
⚠️ 重要提示:此 ComfyUI MultiTalk 實現目前僅支持單人生成。多人對話功能即將推出。
1. 什麼是 MultiTalk?#
MultiTalk 是由 MeiGen-AI 開發的革命性音頻驅動多人對話視頻生成框架。與僅動畫面部運動的傳統說話頭生成方法不同,MultiTalk 技術可以生成真實的人物說話、唱歌和互動視頻,同時保持音頻輸入的完美唇同步。MultiTalk 通過讓人物說或唱出您希望他們說的內容,將靜態照片轉換為動態對話視頻。
2. MultiTalk 如何運作#
MultiTalk 利用先進的 AI 技術理解音頻信號和視覺信息。ComfyUI MultiTalk 實現結合了 MultiTalk + Wan2.1 + Uni3C 以達到最佳效果:
音頻分析: MultiTalk 使用強大的音頻編碼器 (Wav2Vec) 理解語音的細微差別,包括節奏、音調和發音模式。
視覺理解: 基於強大的 Wan2.1 視頻擴散模型(您可以訪問我們的 Wan2.1 工作流程 用於 t2v/i2v 生成),MultiTalk 理解人體解剖學、面部表情和身體動作。
相機控制: MultiTalk 與 Uni3C 控制網絡使得微妙的相機動作和場景控制成為可能,使視頻更加動態和專業。查看我們的 Uni3C 工作流程 以創建漂亮的相機運動轉移。
完美同步: 通過複雜的注意力機制,MultiTalk 學會完美地將嘴部動作與音頻對齊,同時保持自然的面部表情和身體語言。
指令跟隨: 與簡單的方法不同,MultiTalk 能夠遵循文本提示來控制場景、姿勢和整體行為,同時保持音頻同步。
3. ComfyUI MultiTalk 的優勢#
- 高品質唇同步: MultiTalk 在唇同步方面達到毫秒級精度,特別是在唱歌場景中給人留下深刻印象
- 多功能內容創作: MultiTalk 支持說話和唱歌生成,適用於各種角色類型,包括卡通角色
- 靈活的分辨率: MultiTalk 可以在 480P 或 720P 的任意長寬比下生成視頻
- 長視頻支持: MultiTalk 創建長達 15 秒的視頻
- 指令跟隨: MultiTalk 通過文本提示控制角色動作和場景設置
4. 如何使用 ComfyUI MultiTalk 工作流程#
MultiTalk 使用指南#
步驟 1:準備您的 MultiTalk 輸入
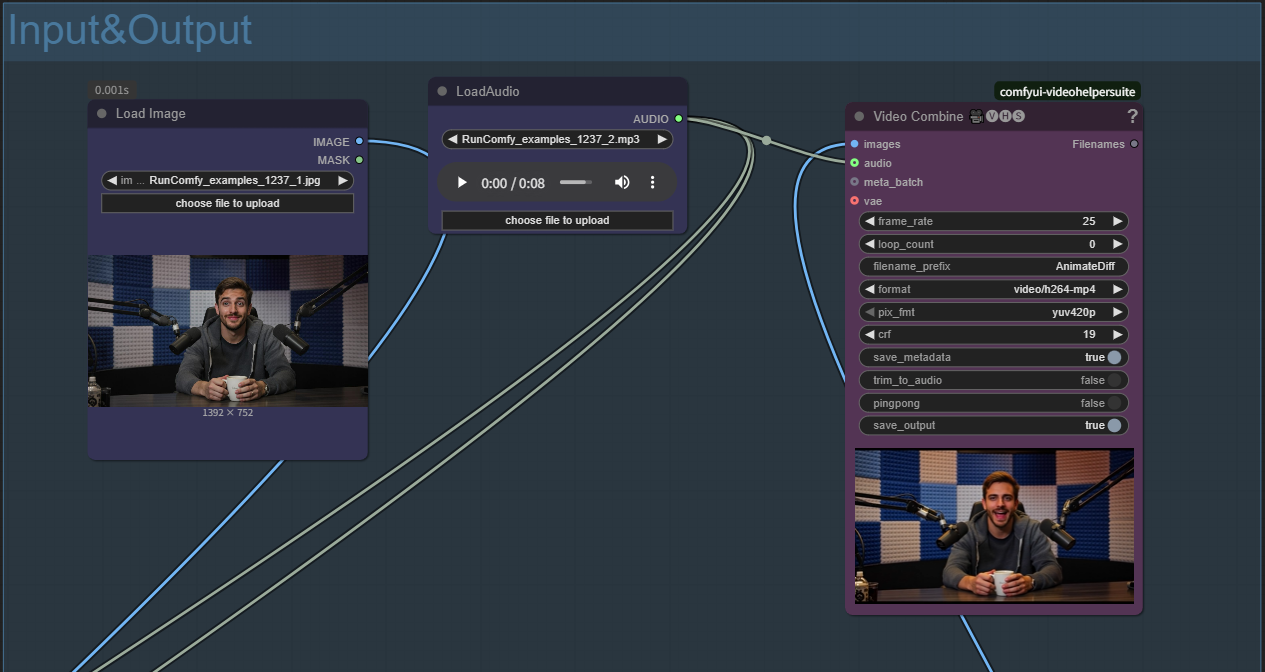
- 上傳參考圖像: 在 Load Image 節點中點擊 "choose file to upload"
