
Tutorial del Flusso di Lavoro#
Wan 2.2 Animate: Swap Characters & Lip-Sync#
Sostituisci qualsiasi relatore in video con il tuo personaggio mantenendo allineati movimento, espressioni e forme della bocca all'audio originale. Questo flusso di lavoro ComfyUI, costruito attorno a Wan 2.2 Animate: Swap Characters & Lip-Sync, rileva la posa del corpo e i fotogrammi del viso da un video di input, li ritargetta su una singola immagine di riferimento e rende un risultato coerente e sincronizzato con il discorso.
Il flusso di lavoro è adatto per editor, creatori e ricercatori che desiderano una sostituzione affidabile dei personaggi per interviste, reel, VTubing, slide o cortometraggi doppiati. Fornisci una clip sorgente e un'immagine di riferimento pulita; la pipeline ricrea la posa e l'articolazione delle labbra sul nuovo personaggio e miscela la colonna sonora originale nel risultato finale.
Modelli chiave nel flusso di lavoro Comfyui Wan 2.2 Animate: Swap Characters & Lip-Sync#
- Wan 2.2 Animate 14B (FP8 scalato): il generatore video principale che sintetizza il personaggio ritargettato attraverso i fotogrammi utilizzando segnali di posa, viso e contesto. Model hub
- Wan 2.1 VAE (bf16): codifica/decodifica i latenti video utilizzati da Wan durante il campionamento e l'output. Weights
- UMT5‑XXL Text Encoder (bf16): costruisce embedding di testo per suggerimenti leggeri o descrittori di ripresa. Weights
- CLIP Vision H: estrae caratteristiche robuste dell'immagine dal ritratto di riferimento per preservare l'identità. Weights
- Lightx2v I2V 14B LoRA: migliora la stabilità e la fedeltà immagine‑video quando si guida con fotogrammi di riferimento. LoRA
- Wan22 Relight LoRA: aiuta a mantenere ombreggiatura e rilighting coerenti lungo il fotogramma. LoRA
- YOLOv10m (ONNX): rilevamento veloce di persone/volti utilizzato prima della stima delle pose. Model
- ViTPose WholeBody Large (ONNX): punti chiave scheletrici di alta qualità per il trasferimento del movimento su tutto il corpo. Model
- Segment Anything 2.1: segmentazione per maschere di primo piano pulite che guidano la sostituzione. Repo
Come utilizzare il flusso di lavoro Comfyui Wan 2.2 Animate: Swap Characters & Lip-Sync#
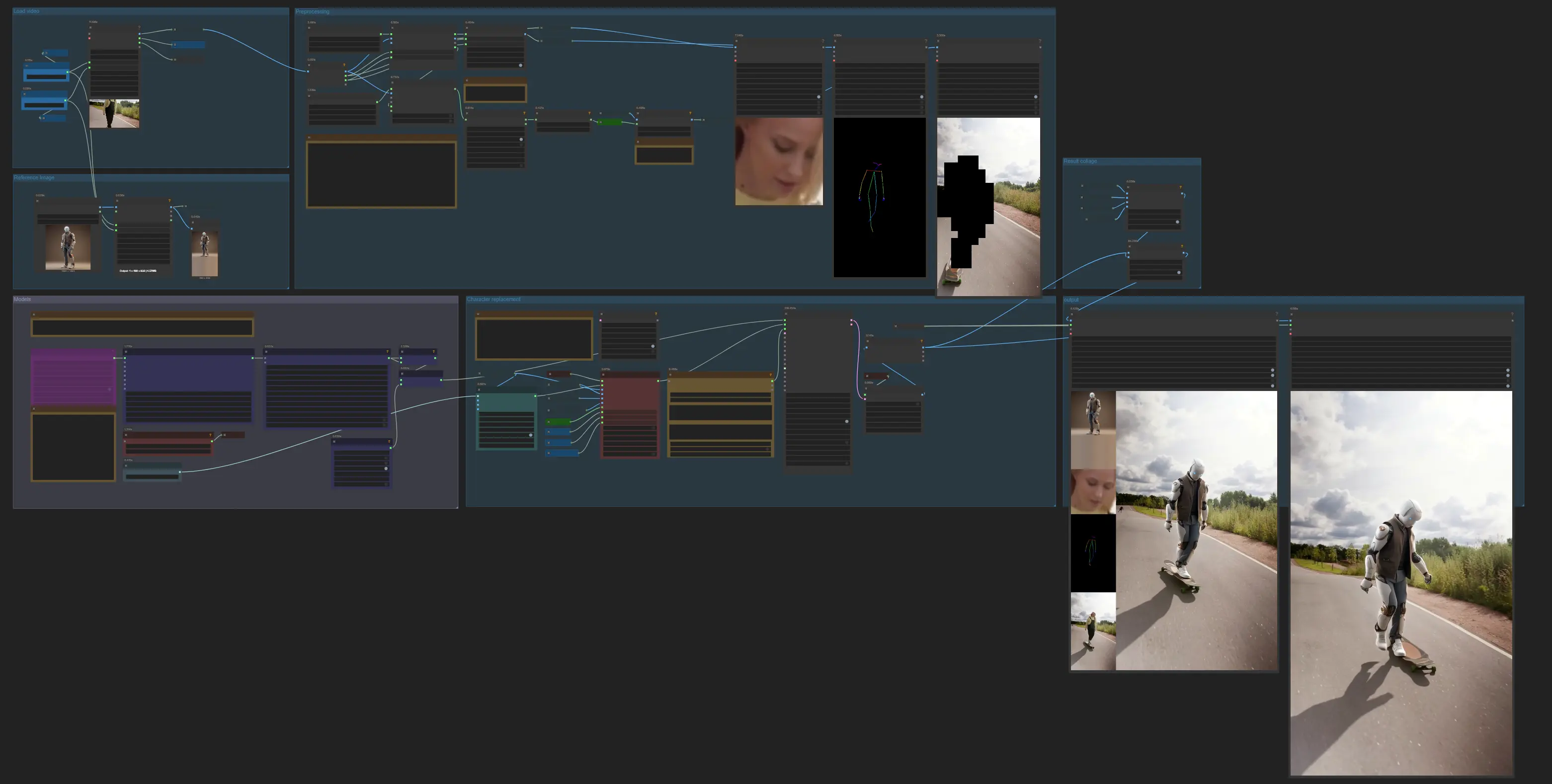
Il grafico si muove attraverso sette gruppi: caricare gli input, costruire un riferimento, preprocessare pose/viso e maschere, caricare modelli di generazione, eseguire la sostituzione del personaggio, visualizzare le diagnosi, quindi esportare con l'audio.
Carica video#
Importa la tua clip sorgente con VHS_LoadVideo (#63). Il nodo espone larghezza/altezza opzionali per il ridimensionamento e produce fotogrammi video, audio e conteggio dei fotogrammi per l'uso a valle. Tieni la clip tagliata vicino alla parte parlante se desideri un'elaborazione più veloce. L'audio viene passato all'esportatore in modo che il video finale rimanga allineato alla colonna sonora originale.
