
If you trained a LoRA with Ostris AI Toolkit (for FLUX / FLUX.2, Wan 2.2/2.1, Qwen Image, Z‑Image, LTX‑2, SDXL, etc.), you’ve probably hit this problem: Your AI Toolkit training samples look great, but when you run inference in Diffusers / ComfyUI / another stack, the output drifts.
This guide shows a quick, reliable way to get inference that matches your AI Toolkit training previews, so what you ship looks like what you trained.
Why AI Toolkit previews often don’t match inference
AI Toolkit “Samples” are generated by a specific inference setup:
- exact base model variant
- model‑specific scheduler / step semantics
- model‑specific LoRA application behavior (adapter vs fuse/merge)
- resolution snapping rules (width/height multiples)
- required inputs for certain pipelines (e.g., control image for edit / I2V)
If your inference stack changes any of these, even with the same prompt + seed, outputs can drift. In short: to match AI Toolkit previews, you need to match the whole inference pipeline (not just a few settings).
Why RunComfy can make LoRA inference match your training samples
RunComfy runs a base‑model specific Diffusers inference pipeline that matches the pipeline used to generate AI Toolkit training previews for that model. It then reads your Training config file (YAML) to lock the same base model variant and inference settings, so your Run LoRA inference can match your training samples 1:1. Because inference runs in a managed cloud runtime, you also avoid silent CUDA/PyTorch/Diffusers version differences that can change outputs.
Below is an example from our parity experiment (AI Toolkit training samples vs Run LoRA inference, using the same settings):
| AI Toolkit training sample | RunComfy inference (Playground/API) |
|---|---|
 |
 |
 |
 |
 |
 |
Step-by-step: Import → Run LoRA → Inference (Playground + API)
In just a few minutes, you can run through this flow end‑to‑end and get LoRA inference that matches your AI Toolkit training samples.
If you already trained with RunComfy’s AI Toolkit, your LoRA will show up in LoRA Assets automatically when the job finishes, so you can skip straight to Step 3 (Run LoRA). Here's AI Toolkit on RunComfy.
Step 0 — Prepare two files from your AI Toolkit job
You typically need:
1) LoRA weights: *.safetensors
2) Training config file (YAML) from the AI Toolkit job (often config.yml or *.yaml)
What is the Config File (YAML)?
In AI Toolkit, open your Training Job and click Config File at the top to view the exact config used for training. Copy the full contents and save it as a local .yaml file, then upload that file here.
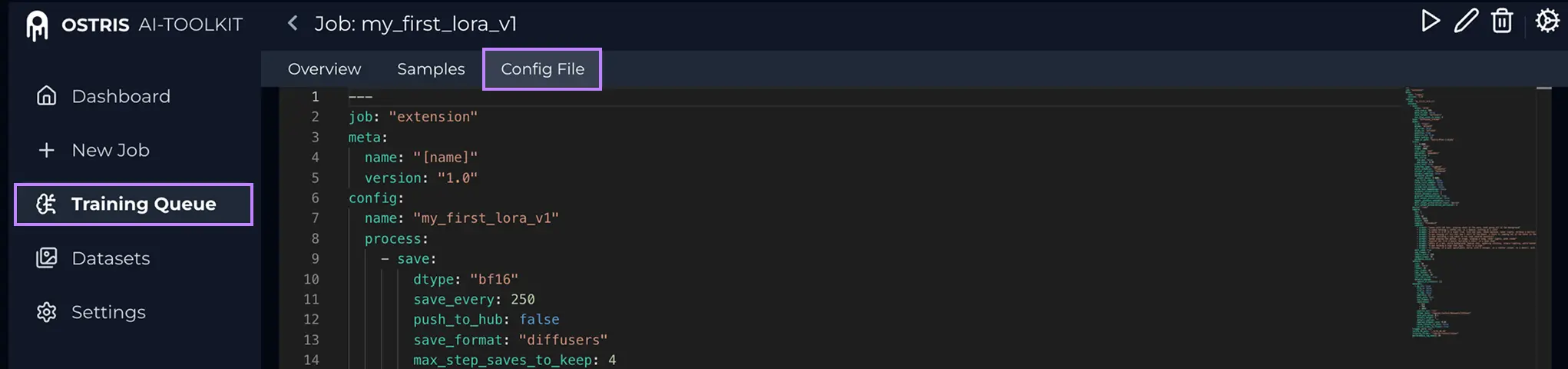
Why the config file matters: it lets RunComfy match the exact base model and inference settings that produced your AI Toolkit samples.
