
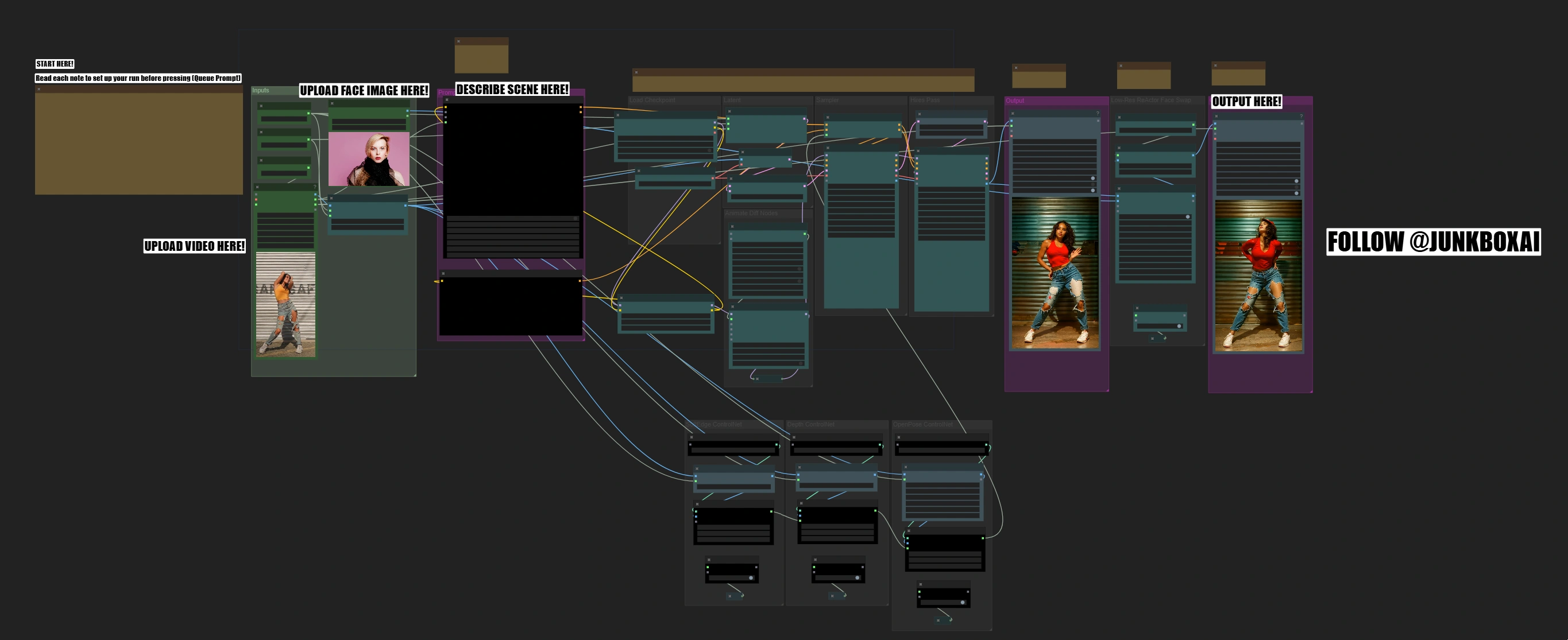
舞蹈影片轉換ComfyUI工作流程的功能#
舞蹈影片轉換ComfyUI工作流程將舞蹈影片轉換為令人驚豔的新場景,專業的臉部替換同時保留原始編排並確保高品質輸出。整個過程分階段進行,從動作分析到臉部替換,每一步都進行質量檢查。
舞蹈影片轉換ComfyUI工作流程的運作方式#
此工作流程透過多個階段自動化這些複雜的轉換,只需您的影片、臉部圖像和場景描述: 動作分析 → 風格轉換 → 臉部替換
- 分析舞蹈動作和空間資訊
- 根據您的描述轉換場景
- 在保持表情的同時整合新臉部
舞蹈影片轉換ComfyUI工作流程的主要特點#
- 優化垂直格式(9:16寬高比)
- 三重ControlNet系統,穩定轉換
- 專業的臉部替換,自然融合
- 快速測試模式(幾分鐘內處理50幀)
- 支援高解析度輸出(最高896像素高度)
- 使用AnimateDiff的高級動作保留
- 雙重輸出系統,進行質量驗證
快速入門指南#
步驟1:初始設置#
在相應的節點中:
- 上傳影片(Upload):
- 上傳10-15秒的舞蹈影片,9:16寬高比
- 如果您的影片不是9:16,您將需要調整寬度和高度參數以匹配您的影片。
- 幀加載上限:50(僅渲染前50幀以快速測試)
- 上傳圖像:
- 上傳清晰的正面臉部照片
- 批量提示排程:
- 簡要描述場景及您想變換的其他方面 "0": "[person] in KC Chiefs jersey wearing bluejeans and a baseball cap dancing in the locker room"
