
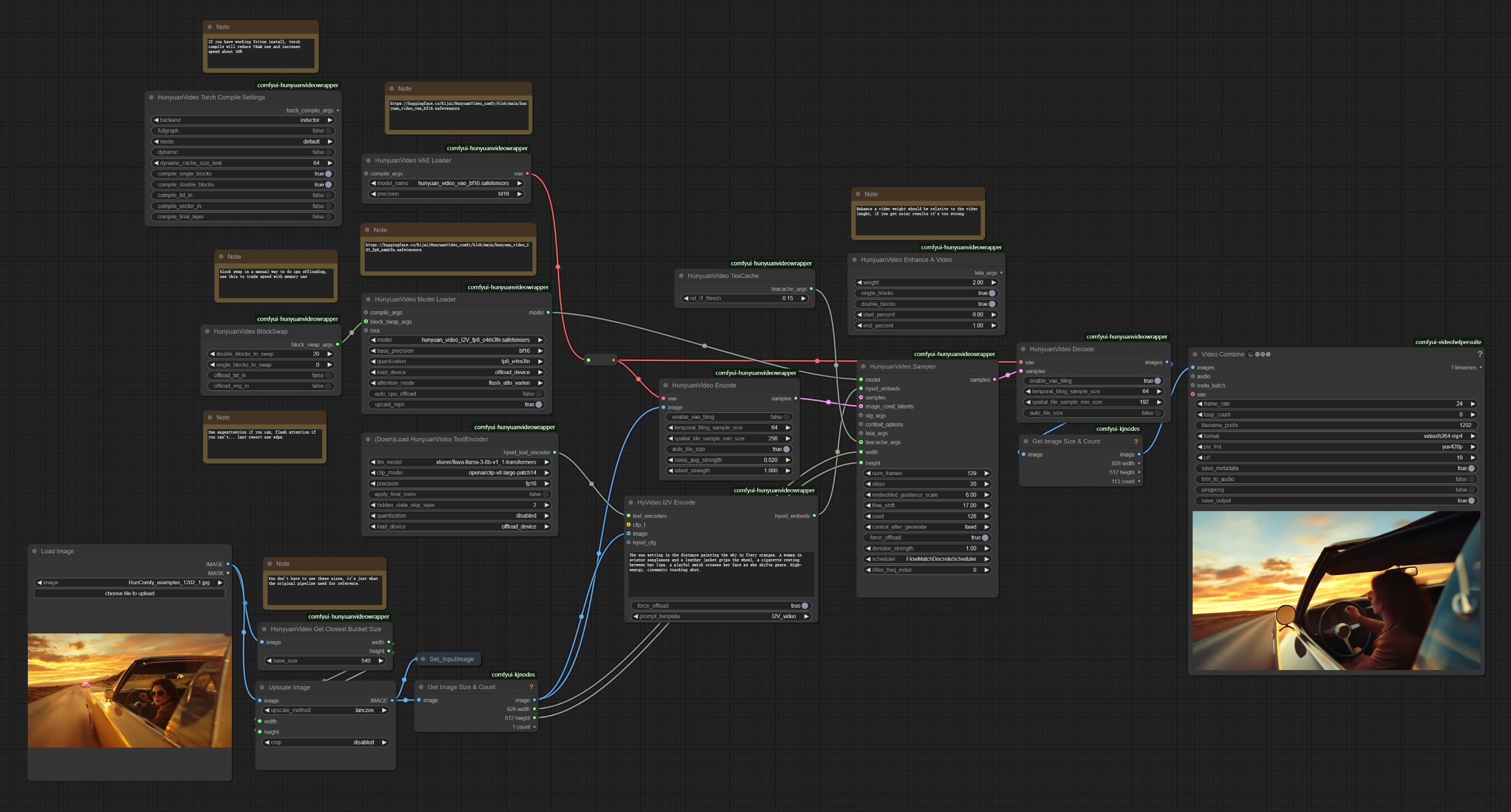
ComfyUI Hunyuan Bild-zu-Video-Workflow Beschreibung#
1. Was ist der Hunyuan Bild-zu-Video-Workflow?#
Der Hunyuan Bild-zu-Video-Workflow ist eine leistungsstarke Pipeline, die entwickelt wurde, um Standbilder in hochwertige Videos mit natürlicher Bewegung zu verwandeln. Entwickelt von Tencent, ermöglicht diese hochmoderne Technologie Benutzern, kinoreife Animationen mit flüssiger 24fps-Wiedergabe bei Auflösungen bis zu 720p zu erstellen. Durch die Nutzung von latenter Bild-Konkatenation und einem Multimodalen Großen Sprachmodell interpretiert Hunyuan Bild-zu-Video Bildinhalte und wendet konsistente Bewegungsmuster basierend auf Textanweisungen an.
