
Hunyuan Video è un modello di base open-source che sfida il dominio dei sistemi closed-source offrendo capacità all'avanguardia di generazione di video da testo. Basato su innovazioni nella cura dei dati su larga scala, nel design architettonico adattivo e nell'infrastruttura ottimizzata, Hunyuan Video stabilisce nuovi standard di qualità visiva.
Sebbene Hunyuan Video si concentri principalmente sulla generazione di video da testo, il flusso di lavoro Hunyuan IP2V estende questa capacità convertendo immagine e prompt di testo in video dinamico attraverso lo stesso modello. Questo approccio consente agli utenti di guidare la creazione di contenuti utilizzando riferimenti visivi, offrendo un metodo alternativo per la produzione di contenuti guidata dall'AI.
Combinando un'immagine con un prompt, Hunyuan IP2V genera movimento preservando le caratteristiche chiave dell'input, rendendolo uno strumento utile per l'animazione AI, la visualizzazione di concetti e la narrazione artistica. Che si tratti di creare scene dinamiche, movimenti stilizzati o estendere visivi statici in sequenze animate, il framework di Hunyuan Video offre percorsi efficienti per risultati di alta qualità.
Come utilizzare il flusso di lavoro Hunyuan Video - IP2V?#
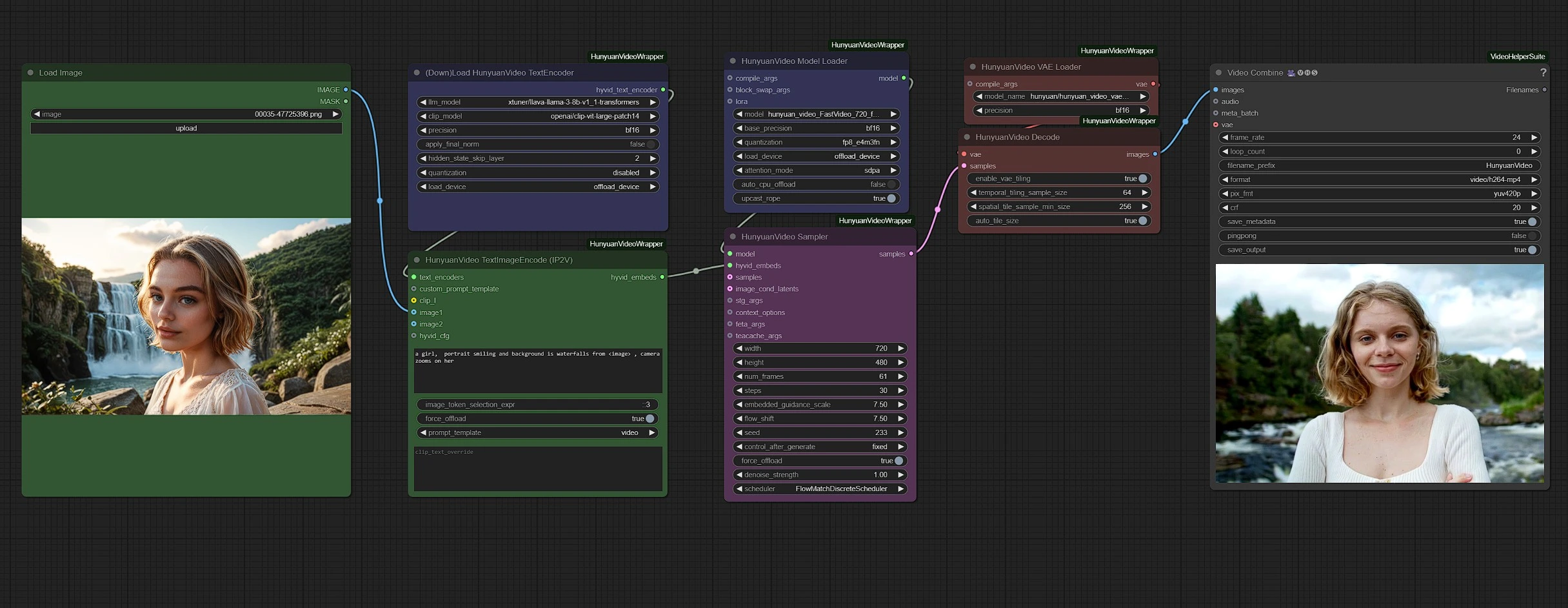
I gruppi sono codificati a colori per chiarezza:
- Verde - Input
- Viola - Modelli
- Rosa - Hunyuan Sampler
- Rosso - VAE + Decodifica
- Grigio - Output
Carica i tuoi input (immagine e testo) nei nodi verdi e regola le impostazioni video, come durata e risoluzione, nel nodo campionatore rosa.