- 根據需要設置負面提示 <img src="https://cdn.runcomfy.net/workflow_assets/1181/readme01.webp" alt="dance video transform" width="450"/> <img src="https://cdn.runcomfy.net/workflow_assets/1181/readme02.webp" alt="dance video transform" width="450"/> <img src="https://cdn.runcomfy.net/workflow_assets/1181/readme03.webp" alt="dance video transform" width="450"/>
步驟2:快速測試運行#
- 點擊"Queue Prompt"
- 這將處理約2秒的影片
- 您將看到兩個輸出:
- 第一個輸出:僅場景轉換
- 第二個輸出:應用臉部替換

步驟3:完整影片處理#
僅在快速測試效果良好後:
- 返回"Load Video"節點
- 將幀加載上限更改為0以處理完整影片
- 點擊"Queue Prompt"以完成處理 (這將花費顯著更長的時間)
作者給初學者的建議#
- 按照說明:在介面中尋找任何說明,它們將逐步指導您
- 不用擔心高級設置:大多數情況下,您不需要調整此處提到的設置之外的任何內容
- 寬高比的重要性:確保寬高比正確,否則影片可能會拉伸或裁剪
關鍵節點參考#
AnimateDiff設置#
這裡的節點創造了整個影片轉換過程中的平滑動作保留。 上下文選項定義了幀應如何分組和處理,將這些設置餵給AnimateDiff Loader,然後應用實際的動作保留。上下文長度和重疊設置直接影響AnimateDiff Loader如何保持動作一致性。
