
Wan 2.2 Animate V2 pose-gesteuerter Videoerzeugungs-Workflow für ComfyUI#
Wan 2.2 Animate V2 ist ein pose-gesteuerter Videoerzeugungs-Workflow, der ein einzelnes Referenzbild plus ein steuerndes Posen-Video in eine lebensechte, identitätsbewahrende Animation verwandelt. Es baut auf der ersten Version auf mit höherer Treue, flüssigeren Bewegungen und besserer zeitlicher Konsistenz, während es die Ganzkörperbewegung und Ausdrücke des Quellvideos genau verfolgt.
Dieser ComfyUI-Workflow ist für Kreative gedacht, die schnelle, zuverlässige Ergebnisse für Charakteranimationen, Tanzclips und performance-gesteuertes Geschichtenerzählen wünschen. Er kombiniert robuste Vorverarbeitung (Pose, Gesicht und Subjektmaskierung) mit der Wan 2.2 Modellfamilie und optionalen LoRAs, sodass Sie Stil, Beleuchtung und Hintergrundbehandlung mit Vertrauen einstellen können.
Schlüsselmodelle im ComfyUI Wan 2.2 Animate V2 Workflow#
- Wan 2.2 Animate 14B. Kern-Videodiffusionsmodell, das zeitlich konsistente Frames aus multimodalen Einbettungen synthetisiert. Gewichte: Kijai/WanVideo_comfy_fp8_scaled (Wan22Animate).
- Wan 2.1 VAE. Latenter Video-Decoder/Encoder, den die Wan-Familie verwendet, um RGB-Frames mit minimalem Verlust zu rekonstruieren. Gewichte: Wan2_1_VAE_bf16.safetensors.
- UMT5-XXL Text-Encoder. Kodiert Aufforderungen, die Aussehen, Szene und Kinematik leiten. Gewichte: umt5-xxl-enc-bf16.safetensors.
- CLIP Vision (ViT-H/14). Extrahiert identitätsbewahrende Merkmale aus dem Referenzbild. Papier: CLIP.
- ViTPose Whole-Body (ONNX). Schätzt dichte Körper-Schlüsselstellen, die die Bewegungsübertragung steuern. Modelle: ViTPose-L WholeBody und ViTPose-H WholeBody. Papier: ViTPose.