Input 1 - Immagine#
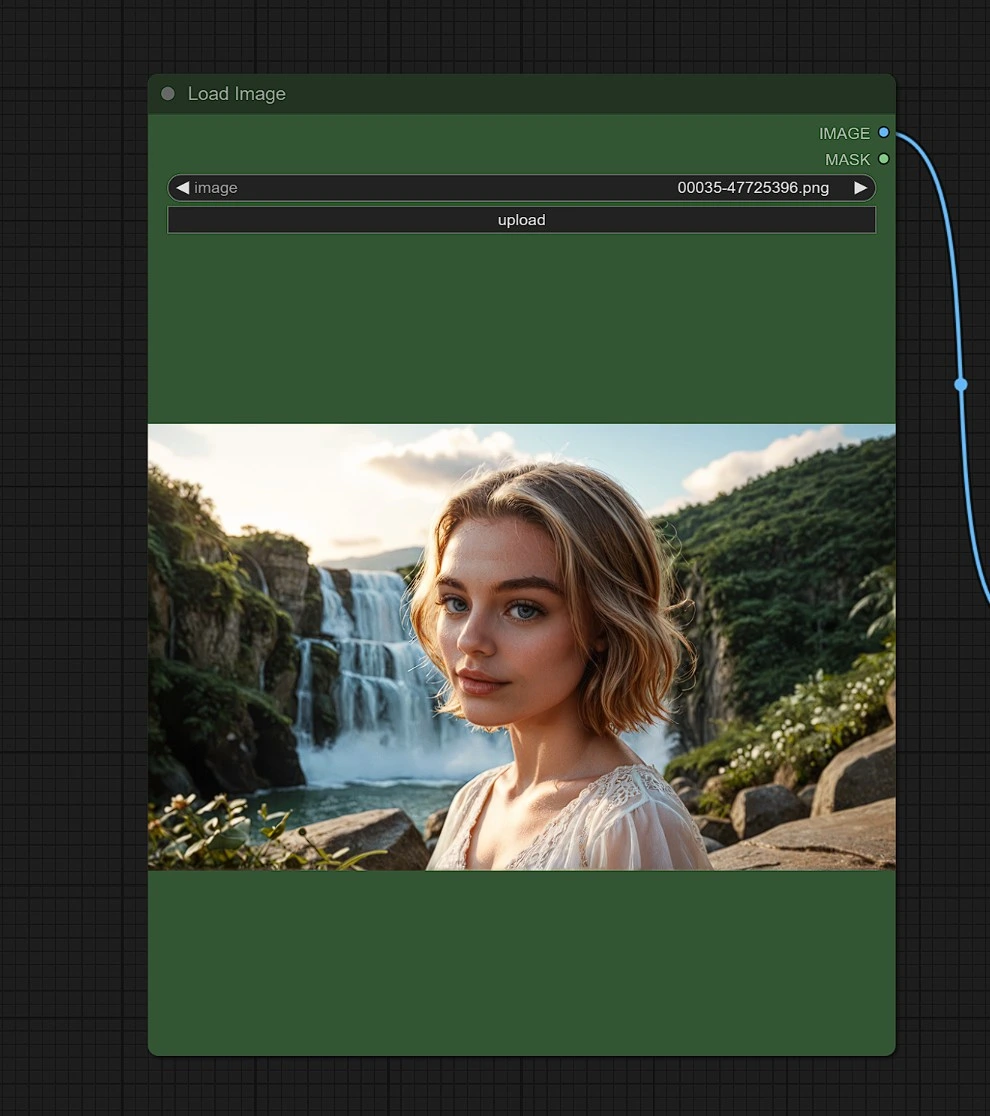
Carica un'immagine di riferimento del luogo, persona o oggetto per il quale desideri risultati simili.