- 上下文選項節點(#94): 實現幀分組和時間處理控制以保持一致的動作。
- context_length:
- 控制一同處理的幀數
- 較高=較平滑但更多VRAM使用
- 較低=較快但可能失去動作一致性
- context_overlap:
- 處理幀過渡的平滑度
- 較高=更好的融合但處理較慢
- 較低=較快但可能出現過渡間隙
- context_schedule:
- 控制幀分佈
- "uniform"最適合舞蹈動作
- 除非有特定需要,否則不要更改
- closed_loop:
- 控制影片循環行為
- 僅對完美循環影片設為True
- context_length:
- AnimateDiff Loader節點(#93): 使用AnimateDiff模型實施動作保留並應用時間一致性。
- motion_scale:
- 控制動作強度
- 較高:誇張的動作
- 較低:溫和的動作
- beta_schedule: lcm >> sqrt_linear
- 控制取樣行為
- 為此工作流程優化
- 除非必要,否則不要更改
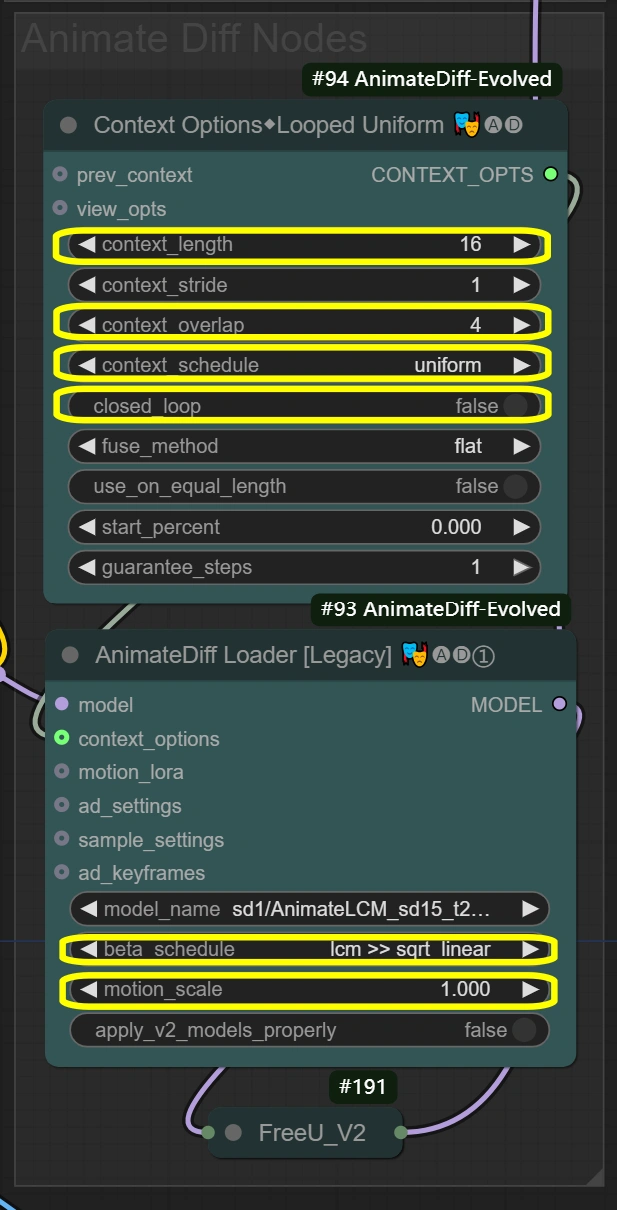
- motion_scale:
ControlNet Stack#
這裡的節點通過三層引導系統維持影片完整性。 三個ControlNets同時處理輸入幀,每個專注於不同的方面。Soft Edge提供基本結構,Depth增加空間理解,OpenPose確保動作準確性。結果透過堆疊器結合,總強度不超過1.4以維持穩定性。
- Soft Edge ControlNet: 從原始幀中提取並保留結構元素和形狀。
- Strength:
- 控制結構保留
- 較高=更強的原始形狀遵循
- 較低=形狀修改的創造自由
- End percent:
- 控制影響停止的時間
- 較高=在整個過程中更長的影響
- 較低=允許後期步驟更多變化
- Strength:
- Depth ControlNet: 處理空間關係並保持3D一致性。
- Strength:
- 控制空間意識
- 較高=更強的3D一致性
- 較低=空間的藝術自由
- End percent:
- 維持深度影響持續時間
- 應與Soft Edge匹配以保持一致性
- Strength:
- OpenPose ControlNet: 捕獲並轉移姿勢資訊以確保準確的動作。
- Strength:
- 控制姿勢保留
- 較高=更嚴格的姿勢遵循
- 較低=更靈活的姿勢解釋
- End percent:
- 維持姿勢影響
- 在整個過程中保持自然動作
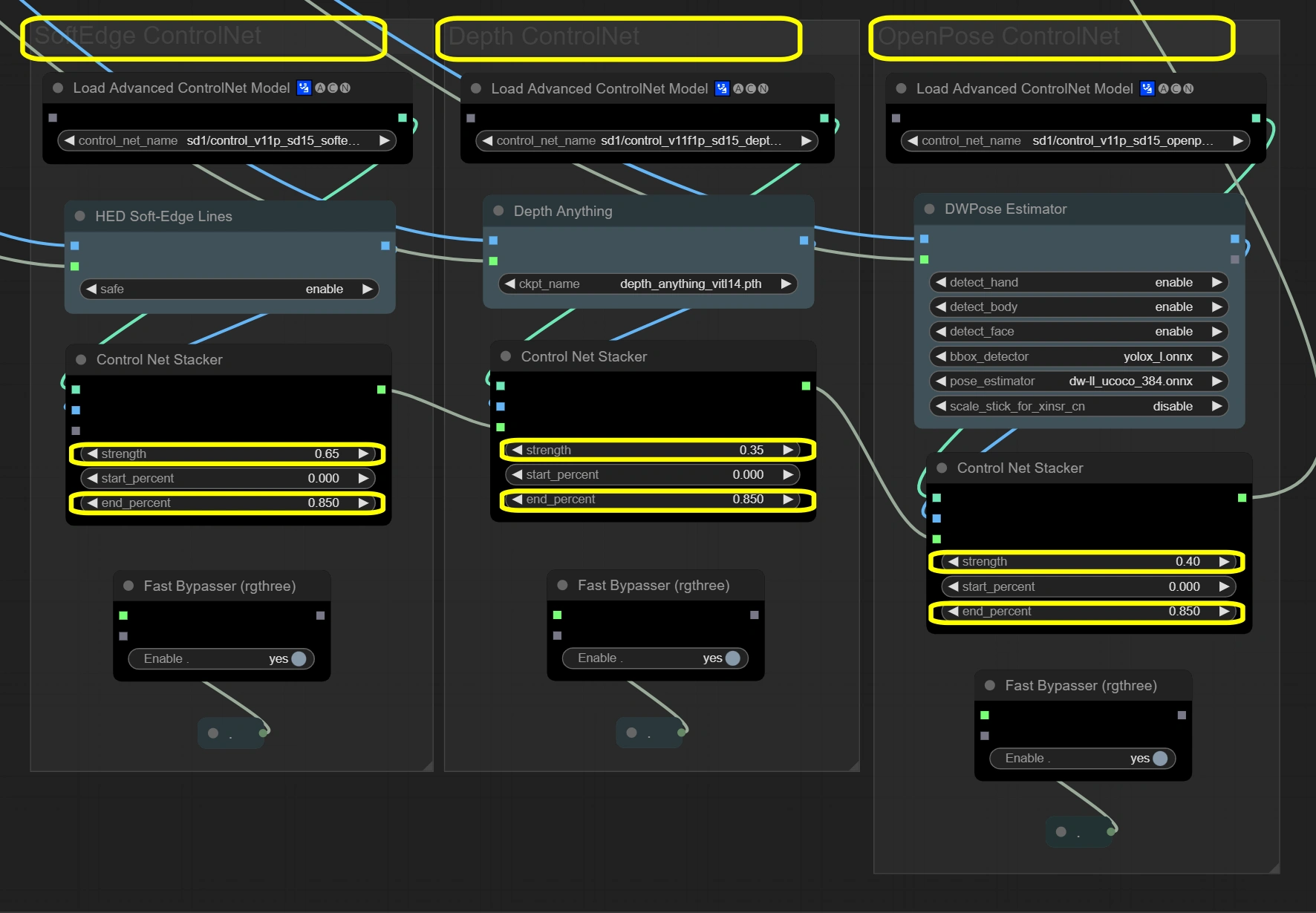
- Strength:
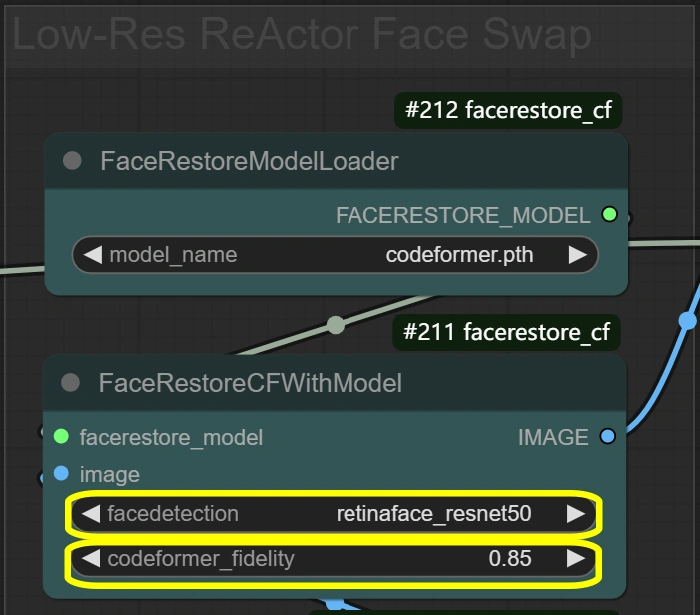
臉部處理#
這裡的節點負責臉部替換和增強以獲得自然的結果。 該過程分兩個階段進行:FaceRestore首先增強原始臉部的質量,然後ReActor使用增強的臉部作為參考進行替換。這種雙階段過程確保自然整合同時保留表情。
- FaceRestore System: 增強臉部細節並準備進行替換。
- Fidelity:
- 控制修復中的細節保留
- 較高=更詳細但可能有偽影
- 較低=更平滑但可能失去細節
- Detection:
- 臉部檢測模型選擇
- 可靠於大多數情境
- 除非臉部未被檢測到,否則不要更改
- Fidelity:
- ReActor Face Swap: 執行臉部替換和融合,保留表情。
- Visibility:
- 控制替換的可見性
- 較高=更強的臉部替換效果
- 較低=更細膩的融合
- Weight:
- 臉部特徵保留平衡
- 較高=更強的來源臉部特徵
- 較低=更好的與目標融合
- Console log level:
- 控制調試資訊
- 較高=更詳細的日誌
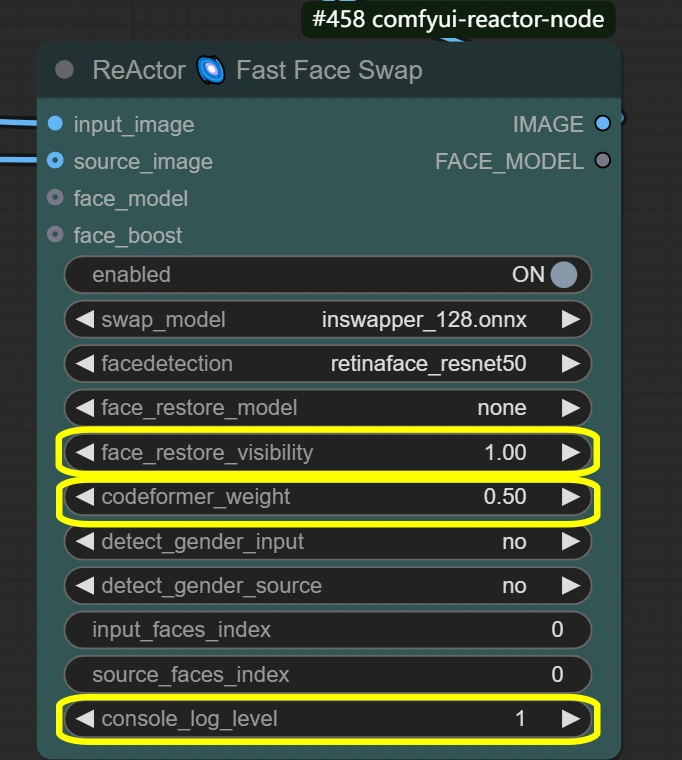
- Visibility:
其他節點詳情#
輸入與預處理#
目的:加載影片,調整尺寸,並準備VAE模型進行處理。
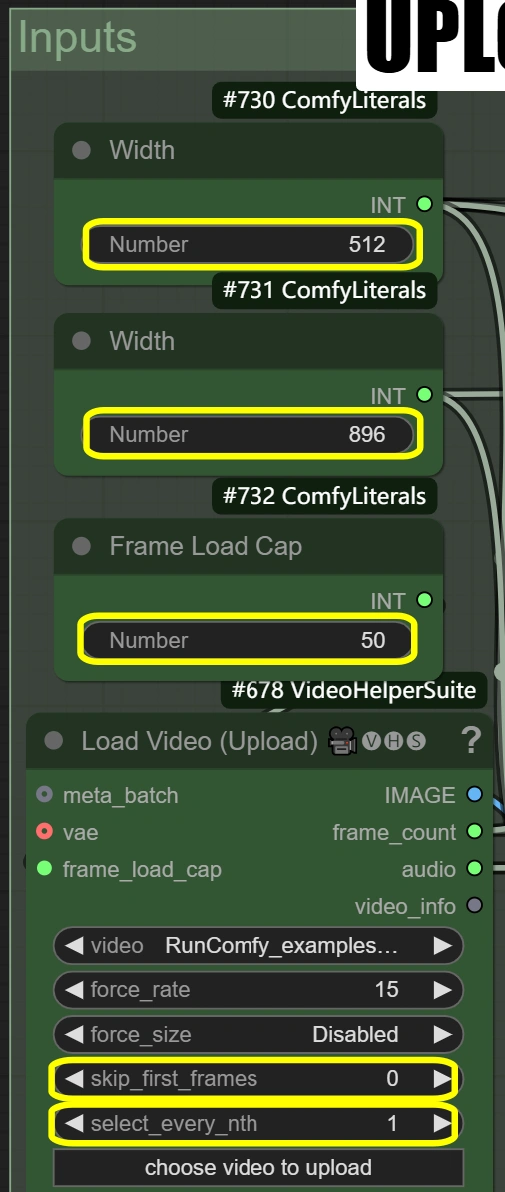
- Load Video:
- Frame Load Cap:
- 控制要處理的幀數
- 50 = 快速測試(處理約2秒)
- 0 = 處理整個影片
- 影響總處理時間
- Skip First Frames:
- 定義影片中的起始點
- 較高=從影片中更後的地方開始
- 用於跳過片頭
- Select Every Nth:
- 控制幀採樣率
- 較高的數字跳過幀
- 1 = 使用每一幀
- 2 = 使用每第二幀,等等。
- Frame Load Cap:
- Image Scale:
- Width: 512
- 控制輸出幀的寬度
- 必須與高度保持9:16比例
- Height: 896
- 控制輸出幀的高度
- 必須與寬度保持9:16比例
- Method: nearest-exact
- 最適合保持清晰度
- 替代方案可能會模糊內容
- 建議用於舞蹈影片
- 除非有特定需要,否則不要更改
- Width: 512
- VAE Loader:
- Model: vae-ft-mse-840000-ema-pruned
- 為穩定性和質量優化
- 處理圖像編碼/解碼
- 平衡的壓縮比
- 除非有特定需要,否則不要更改
- VAE Mode: 不要更改
- 為當前工作流程優化
- 影響編碼質量
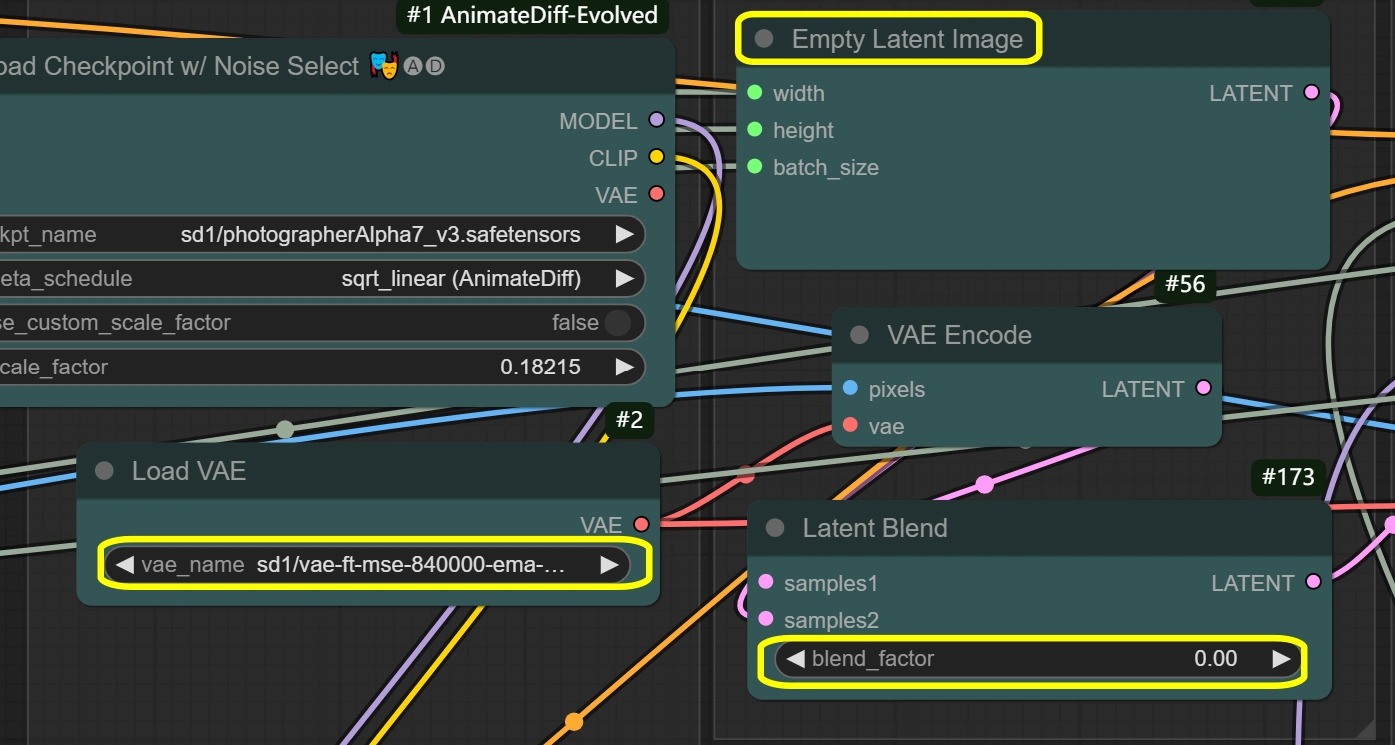
- Model: vae-ft-mse-840000-ema-pruned
潛在處理#
目的:處理和轉換所有潛在空間操作。
- Empty Latent Image:
- Width/Height: 與輸入相符
- 必須與Image Scale尺寸匹配
- 直接影響記憶體使用量
- 較大尺寸需要更多VRAM
- 不能小於輸入
- Batch Size: 來自影片幀
- 自動從幀數設置
- 影響處理速度和VRAM
- 較高=需要更多記憶體
- Width/Height: 與輸入相符
- VAE Encode:
- VAE Model: 來自VAE Loader
- 使用來自VAE Loader的設置
- 保持一致性
- Decode: 啟用
- 控制解碼質量
- 僅在VRAM有限時禁用
- 影響輸出質量
- VAE Model: 來自VAE Loader
- Latent Blend:
- Blend Factor:
- 控制潛在空間的混合
- 0 = 完全來源內容
- 較高=更多空白潛在影響
- 影響風格轉換強度
- Blend Factor:
- Latent Upscale By:
- Method: nearest-exact
- 最適合保持清晰度
- 替代方法可能會模糊
- 保留動作細節
- Scale:
- 控制尺寸增加
