
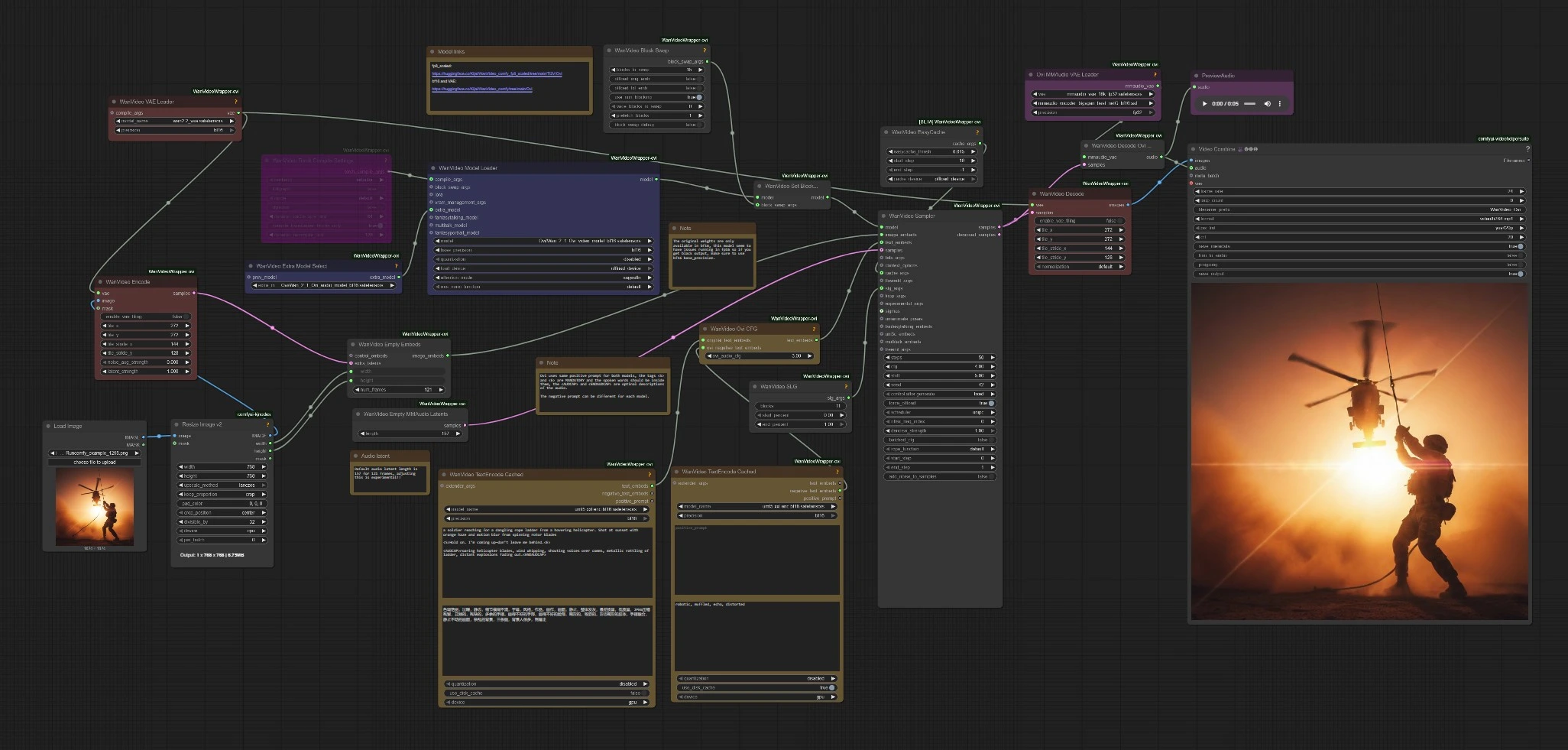
Character AI Ovi: immagine in video con discorso sincronizzato in ComfyUI#
Character AI Ovi è un workflow di generazione audiovisiva che trasforma un'unica immagine in un personaggio parlante e in movimento con suono coordinato. Basato sulla famiglia di modelli Wan e integrato tramite WanVideoWrapper, genera video e audio in un unico passaggio, offrendo animazioni espressive, sincronizzazione labiale intelligibile e un'atmosfera consapevole del contesto. Se crei racconti brevi, host virtuali o clip sociali cinematografici, Character AI Ovi ti permette di passare dall'arte statica a una performance completa in pochi minuti.