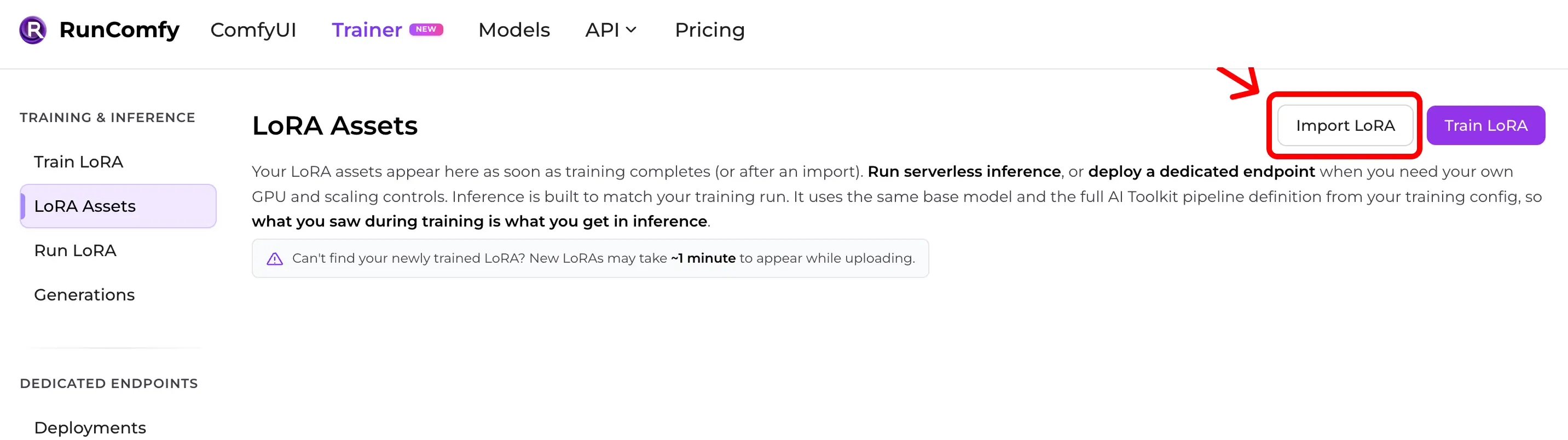
Step 1 — Import an AI Toolkit LoRA into RunComfy
Go to: Trainer → LoRA Assets → Import LoRA
Upload:
- your
*.safetensorsLoRA weights - your training config file (YAML) (recommended)
If you don’t have the config file, you can still import by selecting the Base Model, but you may lose parity if inference defaults differ.
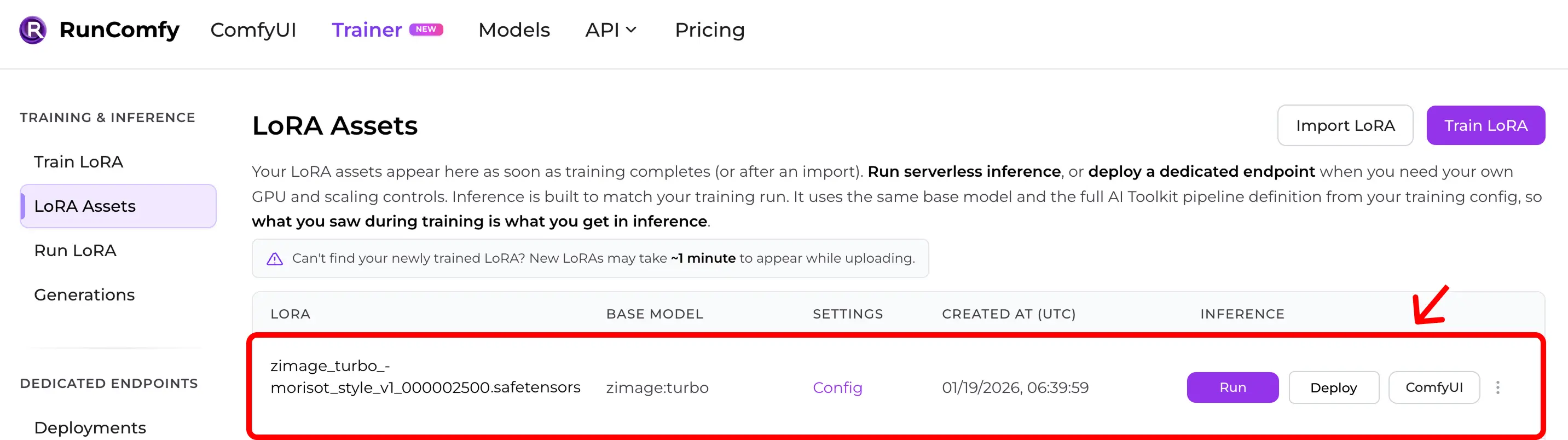
Step 2 — Confirm your LoRA shows up under LoRA Assets
After import (or after a cloud training run completes), your LoRA appears in LoRA Assets.