2. Vorteile von Hunyuan Bild-zu-Video:#
- Hochauflösende Ausgabe - Generiert Videos bis zu 720p bei 24fps
- Natürliche Bewegungserzeugung - Erstellt flüssige, realistische Animationen aus statischen Bildern
- Textgeführte Animation - Verwendet Textanweisungen zur Steuerung von Bewegung und visuellen Effekten
- Kinoqualität - Produziert Videos in professioneller Qualität mit hoher Treue
- Anpassbare Effekte - Unterstützt LoRA-trainierte Effekte wie Haarwachstum, Gesichtsausdrücke und Stiländerungen
- Optimierte Speichernutzung - Nutzt FP8-Gewichte für besseres Ressourcenmanagement
3. Wie man den Hunyuan Bild-zu-Video-Workflow verwendet#
3.1 Generierungsmethoden mit Hunyuan Bild-zu-Video#
Beispiel-Workflow:#
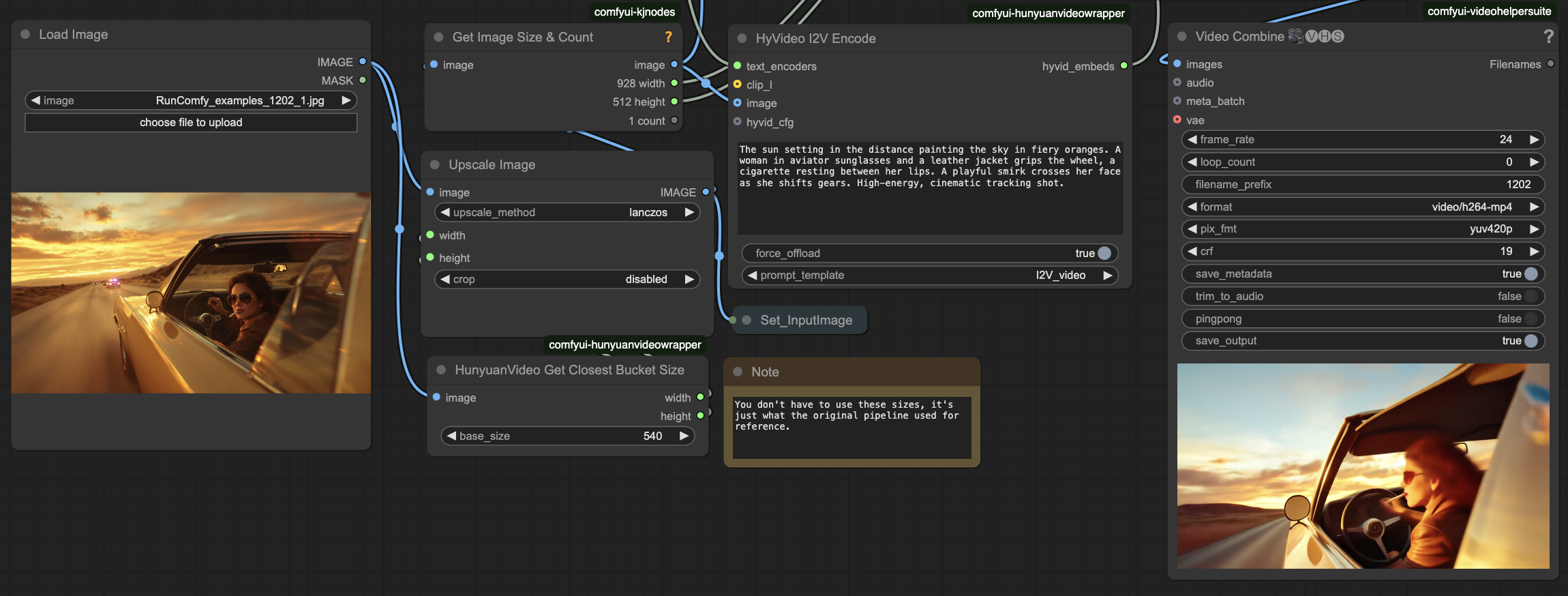
- Eingaben vorbereiten
- In Bild Laden: Laden Sie Ihr Quellbild hoch
- Bewegungsbeschreibung eingeben
- In HyVideo I2V Kodieren: Geben Sie ein beschreibendes Textanweisung für die gewünschte Bewegung ein
- Verfeinerung (Optional)
- Im HunyuanVideo Sampler: Passen Sie
framesan, um die Videolänge zu steuern (Standard: 129 Frames ≈ 5 Sekunden) - Im HunyuanVideo TeaCache: Ändern Sie