- 較高=更好細節但更多VRAM
- 較低=更快處理
- 1.6對大多數情況最優
- Method: nearest-exact
取樣與細化#
目的:進行兩階段取樣以確保質量轉換。
- KSampler(第一遍):
- Steps:
- 去噪步驟數量
- 較高=更好質量但較慢
- 6對lcm取樣器最優
- CFG:
- 控制提示影響
- 較高=更強的風格遵循
- 較低=更多自由
- Sampler: lcm
- 為速度優化
- 良好的質量/速度平衡
- Scheduler: sgm_uniform
- 與lcm最佳搭配
- 維持時間一致性
- Denoise:
- 第一遍全強度
- 控制轉換強度
- Steps:
- KSampler(高分辨率遍):
- Steps:
- 與第一遍一致
- 細化不需要更高
- CFG:
- 維持風格一致性
- 平衡細節保留
- Sampler: lcm
- 與第一遍相同
- 保持一致性
- Scheduler: sgm_uniform
- Steps:
json
- 與第一遍保持一致性
- 適合細節細化
- Denoise:
- 低於第一遍
- 保留更多原始細節
- 細化的良好平衡
輸出處理#
目的:創建最終影片輸出,包含和不包含臉部替換。
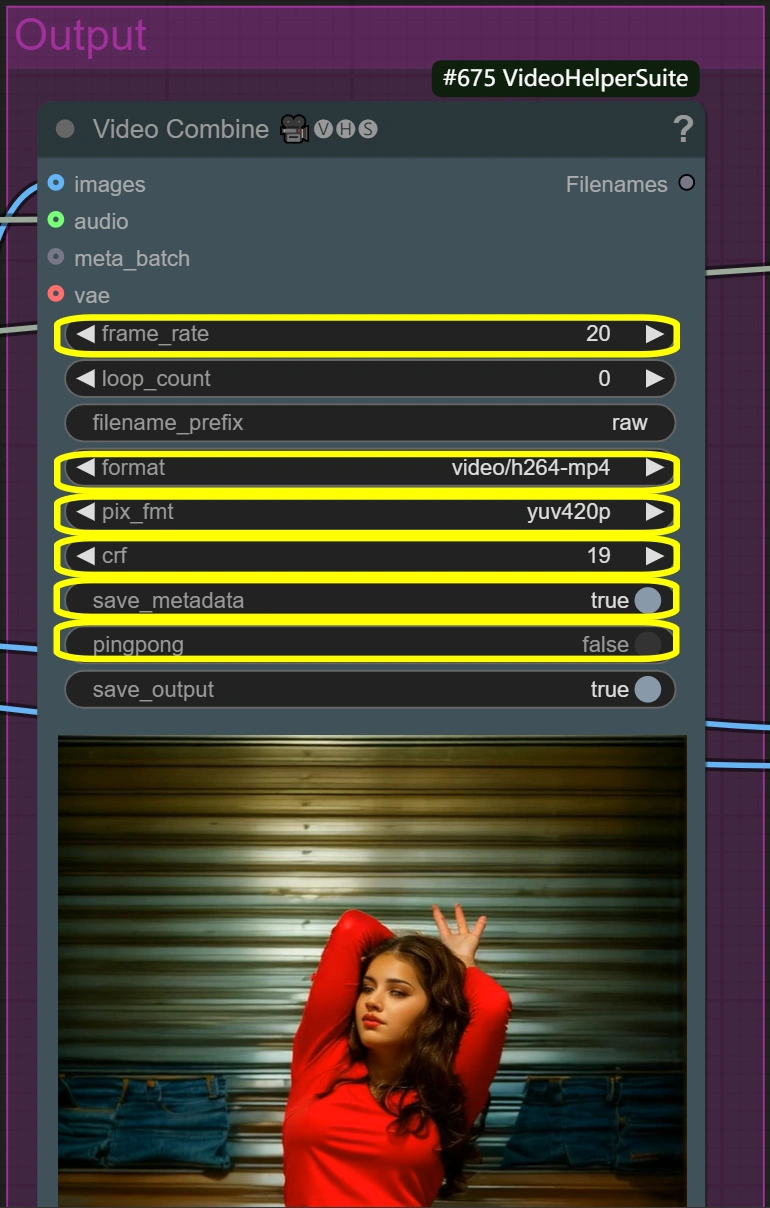
- Video Combine (Raw):
- Frame Rate:
- 標準影片幀率
- 控制播放速度
- 較低=較小文件大小
- 較高=更平滑的動作
- Format: video/h264-mp4
- 標準格式以確保兼容性
- 質量/大小的良好平衡
- 廣泛支持
- CRF:
- 控制壓縮質量