- YOLOv10 Detektor. Liefert Personenboxen zur Stabilisierung der Posedetektion und Segmentierung. Beispiel: yolov10m.onnx.
- Segment Anything 2. Hochwertige Subjektmasken für Hintergrundbewahrung, Compositing oder Relighting-Vorschauen. Repo: facebookresearch/segment-anything-2.
- Optionale LoRAs für Stil und Lichttransport. Nützlich für Relighting und Texturdetails in Wan 2.2 Animate V2 Ausgaben. Beispiele: Lightx2v und Wan22_relight.
Wie man den ComfyUI Wan 2.2 Animate V2 Workflow verwendet#
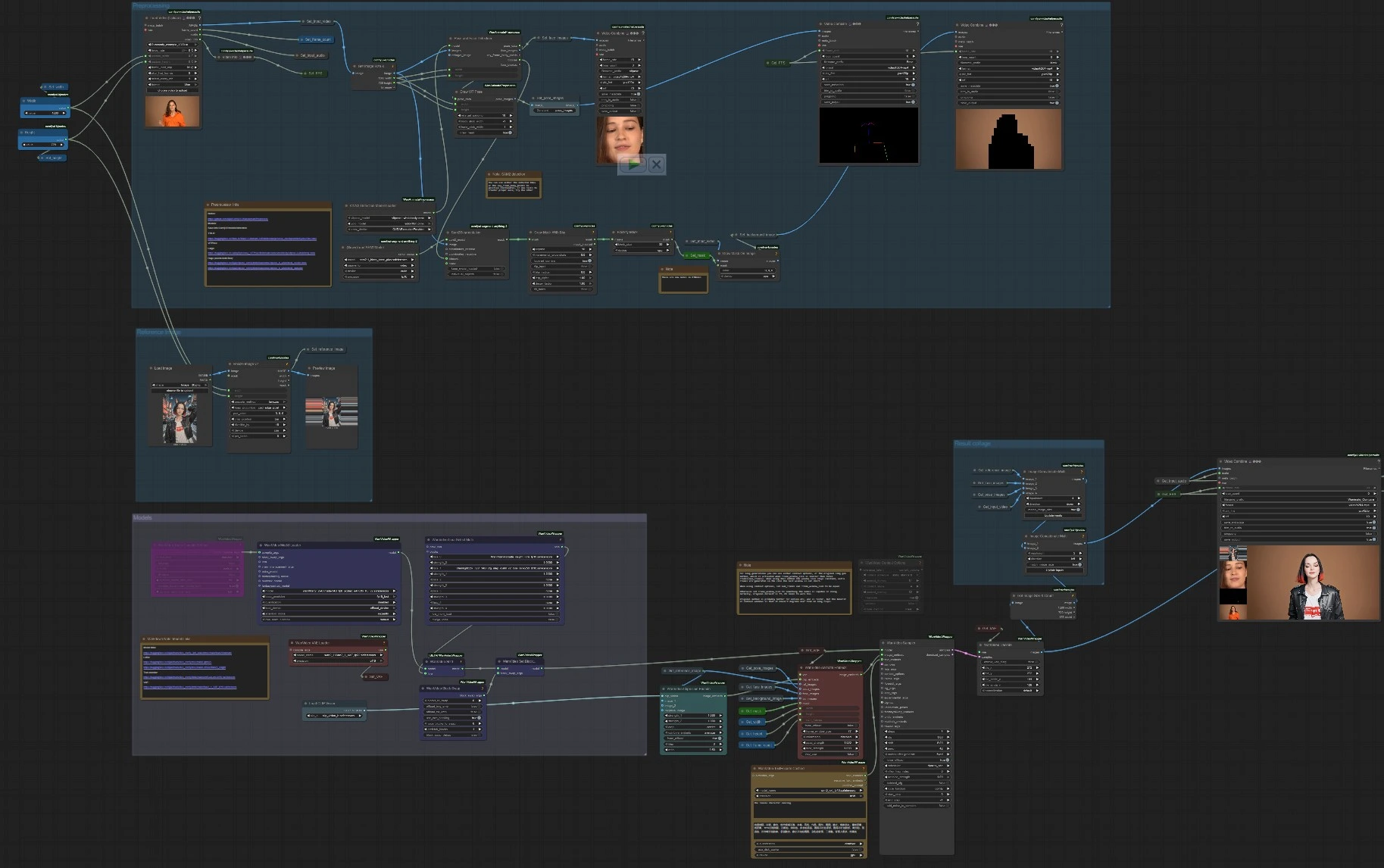
Auf hoher Ebene extrahiert die Pipeline Posen- und Gesichtshinweise aus dem steuernden Video, kodiert die Identität aus einem einzelnen Referenzbild, isoliert optional das Subjekt mit einer SAM 2 Maske und synthetisiert dann ein Video, das die Bewegung nachbildet und die Identität bewahrt. Der Workflow ist in vier Gruppen organisiert, die zusammenarbeiten, um das Endergebnis zu produzieren, und zwei Komfortausgaben für schnelles QA (Posen- und Maskenvorschauen).
Referenzbild#
Diese Gruppe lädt Ihr Porträt oder Ganzkörperbild, ändert seine Größe auf die Zielauflösung und macht es im gesamten Graphen verfügbar. Das verkleinerte Bild wird von Get_reference_image gespeichert und wiederverwendet und zur schnellen Beurteilung der Einrahmung angezeigt. Identitätsmerkmale werden von WanVideoClipVisionEncode (CLIP Vision) (#70) kodiert, und dasselbe Bild speist WanVideoAnimateEmbeds (#62) als ref_images für stärkere Identitätsbewahrung. Stellen Sie ein klares, gut beleuchtetes Referenzbild bereit, das dem Subjekttyp im Steuerungsvideo entspricht, um die besten Ergebnisse zu erzielen. Kopffreiheit und minimale Verdeckungen helfen Wan 2.2 Animate V2, sich auf die Gesichtsstruktur und Kleidung zu konzentrieren.