- 使用清晰的正面照片以獲得最佳的 MultiTalk 結果
- 圖像將自動調整為最佳尺寸(建議 832px)
- 上傳音頻文件: 在 LoadAudio 節點中點擊 "choose file to upload"
- MultiTalk 支持各種音頻格式(WAV、MP3 等)
- 清晰的語音/唱歌效果最佳
- 要創建自定義歌曲,請考慮使用我們的 Ace-Step 音樂生成工作流程,其產生高質量的音樂和同步的歌詞。
- 編寫文本提示: 在文本編碼節點中描述您想要的場景以進行 MultiTalk 生成
步驟 2:配置 MultiTalk 生成設定
- 採樣步驟: 20-40 步(越高 = 更好的 MultiTalk 質量,生成速度較慢)
- 音頻比例: 保持 1.0 以獲得最佳的 MultiTalk 唇同步
- 嵌入條件比例: 2.0 用於平衡的 MultiTalk 音頻條件
- 相機控制: 啟用 Uni3C 以獲得微妙的動作,或禁用以獲得靜態 MultiTalk 拍攝
步驟 3:可選的 MultiTalk 增強
- LoRA 加速: 啟用以更快的 MultiTalk 生成,質量損失最小
- 視頻增強: 使用增強節點進行 MultiTalk 後期處理改進
- 負面提示: 添加不想要的元素以避免出現在 MultiTalk 輸出中(模糊、失真等)
步驟 4:使用 MultiTalk 生成
- 排隊等待 MultiTalk 生成
- 監控 VRAM 使用(推薦 48GB 用於 MultiTalk)
- MultiTalk 生成時間:根據設定和硬件不同需 7-15 分鐘
5. 鳴謝#
原始研究: MultiTalk 由 MeiGen-AI 開發,並與該領域的頂尖研究人員合作。原始論文 "Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation" 提出了這項技術的突破性研究。
ComfyUI 集成: ComfyUI 的實現由 Kijai 通過 ComfyUI-WanVideoWrapper 存儲庫提供,使這一先進技術對更廣泛的創意社區可用。
基礎技術: 建立在 Wan2.1 視頻擴散模型之上,並結合 Wav2Vec 的音頻處理技術,代表了尖端 AI 研究的結合。
6. 連結和資源#
- 原始研究: MeiGen-AI MultiTalk Repository
- 專案頁面: https://meigen-ai.github.io/multi-talk/
- ComfyUI 集成: ComfyUI-WanVideoWrapper