e contraste. Pesos de referência e documentação estão em black-forest-labs/FLUX.1-dev.
Como usar o fluxo de trabalho Comfyui Boogu Turbo text-to-image ComfyUI#
À primeira vista, o fluxo de trabalho codifica seu prompt, inicializa uma tela latente, executa um sampler LCM rápido através do Boogu-Image-0.1-Turbo, decodifica com o FLUX.1 VAE e salva o resultado. O gráfico é intencionalmente compacto para que você possa inseri-lo em outros projetos ou estendê-lo com LoRAs, ControlNets ou cadeias de pós-processamento.
Codificação de prompt com Qwen3-VL (CLIPLoader (#7) → CLIPTextEncode (#11))#
Esta etapa carrega um codificador Qwen3-VL e converte seu prompt de texto em vetores de condicionamento. Insira seu prompt em CLIPTextEncode (#11) usando linguagem natural; dicas fotográficas detalhadas como lente, iluminação, hora do dia e textura funcionam bem. A entrada negativa é intencionalmente zerada via ConditioningZeroOut (#9) para manter os resultados estáveis com o regime de baixa orientação do Turbo. Se preferir negativos explícitos, substitua ConditioningZeroOut por um segundo CLIPTextEncode para fornecer um prompt negativo. Uma boa higiene de prompt aqui reduz a necessidade de alta CFG ou etapas adicionais posteriormente.
Configuração latente e carregamento de modelo (EmptyLatentImage (#8) + UNETLoader (#2))#
EmptyLatentImage (#8) cria a tela latente. O padrão de retrato 960×1280 é um ponto de partida equilibrado para pessoas, interiores e fotos de produtos altos; você pode definir outros tamanhos para quadrados ou wides. UNETLoader (#2) carrega os pesos de difusão Boogu Turbo do pacote Comfy-Org, alinhando o modelo ao codificador e VAE escolhidos. A troca das variantes BF16 e FP8 é direta se você precisar equilibrar VRAM e throughput. Mantenha a escolha do modelo consistente em todo o seu projeto para manter a continuidade do estilo.
Amostragem rápida LCM (KSampler (#32) com sampler lcm)#
O KSampler é configurado para Modelos de Consistência Latente para alcançar alta qualidade em cerca de quatro etapas. A destilação LCM visa valores de orientação muito baixos, razão pela qual este fluxo de trabalho Boogu Turbo text-to-image ComfyUI opera de forma estável com CFG próximo a 1.0 enquanto preserva a adesão ao prompt. Se você quiser um pouco mais de microdetalhes, aumente as etapas modestamente e fixe a semente para comparações A/B. Para mudanças de estilo ou composição, re-embaralhe a semente e refine o prompt em vez de aumentar muito as etapas. A teoria de fundo sobre a inferência de poucas etapas LCM é descrita no artigo original Latent Consistency Models.
Decodificar e salvar (VAELoader (#5) → VAEDecode (#3) → SaveImage (#58))#
O FLUX.1 VAE carregado em VAELoader (#5) decodifica latentes para RGB em VAEDecode (#3). Combinar a família VAE com seu backbone de difusão geralmente resulta em cores e texturas mais fiéis, razão pela qual este gráfico vem com o FLUX.1 VAE. SaveImage (#58) grava os resultados no disco; altere o prefixo de saída para organizar experimentos por prompt, semente ou proporção. Se você posteriormente encadear upscalers ou pós-fx, ramifique a partir da saída Image de VAEDecode para preservar um histórico limpo.
Nós-chave no fluxo de trabalho Comfyui Boogu Turbo text-to-image ComfyUI#
CLIPTextEncode (#11)#
Este nó abriga seu prompt de texto principal e produz o condicionamento positivo usado pelo sampler. Mantenha os prompts concisos e adicione dicas de cena como comprimento focal da câmera, hora do dia e adjetivos de material. Se desejar usar prompts negativos, crie um segundo CLIPTextEncode e conecte-o à entrada negativa do sampler, removendo ConditioningZeroOut (#9).