Input 2 - Testo#
Nella prima casella di testo, inserisci i tuoi prompt e includi l'immagine utilizzando la parola chiave "<image>".
Ad esempio, se il tuo input è "strada vuota" e vuoi aggiungere una donna, il prompt sarebbe: "Un ritratto di una donna, lo sfondo è <image>."
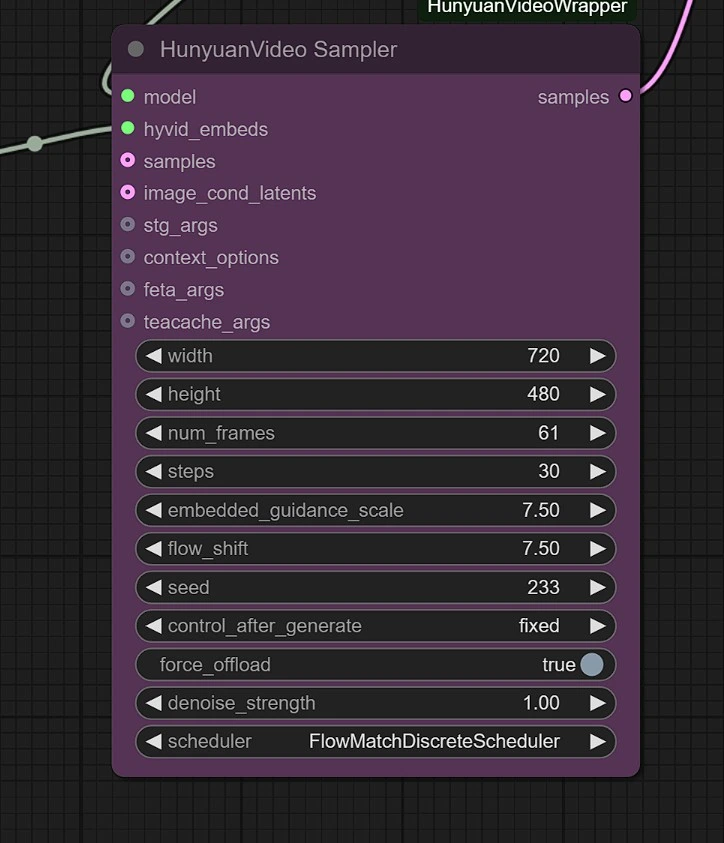
Sampler#
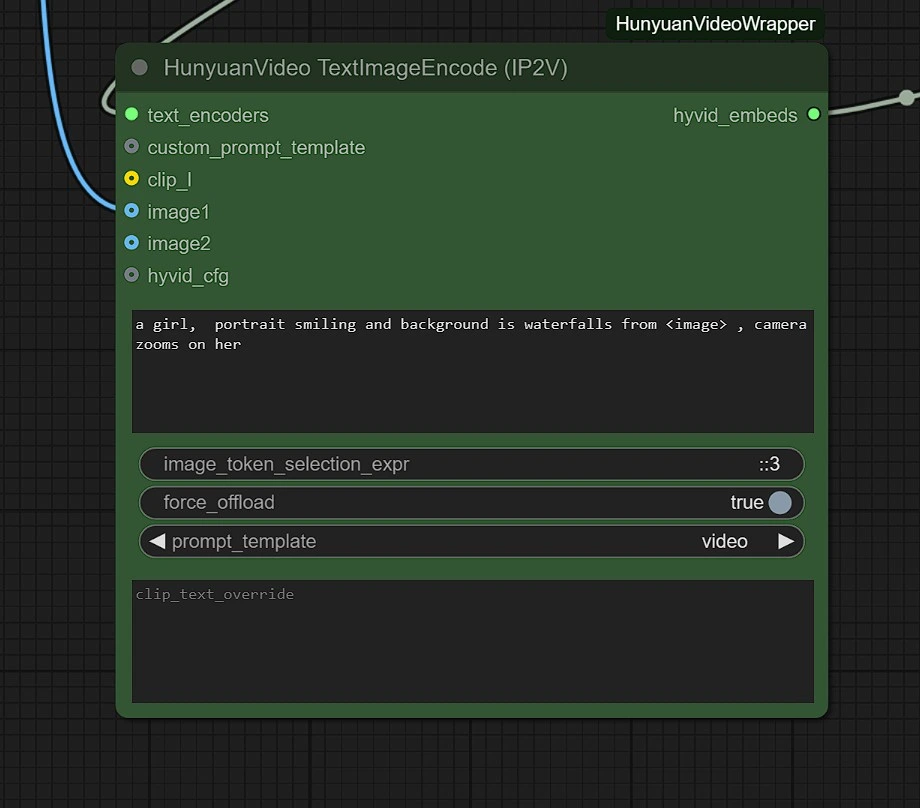
Puoi regolare quanto segue:
- Risoluzione dell'immagine - Massimo è 1280px 720px , richiedendo più VRAM.
- Frame - Questo imposta il numero di frame (24 frame = 1 secondo).
Modelli#
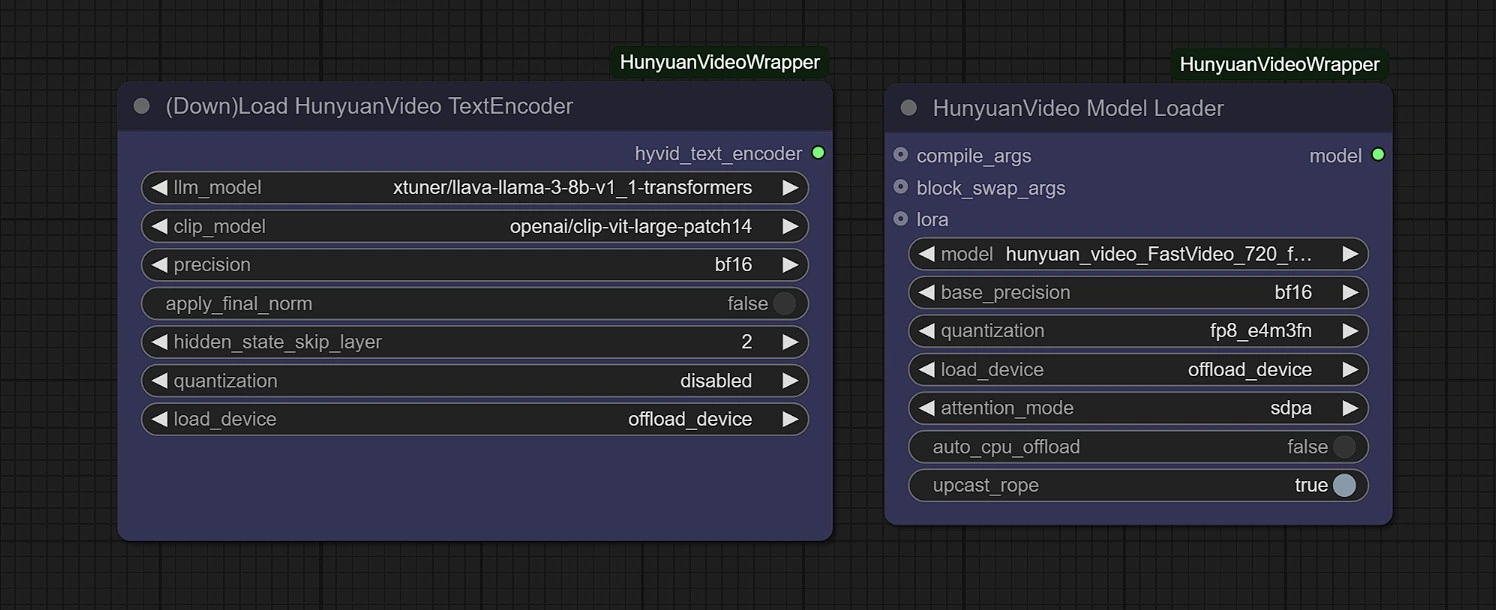
In questo gruppo, i modelli verranno scaricati automaticamente al primo avvio. Si prega di attendere 3-5 minuti per il completamento del download nel tuo storage temporaneo.