Immagine di riferimento#
Fornisci un ritratto singolo e pulito del personaggio target. L'immagine viene ridimensionata con ImageResizeKJv2 (#64) per adattarsi alla tua risoluzione di lavoro e memorizzata come riferimento canonico utilizzato da CLIP Vision e dal generatore. Preferisci un'immagine nitida, frontale sotto illuminazione simile al tuo scatto sorgente per ridurre la deriva di colore e ombreggiatura.
Preelaborazione#
OnnxDetectionModelLoader (#178) carica YOLO e ViTPose, quindi PoseAndFaceDetection (#172) analizza ciascun fotogramma per produrre punti chiave su tutto il corpo e ritagli del viso per fotogramma. Sam2Segmentation (#104) crea una maschera di primo piano utilizzando sia riquadri di delimitazione rilevati che punti chiave; se un suggerimento fallisce, passa all'altro per una separazione migliore. La maschera è affinata con GrowMaskWithBlur (#182) e bloccatizzata con BlockifyMask (#108) per dare al generatore una regione del soggetto stabile e non ambigua. Sovrapposizioni opzionali (DrawViTPose (#173) e DrawMaskOnImage (#99)) ti aiutano a verificare visivamente la copertura della posa e la qualità della maschera prima della generazione.
Modelli#
WanVideoModelLoader (#22) carica Wan 2.2 Animate 14B, e WanVideoVAELoader (#38) fornisce il VAE. Le caratteristiche di identità dal ritratto di riferimento sono codificate da CLIPVisionLoader (#71) e WanVideoClipVisionEncode (#70). Stile e stabilità sono regolati con WanVideoLoraSelectMulti (#171), mentre WanVideoSetLoRAs (#48) e WanVideoSetBlockSwap (#50) applicano LoRAs e impostazioni di blocco-swap al modello; questi strumenti provengono dalla libreria wrapper Wan. Vedi ComfyUI‑WanVideoWrapper per i dettagli sull'implementazione.
Sostituzione del personaggio#
WanVideoTextEncodeCached (#65) accetta un breve prompt descrittivo se desideri influenzare l'aspetto o l'umore del fotogramma. WanVideoAnimateEmbeds (#62) fonde l'immagine di riferimento, la posa per fotogramma, i ritagli del viso, lo sfondo e la maschera in embedding di immagine che preservano l'identità mentre abbinano il movimento e le forme della bocca. WanVideoSampler (#27) quindi rende i fotogrammi; il suo scheduler e i passaggi controllano il compromesso nitidezza-movimento. I fotogrammi decodificati da WanVideoDecode (#28) vengono consegnati agli ispettori di dimensioni/conteggio in modo da poter confermare le dimensioni prima dell'esportazione.
Collage di risultati#
Per una rapida QA, il flusso di lavoro concatena gli input chiave con ImageConcatMulti (#77, #66) per formare una semplice striscia di confronto del riferimento, ritagli del viso, visualizzazione della posa e un fotogramma grezzo. Usalo per controllare la sanità dei segnali identitari e delle forme della bocca subito dopo un test.