Vorverarbeitung#
Das Steuerungsvideo wird mit VHS_LoadVideo (#191) geladen, das Frames, Audio, Frameanzahl und Quell-FPS für die spätere Verwendung bereitstellt. Posen- und Gesichtshinweise werden von OnnxDetectionModelLoader (#178) und PoseAndFaceDetection (#172) extrahiert, dann mit DrawViTPose (#173) visualisiert, sodass Sie die Tracking-Qualität bestätigen können. Die Subjektisolation wird von Sam2Segmentation (#104) gehandhabt, gefolgt von GrowMaskWithBlur (#182) und BlockifyMask (#108), um eine saubere, stabile Maske zu erzeugen; ein Helfer DrawMaskOnImage (#99) zeigt die Matte. Die Gruppe standardisiert auch Breite, Höhe und Frameanzahl des Steuerungsvideos, sodass Wan 2.2 Animate V2 räumliche und zeitliche Einstellungen ohne Raten anpassen kann. Schnelle Überprüfungen werden als kurze Videos exportiert: eine Posenüberlagerung und eine Maskenvorschau für Zero-Shot-Validierung.
Modelle#
WanVideoVAELoader (#38) lädt das Wan VAE und WanVideoModelLoader (#22) lädt das Wan 2.2 Animate Rückgrat. Optionale LoRAs werden in WanVideoLoraSelectMulti (#171) ausgewählt und über WanVideoSetLoRAs (#48) angewendet; WanVideoBlockSwap (#51) kann durch WanVideoSetBlockSwap (#50) für architektonische Änderungen aktiviert werden, die Stil und Treue beeinflussen. Aufforderungen werden von WanVideoTextEncodeCached (#65) kodiert, während WanVideoClipVisionEncode (#70) das Referenzbild in robuste Identitätseinbettungen verwandelt. WanVideoAnimateEmbeds (#62) fusioniert die CLIP-Merkmale, Referenzbild, Posenbilder, Gesichtsausschnitte, optionale Hintergrund-Frames, die SAM 2 Maske und die gewählte Auflösung und Frameanzahl in eine einzige Animationseinbettung. Dieser Feed treibt WanVideoSampler (#27) an, das latentes Video konsistent mit Ihrer Aufforderung, Identität und Bewegungshinweisen synthetisiert, und WanVideoDecode (#28) konvertiert Latents zurück in RGB-Frames.
Ergebnis-Collage#
Um den Vergleich der Ausgaben zu erleichtern, stellt der Workflow eine einfache Gegenüberstellung zusammen: das generierte Video neben einem vertikalen Streifen, der das Referenzbild, Gesichtsausschnitte, Posenüberlagerung und ein Frame aus dem Steuerungsvideo zeigt. ImageConcatMulti (#77, #66) erstellt die visuelle Collage, dann rendert VHS_VideoCombine (#30) ein „Vergleichen“ mp4. Der endgültige saubere Output wird von VHS_VideoCombine (#189) gerendert, das auch Audio vom Steuerungsvideo für schnelle Überprüfungsschnitte übernimmt. Diese Exporte erleichtern die Beurteilung, wie gut Wan 2.2 Animate V2 Bewegung verfolgt hat, Identität bewahrt und den beabsichtigten Hintergrund erhalten hat.
Schlüssel-Knoten im ComfyUI Wan 2.2 Animate V2 Workflow#
VHS_LoadVideo (#191) Lädt das Steuerungsvideo und stellt Frames, Audio und Metadaten bereit, die im Graphen verwendet werden. Halten Sie das Subjekt vollständig sichtbar mit minimalem Bewegungsunschärfe für eine stärkere Schlüsselpunktverfolgung. Wenn Sie kürzere Tests wünschen, begrenzen Sie die Anzahl der geladenen Frames; halten Sie die Quell-FPS konsistent, um Audio-Desynchronisation im endgültigen Kombinieren zu vermeiden.
PoseAndFaceDetection (#172) Führt YOLO und ViTPose aus, um Ganzkörper-Schlüsselstellen und Gesichtsausschnitte zu erzeugen, die direkt die Bewegungsübertragung leiten. Füttern Sie die Bilder vom Loader und die standardisierte Breite und Höhe; der optionale retarget_image-Eingang ermöglicht das Anpassen von Posen an einen anderen Rahmen, wenn nötig. Wenn die Posenüberlagerung verrauscht aussieht, ziehen Sie ein hochwertigeres ViTPose-Modell in Betracht und stellen Sie sicher, dass das Subjekt nicht stark verdeckt ist. Referenz: ComfyUI-WanAnimatePreprocess.