Link:
- Diffusione: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors
- ComfyUI > modelli > diffusion_models
- Vae: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_vae_bf16.safetensors
- ComfyUI > modelli > vae
Output#
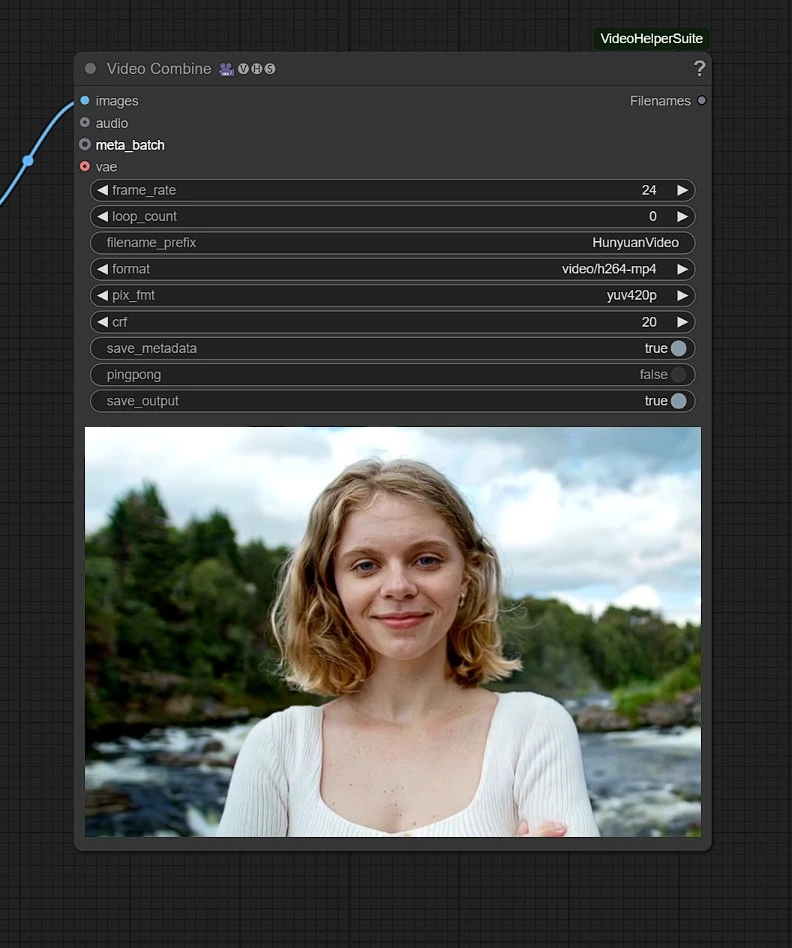
Il video renderizzato verrà salvato nella cartella Outputs in Comfyui.
Con il flusso di lavoro Hunyuan IP2V, non sei più limitato alla generazione di video basati su testo, ora puoi dare vita alle tue immagini con movimento e stile. Che si tratti di film-making AI, arte digitale o narrazione creativa, questo flusso di lavoro ti dà il potere di modellare la tua visione con più controllo che mai.