Output#
VHS_VideoCombine (#30) produce il video finale e miscela l'audio originale per una tempistica perfetta. Sono inclusi esportatori aggiuntivi in modo da poter salvare diagnosi intermedie o tagli alternativi se necessario. Per i migliori risultati su clip più lunghe, esporta prima un test breve, quindi itera su mix di LoRA e maschere prima di impegnarti in un rendering completo.
Nodi chiave nel flusso di lavoro Comfyui Wan 2.2 Animate: Swap Characters & Lip-Sync#
VHS_LoadVideo (#63) Carica fotogrammi e l'audio originale in un solo passaggio. Usalo per impostare una risoluzione di lavoro che si adatti al tuo budget GPU e per confermare il conteggio dei fotogrammi che i nodi a valle consumeranno. Da ComfyUI‑VideoHelperSuite.
PoseAndFaceDetection (#172) Esegue YOLO e ViTPose per estrarre riquadri di persone, punti chiave su tutto il corpo e ritagli del viso per fotogramma. Buoni punti chiave sono la spina dorsale di un trasferimento di movimento credibile e sono riutilizzati direttamente per l'articolazione delle labbra. Da ComfyUI‑WanAnimatePreprocess.
Sam2Segmentation (#104) Costruisce una maschera di primo piano attorno al soggetto utilizzando sia riquadri di delimitazione che suggerimenti di punti chiave. Se capelli o mani vengono persi, cambia tipo di suggerimento o espandi le impostazioni di sfocatura/crescita prima di bloccare. Da ComfyUI‑segment‑anything‑2.
WanVideoLoraSelectMulti (#171) Ti permette di mescolare LoRA come Lightx2v e Wan22 Relight per bilanciare la stabilità del movimento, la coerenza dell'illuminazione e la forza dell'identità. Aumenta il peso di un LoRA per avere più influenza, ma attenzione a non sovra-stilizzare i volti. Da ComfyUI‑WanVideoWrapper.
WanVideoAnimateEmbeds (#62) Combina il ritratto di riferimento, le immagini di posa, i ritagli del viso, i fotogrammi di sfondo e la maschera in una rappresentazione compatta che condiziona Wan 2.2 Animate. Assicurati che width, height e num_frames corrispondano al tuo export previsto per evitare artefatti di ricampionamento. Da ComfyUI‑WanVideoWrapper.
WanVideoSampler (#27) Genera i fotogrammi finali. Usa passaggi più alti e uno scheduler più stabile quando hai bisogno di dettagli più nitidi, o un programma più leggero per anteprime veloci. Per clip molto lunghe, puoi opzionalmente introdurre controlli di finestra di contesto collegando WanVideoContextOptions (#110) per mantenere la coerenza temporale tra le finestre.
VHS_VideoCombine (#30) Esporta il video finito e miscela l'audio originale in modo che i movimenti delle labbra rimangano sincronizzati. L'opzione trim-to-audio mantiene la durata allineata con la colonna sonora. Da ComfyUI‑VideoHelperSuite.
Extra opzionali#
- Usa un riferimento nitido e frontale con labbra neutrali per il trasferimento di identità più pulito; evita trucco pesante o occlusioni.
- Se la segmentazione perde capelli o accessori, prova a cambiare i suggerimenti
Sam2Segmentationtra riquadri di delimitazione e punti chiave, quindi fai crescere leggermente la maschera prima di bloccare. - Lightx2v LoRA migliora la stabilità I2V; Wan22 Relight LoRA aiuta a corrispondere l'illuminazione incoerente. Piccoli cambiamenti di peso possono risolvere il tremolio senza sovra-cucinare un aspetto.
- Il blocco-swap può ridurre la deriva dell'identità su lunghe riprese; se i volti si ammorbidiscono nel tempo, abilitalo in
WanVideoSetBlockSwap(#50) e ritesta. - Mantieni la risoluzione di lavoro proporzionale alla sorgente per evitare distorsioni dell'aspetto; aumenta solo quando l'immagine di riferimento è sufficientemente dettagliata per supportarlo.
- Per runtime capaci, abilitare la compilazione torch e l'attenzione efficiente nei nodi wrapper può accelerare il campionamento; vedi ComfyUI‑WanVideoWrapper per guida.
Questo flusso di lavoro Wan 2.2 Animate: Swap Characters & Lip-Sync offre trasferimenti di movimento coerenti e forme della bocca sincronizzate con il discorso con un setup minimo, rendendo gli scambi di personaggi di alta qualità veloci e ripetibili all'interno di ComfyUI.
Ringraziamenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo di cuore @MDMZ per aver costruito l'intero flusso di lavoro, Kijai per WAN 2.2 Animate e i relativi nodi ComfyUI, Wan-AI per le risorse Wan2.2-Animate inclusi il rilevamento YOLOv10m, e Comfy-Org per il modello Wan 2.1 Clip Vision per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Tutorial del Flusso di Lavoro
- Youtube: ComfyUI-Tutorial from @MDMZ
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.