cache_factorfür optimierte Speichernutzung - Im HunyuanVideo Video Verbessern: Aktivieren Sie für zeitliche Konsistenz und Flackernreduzierung
- Im HunyuanVideo Sampler: Passen Sie
- Ausgabe
- Im Video Kombinieren: Überprüfen Sie die Vorschau und finden Sie das gespeicherte Ergebnis im ComfyUI > Ausgabe-Ordner
3.2 Parameterreferenz für Hunyuan Bild-zu-Video#
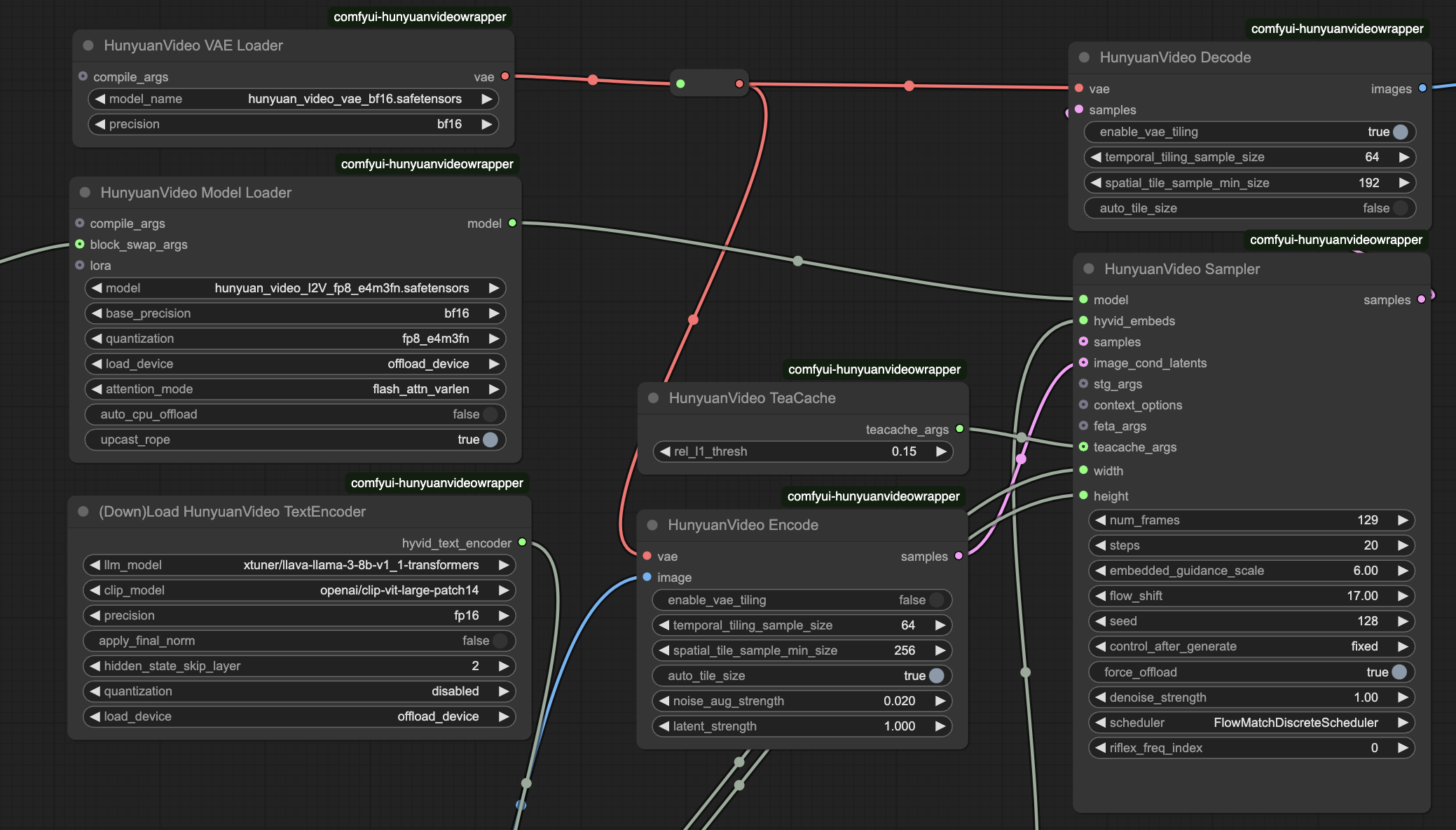
- HunyuanVideo Modelllader
model_name: hunyuan_video_I2V_fp8_e4m3fn.safetensors - Kernmodell für die Bild-zu-Video-Konvertierungweight_precision: bf16 - Definiert das Präzisionsniveau für Modellgewichtescale_weights: fp8_e4m3fn - Optimiert die Speichernutzungattention_implementation: flash_attn_varlen - Steuert die Effizienz der Aufmerksamkeitsverarbeitung
- HunyuanVideo Sampler
frames: 129 - Anzahl der Frames (5.4 Sekunden bei 24fps)steps: 20 - Abtastschritte (höhere Werte verbessern die Qualität)cfg: 6 - Steuert die Stärke der Anweisungstreueseed: variiert - Sichert die Konsistenz der Generierung
- HyVideo I2V Kodieren
prompt: [Textfeld] - Beschreibende Anweisung für Bewegung und Stiladd_prepend: true - Ermöglicht automatische Textformatierung
