






Flux Kontext Zoom Out LoRA | ComfyUI Workflow#
Dieser ComfyUI-Workflow erzeugt eine saubere, herausgezoomte Ansicht eines beliebigen Eingabebildes, indem er die Leinwand erweitert und die Szene auf natürliche Weise fortsetzt, während die Position und das Aussehen des Motivs erhalten bleiben. Er basiert auf Flux Kontext und einem speziell entwickelten LoRA, sodass Sie die "Kamera zurückziehen" können, ohne Gesichter, Texturen oder Perspektiven zu verzerren. Wenn Sie eine schnelle, zuverlässige Möglichkeit suchen, Rahmen für Thumbnails, Produktfotos, Porträts oder filmische Standbilder zu vergrößern, ist dieser Flux Kontext Zoom Out LoRA-Workflow das Richtige für Sie.
Im Kern lädt der Graph ein Flux Kontext UNet, wendet das Flux Kontext Zoom Out LoRA an, kodiert Ihr Bild in eine Referenz-Latenz und sampelt eine breitere Komposition, die durch einen speziell für die Integrität des Zoom-Outs entwickelten Prompt geleitet wird. Das Ergebnis ist eine nahtlose Erweiterung, die die ursprüngliche Beleuchtung, den Stil und die Geometrie widerspiegelt.
Schlüsselmodelle im Comfyui Flux Kontext Zoom Out LoRA-Workflow#
- Flux 1 Kontext UNet. Das hier verwendete Diffusions-Backbone ist eine kontextbewusste Flux 1-Variante, die für ComfyUI vorbereitet wurde (
flux1-dev-kontext_fp8_scaled.safetensors). Es erfasst die für realistisches Outpainting benötigte Langstreckenstruktur und Szenenlayout. Modellpaket: Comfy-Org/flux1-kontext-dev_ComfyUI. - Flux Kontext Zoom Out LoRA. Ein leichtgewichtiger Adapter, der das Modell darauf konditioniert, die Ränder überzeugend zu erweitern, während das sichtbare Motiv unverändert bleibt. Repository: reverentelusarca/flux-kontext-zoom-out-lora.
- Dual text encoders for Flux. Der Graph verwendet CLIP-L und T5-XXL-Encoder, die für Flux abgestimmt sind, um Prompts mit hoher Genauigkeit zu interpretieren. Text-Encoder: comfyanonymous/flux_text_encoders.
- AE VAE. Ein schneller, hochwertiger Autoencoder, der für die Kodierungs-/Dekodierungsschritte verwendet wird (
ae.safetensors). Quelle: Comfy-Org/Lumina_Image_2.0_Repackaged.
So verwenden Sie den Comfyui Flux Kontext Zoom Out LoRA-Workflow#
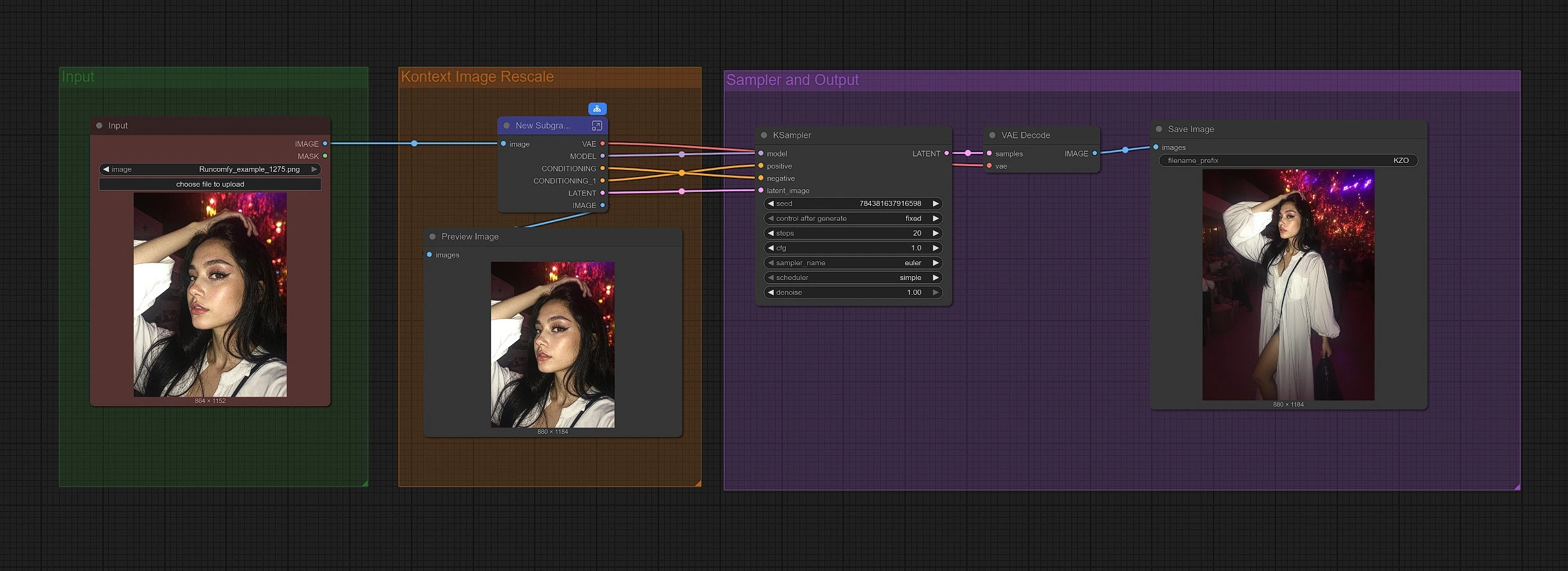
Dieser Workflow ist in drei Gruppen organisiert. Beginnen Sie mit dem Laden Ihres Bildes, dann skaliert der Graph es für den Kontext-Zoom-Out, und schließlich rekonstruiert das Sampling einen breiteren Rahmen und speichert das Ergebnis.