From there you can click Run (Run LoRA) to start inference immediately (Playground + API).
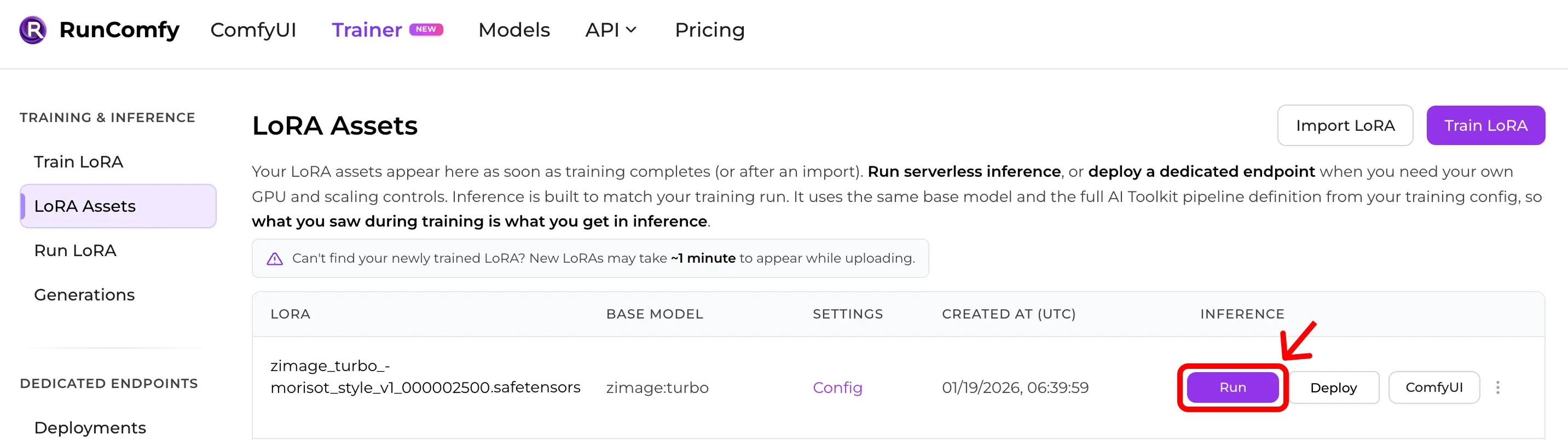
Step 3 — Run LoRA inference instantly
In LoRA Assets, find your LoRA and click Run.
This starts Run LoRA — on‑demand inference that uses the same base model and the same AI Toolkit pipeline definition from your training config, so you get training‑preview parity without rebuilding anything by hand.
You can generate results right away in the Playground, or call the same setup via the API.