ConditioningZeroOut (#9)#
Isso desativa o condicionamento negativo alimentando um vetor zero na porta negativa do sampler. Deixá-lo no lugar é um bom padrão para a configuração de baixa orientação do Turbo. Remova-o apenas quando você precisar especificamente de prompts negativos e puder articulá-los claramente.
EmptyLatentImage (#8)#
Controla as dimensões de saída e o tamanho do lote. Comece em 960×1280 para retratos ou 1280×960 para ambientes mais amplos; ajuste com base no assunto e no orçamento de memória. Latentes maiores fornecem mais tela para detalhes finos, mas aumentam o uso de VRAM e o tempo de decodificação.
UNETLoader (#2)#
Seleciona o checkpoint Boogu-Image-0.1-Turbo para usar na geração. Use a variante BF16 para maior fidelidade em GPUs capazes ou a variante FP8 para menor VRAM e carregamentos mais rápidos, ambas disponíveis no pacote Comfy-Org. Arquivos de modelo e suas pastas pretendidas estão documentados em Comfy-Org/Boogu-Image.
KSampler (#32)#
Executa o processo de difusão com o sampler lcm para inferência de poucas etapas. Os principais fatores são a semente, o número de etapas e CFG; o Turbo é projetado para funcionar com orientação muito baixa e poucas etapas, mantendo a qualidade, como refletido nas configurações oficiais do Turbo no cartão de modelo em Boogu/Boogu-Image-0.1-Turbo-fp8. Para explorações controladas, fixe a semente e varie as etapas ou a formulação do prompt uma mudança de cada vez.
VAELoader (#5) e VAEDecode (#3)#
Carregue e aplique o FLUX.1 VAE para decodificação. Permanecer com a família FLUX.1 mantém as cores, o contraste e o comportamento de textura consistentes com a configuração de treinamento do UNet. Misturar VAEs é possível, mas pode alterar sutilmente a tonalidade ou saturação; teste antes de se comprometer com um novo visual. Pesos de referência: black-forest-labs/FLUX.1-dev.
SaveImage (#58)#
Controla o nome e destino de saída. Use prefixos significativos como nome do projeto, tag de aspecto ou semente para manter as execuções organizadas. Ao expandir o pipeline, ramifique aqui para adicionar upscalers, gradação de cores ou legendadores sem interromper o salvamento base.
Extras opcionais#
- Mantenha o CFG próximo a 1.0 e as etapas em torno de quatro para iterações mais rápidas; mova para 6–8 etapas apenas quando precisar de um pouco mais de textura ou estabilidade.
- Re-embaralhe a semente para explorar a composição; fixe a semente para refinar estilo e microdetalhes.
- Prefira pesos BF16 para melhor qualidade em GPUs de alta memória; mude para FP8 para acelerar o carregamento e reduzir VRAM.
- Para legibilidade de texto em imagem, tente uma resolução ligeiramente maior e inclua dicas tipográficas explícitas no prompt.
- Salve favoritos intermediários com frequência; pequenos ajustes de prompt neste fluxo de trabalho Boogu Turbo text-to-image ComfyUI podem produzir cenas significativamente diferentes em segundos.
Agradecimentos#
Este fluxo de trabalho implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos a RunningHub pela referência de fluxo de trabalho, Boogu pelo repositório Boogu-Image e o modelo Boogu-Image-0.1-Turbo, Comfy-Org pelos pesos Boogu ComfyUI e ComfyUI pelo tutorial Boogu por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- RunningHub/Referência de fluxo de trabalho
- Docs / Notas de Lançamento: RunningHub post
- Boogu/Site do projeto
- Docs / Notas de Lançamento: boogu.org
- Boogu/Repositório de Imagem Boogu
- GitHub: boogu-project/Boogu-Image
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- Boogu/Modelo Boogu-Image-0.1-Turbo
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- GitHub: boogu-project/Boogu-Image
- Comfy-Org/Pesos Boogu ComfyUI
- Hugging Face: Comfy-Org/Boogu-Image
- ComfyUI/Tutorial Boogu
- Docs / Notas de Lançamento: ComfyUI tutorial
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.