Gruppe: Eingabe#
Laden Sie Ihr Quellbild über LoadImage (#190). Der standardmäßige positive Prompt in CLIP Text Encode (Positive Prompt) (#6) ist darauf ausgelegt, das Motiv zu bewahren und die Leinwand gleichmäßig in alle Richtungen zu erweitern. Sie können diesen Prompt so belassen, um originalgetreue Zoom-Outs zu erzielen, oder ihn leicht an den Stil Ihrer Szene anpassen. Der DualCLIPLoader (#38) ist mit CLIP-L und T5-XXL vorverkabelt, sodass die Textkonditionierung sofort einsatzbereit ist.
Gruppe: Kontext Bildskalierung#
FluxKontextImageScale (#42) bereitet das Bild für den Zoom-Out vor, indem es in einer Weise skaliert und gepolstert wird, die die Kontextmodelle problemlos handhaben können. Dieser Vorbereitungsprozess hilft dem Modell zu verstehen, wo Inhalte erweitert werden sollen und wie Perspektive und Beleuchtung konsistent gehalten werden können. Das skalierte Bild wird dann von VAEEncode (#124) kodiert, sodass der Sampler von einer Latenz ausgeht, die sich noch an die ursprüngliche Rahmung "erinnert".
Gruppe: Sampler und Ausgabe#
Der Modellstapel wird von UNETLoader (#37) und LoraLoaderModelOnly (#191) zusammengebaut, der das Flux Kontext Zoom Out LoRA auf das Basismodell anwendet. ReferenceLatent (#177) verwendet Ihr kodiertes Bild als strukturellen Anker, sodass das Motiv unverändert bleibt, während die Ränder wachsen. FluxGuidance (#35) bestimmt, wie stark die Referenz die Generierung beeinflusst; höhere Werte erhöhen die Treue, während niedrigere Werte eine leicht neuartige Füllung ermöglichen. KSampler (#31) führt den eigentlichen Diffusionsdurchgang durch, und VAEDecode (#8), PreviewImage (#173) und SaveImage (#136) zeigen und speichern das endgültige herausgezoomte Bild.
Schlüssel-Knoten im Comfyui Flux Kontext Zoom Out LoRA-Workflow#
FluxKontextImageScale (#42)#
Bereitet die Eingabe durch Skalierung und Rahmung für kontextbewusstes Outpainting vor. Verwenden Sie es als einzigen Ort, um zu ändern, wie viel Leinwand Sie hinzufügen möchten. Wenn Sie mehr Platz benötigen, erhöhen Sie die Scale-Out-Menge; wenn die Ränder zu neu aussehen, reduzieren Sie sie, um mehr der ursprünglichen Pixel zu behalten.
LoraLoaderModelOnly (#191)#
Lädt und wendet kontext/zoomout-fal-v1.safetensors auf das Flux 1 Kontext UNet an. Wenn Ihre Ausgaben unter- oder übervorspannt erscheinen, passen Sie hier die LoRA-Stärke an. Halten Sie Änderungen moderat, um das beabsichtigte Verhalten des Zoom Out LoRA zu bewahren.
ReferenceLatent (#177)#
Sperrt Komposition und Identität, indem der Sampler auf das VAE-kodierte Original konditioniert wird. Wenn Sie subtile Abweichungen in der Haltung oder im Maßstab des Motivs bemerken, leiten Sie die Konditionierung durch diesen Knoten wie vorgesehen und vermeiden Sie es, ihn zu entfernen. Die Paarung mit einem neutralen oder minimalen Prompt maximiert die Treue.
FluxGuidance (#35)#
Steuert, wie stark die Referenz und der Prompt den Sampler leiten. Erhöhen Sie die Anleitung, wenn die erweiterten Bereiche nicht mit Beleuchtung oder Perspektive übereinstimmen; senken Sie sie, wenn Sie eine leicht kreativere Hintergrundfüllung wünschen. Behandeln Sie es als Balance-Regler zwischen strikter Erhaltung und organischer Fortsetzung.
Optionale Extras#
- Halten Sie den positiven Prompt minimal. Der enthaltene Prompt ist für dieses Flux Kontext Zoom Out LoRA abgestimmt und benötigt normalerweise keine Änderungen.
- Wenn die Ränder winzige Nähte aufweisen, versuchen Sie eine kleinere Scale-Out in
FluxKontextImageScaleoder eine leicht höhereFluxGuidance. - Fügen Sie für stilistische Szenen 1–2 Wörter zum Prompt hinzu, die Ton oder Medium beschreiben, nicht die Form des Motivs, um eine Veränderung der Hauptfigur zu vermeiden.
- Speichern Sie iterative Varianten, indem Sie nur den Seed ändern; dies ermöglicht Ihnen, die sauberste Fortsetzung auszuwählen, ohne die Komposition zu ändern.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken reverentelusarca für Flux Kontext Zoom Out LoRA für ihre Beiträge und Pflege. Für autoritative Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- reverentelusarca/Flux Kontext Zoom Out LoRA
- Hugging Face: Flux Kontext Zoom Out LoRA
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und des Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.