Sam2Segmentation (#104) Erzeugt eine Subjektmaske, die den Hintergrund bewahren oder Relighting in Wan 2.2 Animate V2 lokalisieren kann. Sie können die erkannten Begrenzungsboxen von PoseAndFaceDetection verwenden oder bei Bedarf schnelle positive Punkte zeichnen, um die Matte zu verfeinern. Kombinieren Sie es mit GrowMaskWithBlur für sauberere Kanten bei schnellen Bewegungen und überprüfen Sie das Ergebnis mit dem Maskenvorschau-Export. Referenz: Segment Anything 2.
WanVideoClipVisionEncode (#70) Kodiert das Referenzbild mit CLIP Vision, um Identitätshinweise wie Gesichtsstruktur, Haare und Kleidung zu erfassen. Sie können mehrere Referenzbilder mitteln, um die Identität zu stabilisieren, oder ein negatives Bild verwenden, um unerwünschte Merkmale zu unterdrücken. Zentrierte Ausschnitte mit konsistenter Beleuchtung helfen, stärkere Einbettungen zu erzeugen.
WanVideoAnimateEmbeds (#62) Fusioniert Identitätsmerkmale, Posenbilder, Gesichtsausschnitte, optionale Hintergrund-Frames und die SAM 2 Maske in eine einzige Animationseinbettung. Richten Sie width, height und num_frames mit Ihrem Steuerungsvideo aus, um weniger Artefakte zu erhalten. Wenn Sie Hintergrunddrift sehen, stellen Sie saubere Hintergrund-Frames und eine solide Maske bereit; wenn das Gesicht driftet, stellen Sie sicher, dass Gesichtsausschnitte vorhanden und gut beleuchtet sind.
WanVideoSampler (#27) Erzeugt die eigentlichen Video-Latents, die von Ihrer Aufforderung, LoRAs und der Animationseinbettung geleitet werden. Für lange Clips wählen Sie zwischen einer Schiebefenster-Strategie oder den Kontextoptionen des Modells; passen Sie das Fenster an die Cliplänge an, um Bewegungsunschärfe und langfristige Konsistenz auszugleichen. Passen Sie den Scheduler und die Führungskraft an, um Treue, Stiltreue und Bewegungsflüssigkeit abzuwägen, und ziehen Sie in Betracht, den Blocktausch zu aktivieren, wenn Ihr LoRA-Stack davon profitiert.
Optionale Extras#
- Beginnen Sie mit einem sauberen Steuerungsclip: Eine ruhige Kamera, einfache Beleuchtung und minimale Verdeckung geben Wan 2.2 Animate V2 die beste Chance, die Bewegung sauber zu verfolgen.
- Verwenden Sie eine Referenz, die das Ziel-Outfit und die Einrahmung entspricht; vermeiden Sie extreme Winkel oder starke Filter, die mit Ihrer Aufforderung oder LoRAs in Konflikt stehen.
- Bewahren oder ersetzen Sie Hintergründe mit der SAM 2 Maske; beim Compositing halten Sie die Kanten weich genug, um Halo-Effekte bei schnellen Bewegungen zu vermeiden.
- Halten Sie die FPS von der Ladung bis zum Export konsistent, um Lipsynchronisation und Beat-Ausrichtung zu bewahren, wenn Audio übernommen wird.
- Für schnelle Iterationen testen Sie zuerst ein kurzes Segment, dann erweitern Sie den Frame-Bereich, sobald Pose, Identität und Beleuchtung richtig aussehen.
Hilfreiche Ressourcen, die in diesem Workflow verwendet werden:
- Vorverarbeitungs-Knoten: kijai/ComfyUI-WanAnimatePreprocess
- ViTPose ONNX-Modelle: ViTPose-L, ViTPose-H Modell und Daten
- YOLOv10 Detektor: yolov10m.onnx
- Wan 2.2 Animate 14B Gewichte: Wan22Animate
- LoRAs: Lightx2v, Wan22_relight
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Benji’s AI Playground's Workflow und dem Wan-Team für das Wan 2.2 Animate V2 Modell für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- Wan Team/Wan 2.2 Animate V2
- Docs / Release Notes: YouTube @Benji’s AI Playground
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.