3.3 Erweiterte Optimierung mit Hunyuan Bild-zu-Video#
- Speicheroptimierung
- HunyuanVideo BlockSwap: CPU-Auslagerung für VRAM-Effizienz
- HunyuanVideo TeaCache: Steuert das Cache-Verhalten zur Balance zwischen Speicher und Geschwindigkeit
- scale_weights: FP8-Gewichte (
e4m3fn-Format) zur Speicherreduzierung
- Geschwindigkeitsoptimierung
- HunyuanVideo Torch Compile Einstellungen: Aktiviert Torch-Kompilierung für schnellere Verarbeitung
- attention_implementation: Wählt effiziente Aufmerksamkeitsmechanismen zur Leistungssteigerung
- offload_device: Konfiguriert das Speicher-Management von GPU/CPU
Weitere Informationen#
Für weitere Details zum Hunyuan Bild-zu-Video-Workflow besuchen Sie das Tencent's HunyuanVideo-I2V Repository.
Danksagungen#
Dieser Workflow wird von Hunyuan Bild-zu-Video betrieben, entwickelt von Tencent. Die ComfyUI-Integration umfasst Wrapper-Knoten, die von Kijai erstellt wurden und erweiterte Funktionen wie Kontext-Fenster und direkte Bild-Einbettungsunterstützung ermöglichen. Der volle Kredit gebührt den ursprünglichen Erstellern für ihre Beiträge zum Hunyuan Bild-zu-Video-Workflow!