Questo workflow ComfyUI accetta un'immagine più un prompt testuale contenente un markup leggero per il discorso e il design del suono. Compone insieme fotogrammi e forme d'onda in modo che la bocca, la cadenza e l'audio della scena sembrino naturalmente allineati. Character AI Ovi è progettato per i creatori che vogliono risultati raffinati senza unire strumenti TTS e video separati.
Modelli chiave nel workflow Comfyui Character AI Ovi#
- Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation. Il modello principale che produce congiuntamente video e audio da prompt testuali o testo+immagine. character-ai/Ovi
- Wan 2.2 video backbone and VAE. Il workflow utilizza il VAE video ad alta compressione di Wan per generazioni efficienti a 720p, 24 fps, preservando i dettagli e la coerenza temporale. Wan-AI/Wan2.2-TI2V-5B-Diffusers • Wan-Video/Wan2.2
- Google UMT5-XXL text encoder. Codifica il prompt, inclusi i tag del discorso, in ricche rappresentazioni multilingue che guidano entrambi i rami. google/umt5-xxl
- MMAudio VAE with BigVGAN vocoder. Decodifica i latenti audio del modello in discorsi di alta qualità ed effetti con timbro naturale. hkchengrex/MMAudio • nvidia/bigvgan_v2_44khz_128band_512x
- ComfyUI-ready Ovi weights by Kijai. Checkpoint curati per il ramo video, ramo audio e VAE in varianti scalate bf16 e fp8. Kijai/WanVideo_comfy/Ovi • Kijai/WanVideo_comfy_fp8_scaled/TI2V/Ovi
- WanVideoWrapper nodes for ComfyUI. Wrapper che espone le funzionalità di Wan e Ovi come nodi componibili. kijai/ComfyUI-WanVideoWrapper
Come usare il workflow Comfyui Character AI Ovi#
Questo workflow segue un percorso semplice: codifica il tuo prompt e l'immagine, carica i checkpoint di Ovi, campiona i latenti audio+video congiunti, poi decodifica e mux in MP4. Le sottosezioni seguenti mappano i cluster di nodi visibili in modo che tu sappia dove interagire e quali cambiamenti influenzano i risultati.
Creazione di prompt per discorso e suono#
Scrivi un prompt positivo per la scena e la linea parlata. Usa i tag Ovi esattamente come mostrato: avvolgi le parole da pronunciare con <S> e <E>, e descrivi opzionalmente l'audio non parlato con <AUDCAP> e <ENDAUDCAP>. Lo stesso prompt positivo condiziona sia il ramo video che audio, così il movimento delle labbra e il tempismo si allineano. Puoi usare diversi prompt negativi per video e audio per sopprimere artefatti indipendentemente. Character AI Ovi risponde bene a indicazioni di scena concise più una singola linea di dialogo chiara.
Ingestione e condizionamento dell'immagine#
Carica un singolo ritratto o immagine del personaggio, quindi il workflow ridimensiona e codifica nei latenti. Ciò stabilisce l'identità, la posa e l'inquadratura iniziale per il campionatore. Larghezza e altezza dalla fase di ridimensionamento impostano l'aspetto del video; scegli quadrato per avatar o verticale per cortometraggi. I latenti codificati e gli embed derivati dall'immagine guidano il campionatore in modo che il movimento sembri ancorato al volto originale.
Caricamento del modello e aiuti alle prestazioni#
Character AI Ovi carica tre elementi essenziali: il modello video Ovi, il VAE Wan 2.2 per i fotogrammi e il VAE MMAudio più BigVGAN per l'audio. La compilazione Torch e una cache leggera sono incluse per velocizzare i riscaldamenti. Un aiuto di scambio di blocco è collegato per ridurre l'uso di VRAM scaricando i blocchi del trasformatore quando necessario. Se sei vincolato dalla VRAM, aumenta lo scarico dei blocchi nel nodo di scambio di blocco e mantieni la cache abilitata per esecuzioni ripetute.
Campionamento congiunto con guida#
Il campionatore esegue i backbones gemelli di Ovi insieme in modo che la colonna sonora e i fotogrammi si evolvano insieme. Un aiuto di guida a strati salta migliora la stabilità e i dettagli senza sacrificare il movimento. Il workflow instrada anche i tuoi embedding di testo originali attraverso un mixer CFG specifico per Ovi in modo da poter inclinare l'equilibrio tra aderenza rigorosa al prompt e animazione più libera. Character AI Ovi tende a produrre il miglior movimento delle labbra quando la linea parlata è breve, letterale e racchiusa solo dai tag <S> e <E>.