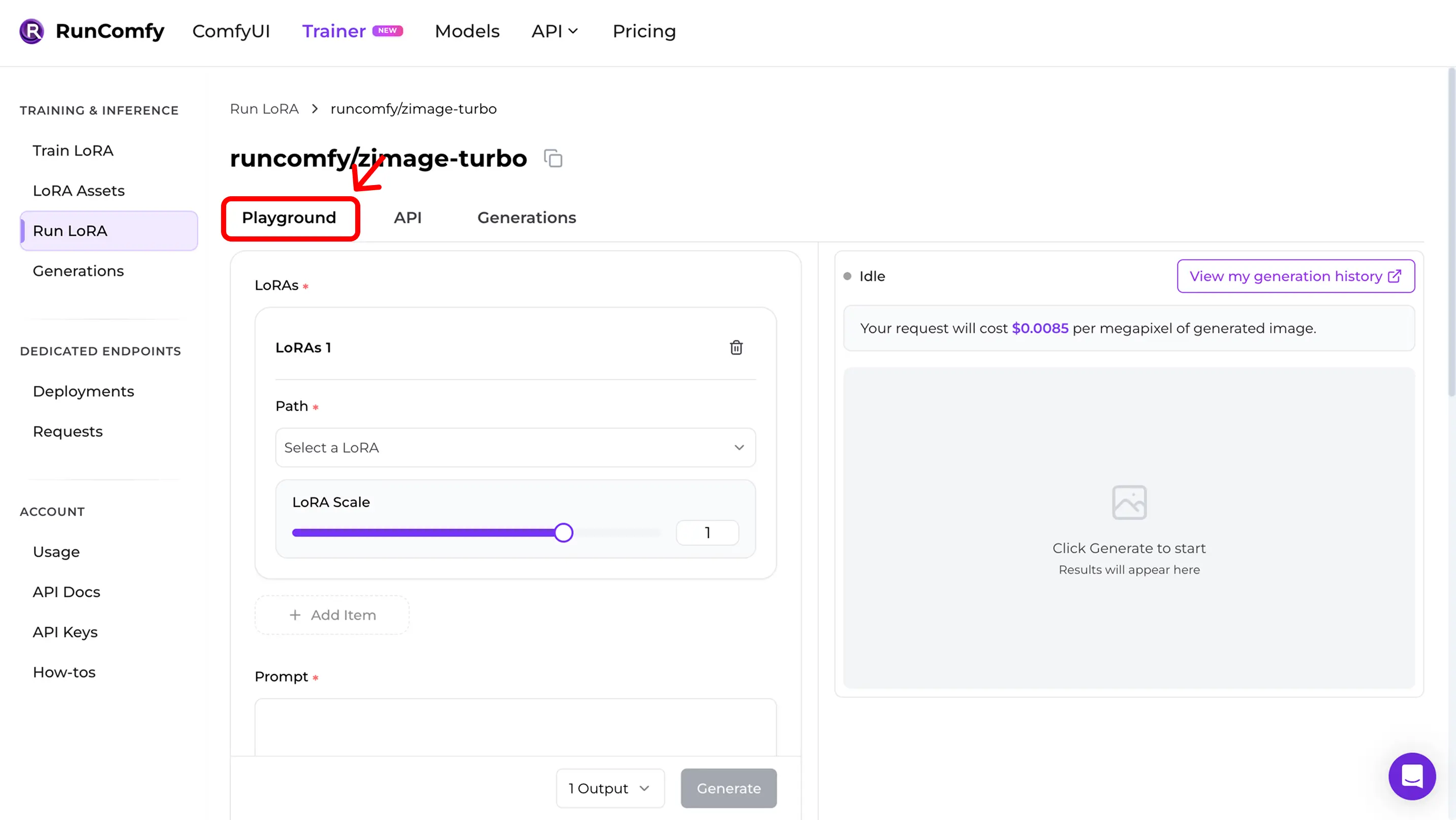
Step 4 — Reproduce training samples in the Playground
After you click Run, you’ll land directly in the Run LoRA Playground.
This is where you validate training–inference parity before you ship:
- Use the same settings you used for training samples (prompt, seed, resolution, steps, guidance, LoRA scale).
- If the results closely match your AI Toolkit training samples, you’ve achieved parity.
- If they drift, jump to the Quick mismatch checklist below and verify the base model + settings.
Step 5 — Use the API in production (async inference)
In Run LoRA, open the API tab. The API is asynchronous:
- submit an inference request
- monitor status
- retrieve results
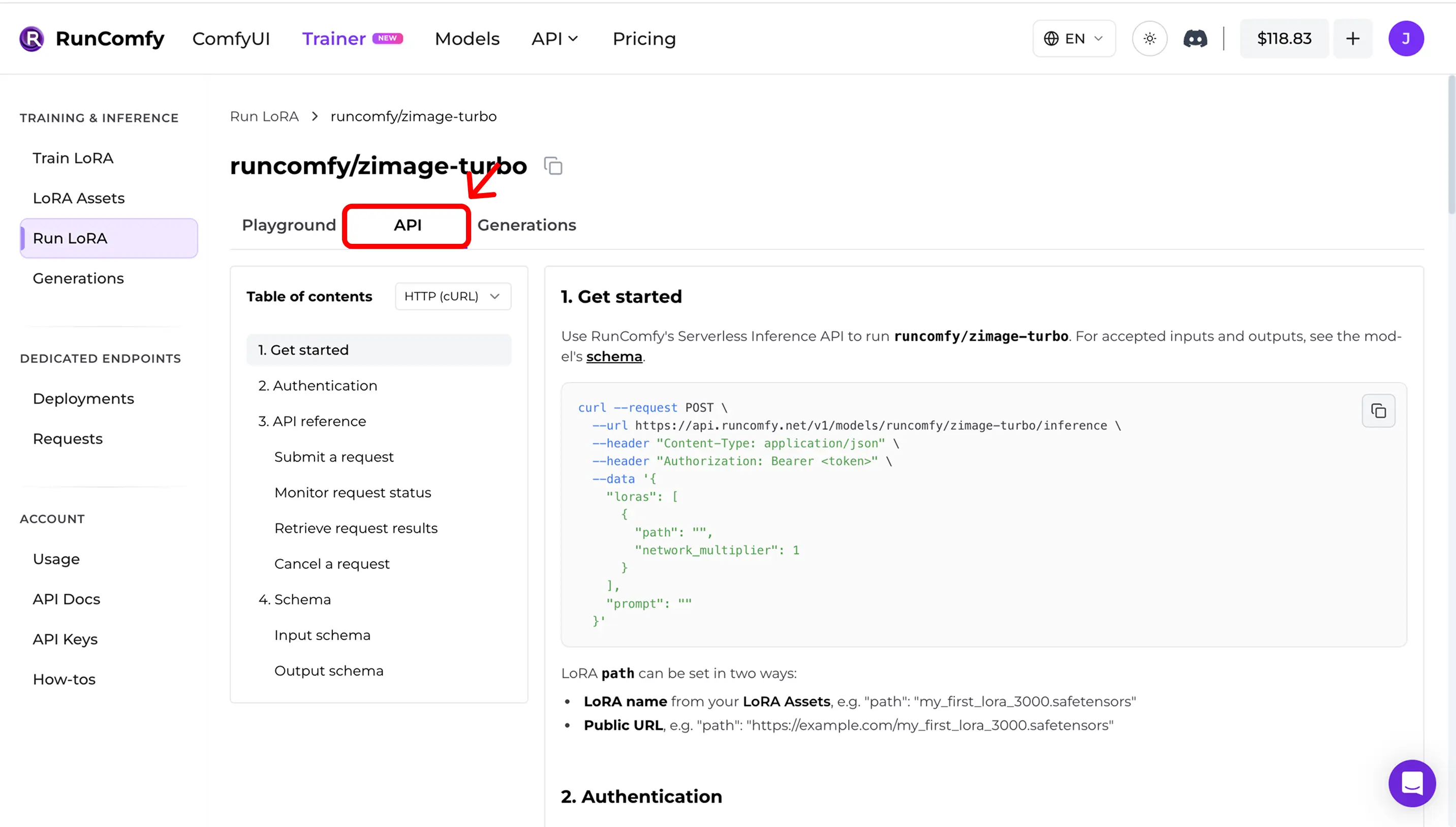
Copy the exact URLs and request shape from the dashboard (and the request schema link).
Example (illustrative — use your own model_id, LoRA path, and API key):
curl --request POST \
--url "https://model-api.runcomfy.net/v1/models/<MODEL_ID>" \
--header "Authorization: Bearer <YOUR_API_KEY>" \
--header "Content-Type: application/json" \
--data '{
"prompt": "a studio portrait photo, cinematic lighting",
"lora": {
"path": "<YOUR_LORA_NAME_OR_URL>"
}
}'API docs: RunComfy Model API (see also LoRA inputs (Trainer))
Quick mismatch checklist
When inference doesn’t match training samples, check:
1) Exact base model (repo + variant)
2) Width/height after snapping to the model’s divisor
3) Steps + guidance + scheduler semantics
4) LoRA application mode (adapter vs fuse/merge)
5) For edit / I2V: correct control image inputs
6) Runtime drift (Diffusers / ComfyUI versions)
Open-source reference implementation
Looking to run inference in ComfyUI and keep results consistent with your AI Toolkit training samples / previews?
See: AI Toolkit LoRA in ComfyUI: Parity Workflows
If you want to audit or self-host the inference logic, see: Open-source AI Toolkit inference code: runcomfy-com/ai-toolkit-inference
FAQ
Do I need the AI Toolkit training config file (YAML) to import?
It’s strongly recommended. Without the training config file, you can still pick a base model manually, but you lose automatic matching of model‑specific inference defaults.
Can I import a LoRA trained outside RunComfy?
Yes. If it was trained with AI Toolkit, import the *.safetensors and the training config file (YAML), then run inference the same way (Run LoRA).
What does “Run LoRA” mean here?
Run LoRA is on‑demand inference (Playground + API) that runs a specific LoRA on its base model without deploying a dedicated endpoint. Billing is per request.
Ready to start training?