- 較低=更好質量但較大文件
- 較高=較小文件但較低質量
- 19是高質量設置
- Pixel Format: yuv420p
- 標準格式以確保兼容性
- 除非必要,否則不要更改
- 確保廣泛的播放支持
- Frame Rate:
- Video Combine (Face Swap):
- 與原始輸出相同的參數
- 使用相同的設置以保持一致性
- 添加臉部替換
- 維持影片質量設置
優化提示#
質量與速度的權衡#
- 解析度平衡:
- 標準:512x896
- 處理速度更快
- 適合大多數用途
- 高品質:768x1344
- 更好的細節
- 處理時間增加2-3倍
- 標準:512x896
- 臉部替換質量:
- 標準:默認設置
- 自然整合
- 平衡的處理時間
- 最高品質:
- 將codeformer_fidelity提高到0.9
- 更慢但更詳細的臉部
- 標準:默認設置
- 運動平滑度:
- 更快的處理:
- 將context_overlap減少到2
- 過渡稍微不平滑
- 更好的運動:
- 將重疊增加到6
- 使用更多VRAM,處理較慢
- 更快的處理:
常見問題與解決方案#
- 臉部融合:
- 問題:不自然的臉部過渡
- 解決方案:調整codeformer_weight
- 嘗試範圍0.4-0.7
- 較低=更好的融合
- 較高=更多面部細節
- 風格強度:
- 問題:風格轉換弱
- 解決方案:增加cfg
- 嘗試範圍7-8
- 較高=更強的風格
- 可能影響動作質量
- 記憶體管理:
- 問題:VRAM限制
- 解決方案:
- 啟用VAE切片
- 降低解析度
- 處理較短的片段
更多資訊#
如需更多詳情和精彩創作,請訪問junkboxai的Instagram。