Decodifica, anteprima ed esportazione#
Dopo il campionamento, i latenti video vengono decodificati tramite il VAE Wan mentre i latenti audio vengono decodificati tramite MMAudio con BigVGAN. Un combinatore video muxa i fotogrammi e l'audio in un MP4 a 24 fps, pronto per la condivisione. Puoi anche visualizzare in anteprima l'audio direttamente per verificare l'intelligibilità del discorso prima di salvare. Il percorso predefinito di Character AI Ovi punta a 5 secondi; estendilo con cautela per mantenere le labbra e la cadenza sincronizzate.
Nodi chiave nel workflow Comfyui Character AI Ovi#
WanVideoTextEncodeCached(#85)
Codifica il prompt principale positivo e il prompt negativo video in embedding utilizzati da entrambi i rami. Mantieni il dialogo all'interno di <S>…<E> e posiziona il design del suono all'interno di <AUDCAP>…<ENDAUDCAP>. Per il miglior allineamento, evita più frasi in un tag di discorso e mantieni la linea concisa.
WanVideoTextEncodeCached(#96)
Fornisce un embedding di testo negativo dedicato per l'audio. Usalo per sopprimere artefatti come il tono robotico o la forte riverberazione senza influenzare i visivi. Inizia con descrittori brevi e espandi solo se senti ancora il problema.
WanVideoOviCFG(#94)
Miscelare gli embedding di testo originali con i negativi specifici per l'audio tramite una guida libera da classificazione consapevole di Ovi. Alzalo quando il contenuto del discorso si discosta dalla linea scritta o i movimenti delle labbra sembrano fuori luogo. Abbassalo leggermente se il movimento diventa rigido o troppo vincolato.
WanVideoSampler(#80)
Il cuore di Character AI Ovi. Consuma embed di immagini, embed di testo congiunti e guida opzionale per campionare un singolo latente che contiene sia video che audio. Più passaggi aumentano la fedeltà ma anche il tempo di esecuzione. Se vedi pressione di memoria o blocchi, abbina un maggiore scambio di blocco con cache attivata e considera di disabilitare la compilazione torch per una rapida risoluzione dei problemi.
WanVideoEmptyMMAudioLatents(#125)
Inizializza la timeline dei latenti audio. La lunghezza predefinita è sintonizzata per un clip di 121 fotogrammi a 24 fps. Modificare questo per cambiare la durata è sperimentale; cambialo solo se comprendi come deve seguire il conteggio dei fotogrammi.
VHS_VideoCombine(#88)
Muxa fotogrammi decodificati e audio in MP4. Imposta il frame rate per corrispondere al tuo target di campionamento e attiva trim-to-audio se vuoi che il taglio finale segua la forma d'onda generata. Usa il controllo CRF per bilanciare dimensione del file e qualità.
Extra opzionali#
- Usa bf16 per video Ovi e Wan 2.2 VAE. Se incontri fotogrammi neri, passa la precisione di base a
bf16per i caricamenti del modello e l'encoder di testo. - Mantieni i discorsi brevi. Character AI Ovi sincronizza le labbra più affidabilmente con dialoghi brevi e a frase singola all'interno di
<S>e<E>. - Separa i negativi. Inserisci artefatti visivi nel prompt negativo video e artefatti tonali nel prompt negativo audio per evitare compromessi indesiderati.
- Anteprima prima. Usa l'anteprima audio per confermare la chiarezza e il ritmo prima di esportare l'MP4 finale.
- Ottieni i pesi esatti usati. Il workflow si aspetta i checkpoint video e audio di Ovi più il VAE Wan 2.2 dai mirror dei modelli di Kijai. WanVideo_comfy/Ovi • WanVideo_comfy_fp8_scaled/TI2V/Ovi
Con questi elementi in posizione, Character AI Ovi diventa una pipeline compatta e amichevole per i creatori per avatar parlanti espressivi e scene narrative che suonano bene quanto appaiono.
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo kijai e Character AI per Ovi per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Character AI Ovi Source
- Workflow: wanvideo_2_2_5B_ovi_testing @kijai
- Github: character-ai/Ovi
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
